Comportamento delle citazioni dell'IA nei vari modelli: dati raccolti da 17,2 milioni di citazioni
Ogni modello di IA utilizza criteri e fonti di citazione diversi, un aspetto molto più rilevante di quanto la maggior parte delle aziende immagini.
Sintesi
Quando i consumatori chiedono a un modello di IA informazioni su un'azienda, la risposta che ottengono dipende molto dal modello a cui si rivolgono. Non perché i modelli “sappiano” cose diverse, ma perché attingono a fonti differenti, con ritmi diversi e secondo dinamiche che cambiano da settore a settore.
La nostra analisi di 17,2 milioni di citazioni dell'IA distinte nel quarto trimestre del 2025 rivela che il comportamento delle citazioni segue schemi prevedibili e specifici per ciascun modello. Questa ricerca si basa su un precedente studio del 2025, in cui abbiamo analizzato 6,9 milioni di citazioni e sviluppato il nostro framework di analisi basato sul contesto e sulla localizzazione.
Tre risultati sono particolarmente significativi:
-
I modelli di citazione variano più all’interno dei singoli settori che tra un settore e l’altro. Ristoranti e negozi di specialità gastronomiche e bar appartengono tutti al settore alimentare, ma presentano profili di citazione significativamente diversi. Un’analisi basata esclusivamente sul settore rischia quindi di non cogliere queste differenze.
-
Claude si affida molto di più ai contenuti generati dagli utenti rispetto ad altri modelli. Le citazioni a controllo limitato (recensioni, social media) compaiono con una frequenza da 2 a 4 volte superiore rispetto ai modelli concorrenti, in tutti e sette i settori analizzati. Non si tratta di un’anomalia legata a una singola categoria: è una tendenza costante.
-
SearchGPT adotta un approccio molto diverso quando si tratta di siti web di hotel. Nel 38,1% dei casi cita i siti ufficiali delle strutture, mentre gli altri modelli si collocano tra il 16,7% e il 22,4%. È la divergenza più marcata osservata per un singolo modello in qualsiasi settore analizzato.
L'implicazione pratica è che non esiste una strategia unica di "ottimizzazione dell'IA". Il mix di fonti che rende visibile un brand su Gemini non è lo stesso mix che lo rende visibile su Claude. Le aziende che considerano la ricerca tramite IA come un singolo blocco stanno ottimizzando per una media inesistente.
Introduzione
Il nostro recente studio "L'ascesa degli archetipi della ricerca basata sull?'IA", un’indagine internazionale condotta su 2237 consumatori tra Stati Uniti, Regno Unito, Francia e Germania, ha rilevato che il 75% degli utenti utilizza oggi strumenti di IA più di quanto facesse un anno fa, e che quasi la metà li usa quotidianamente per le ricerche online.
Questo cambiamento è importante perché la ricerca tramite IA funziona in modo diverso rispetto alla ricerca tradizionale. Nella ricerca tradizionale, i brand competono per il posizionamento su una pagina di risultati. Nella ricerca tramite IA, il modello sintetizza una risposta e ne cita le fonti. La visibilità non dipende più dal posizionamento in classifica, ma dall’essere citati. E come dimostra questa ricerca, modelli diversi citano fonti diverse.
Questo crea un problema che la maggior parte delle aziende non ha ancora pienamente compreso. Un brand potrebbe avere un'eccellente visibilità su Gemini (che si basa molto sui siti web proprietari) ed essere quasi invisibile su Claude (che attinge maggiormente alle recensioni e ai contenuti social). La "strategia per la ricerca IA" di un brand può funzionare perfettamente con un modello e rivelarsi inefficace con un altro, senza che l’azienda abbia modo di accorgersene in assenza di dati specifici per ciascun modello.
Questa ricerca analizza come i quattro principali modelli di IA selezionano le proprie fonti, quali schemi emergono in sette settori e decine di industrie, e dove le differenze tra i modelli sono sufficientemente rilevanti da fare la differenza.

Metodologia
Raccolta dei dati sulle citazioni
Questa analisi prende in esame 17,2 milioni di citazioni dell'IA distinte raccolte a livello globale durante il quarto trimestre del 2025 e relative a quattro dei principali modelli di IA. I dati sono stati raccolti utilizzando la piattaforma Yext Scout.
Le query sono state strutturate per testare quattro quadranti di intento: con brand oggettivo, con brand soggettivo, senza brand oggettivo e senza brand soggettivo. I dati sono stati raccolti a livello di sede anziché a livello di brand, cogliendo le variazioni geografiche e contestuali che gli studi nazionali a livello di brand non riescono a rilevare.
Struttura delle categorie di controllo
Ogni fonte di citazione è stata ricavata ponendo a ciascun modello quattro tipi di domande basate sul nostro framework di contesto geografico.
| Livello di controllo | Definizione | Esempi |
|---|---|---|
| Controllo totale | Contenuti interamente creati e gestiti dall'azienda | Siti web ufficiali, blog di proprietà, redazioni aziendali |
| Controllo parziale | Piattaforme di terze parti dove il brand può gestire il proprio profilo | Profilo dell'attività su Google, MapQuest, TripAdvisor, Zocdoc |
| Controllo limitato | Piattaforme generate dagli utenti con partecipazione del brand | Google Reviews, Yelp, Facebook, social media |
| Nessun controllo | Fonti indipendenti senza contributi aziendali | Notizie, Reddit, forum, pubblicazioni indipendenti |
La suddivisione aggregata di tutte le citazioni:
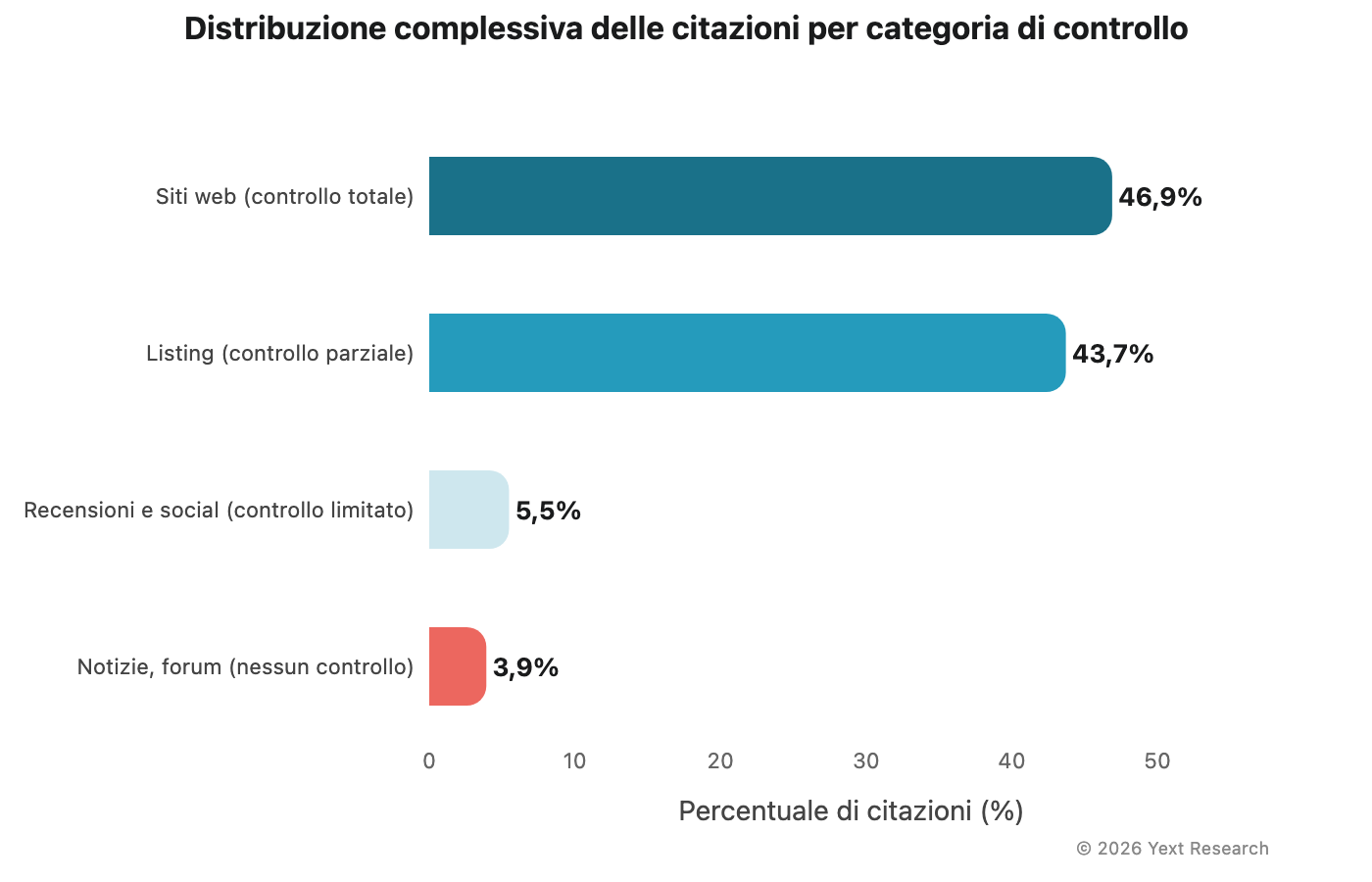
Un dato salta all'occhio: i listing rappresentano la quota maggiore di URL distinti (54,53%), ma i siti web generano molte più occorrenze di citazione per singolo URL (4,31 volte contro 2,46). I modelli di IA fanno riferimento ai contenuti proprietari più frequentemente di quanto lo facciano per qualsiasi singolo listing.
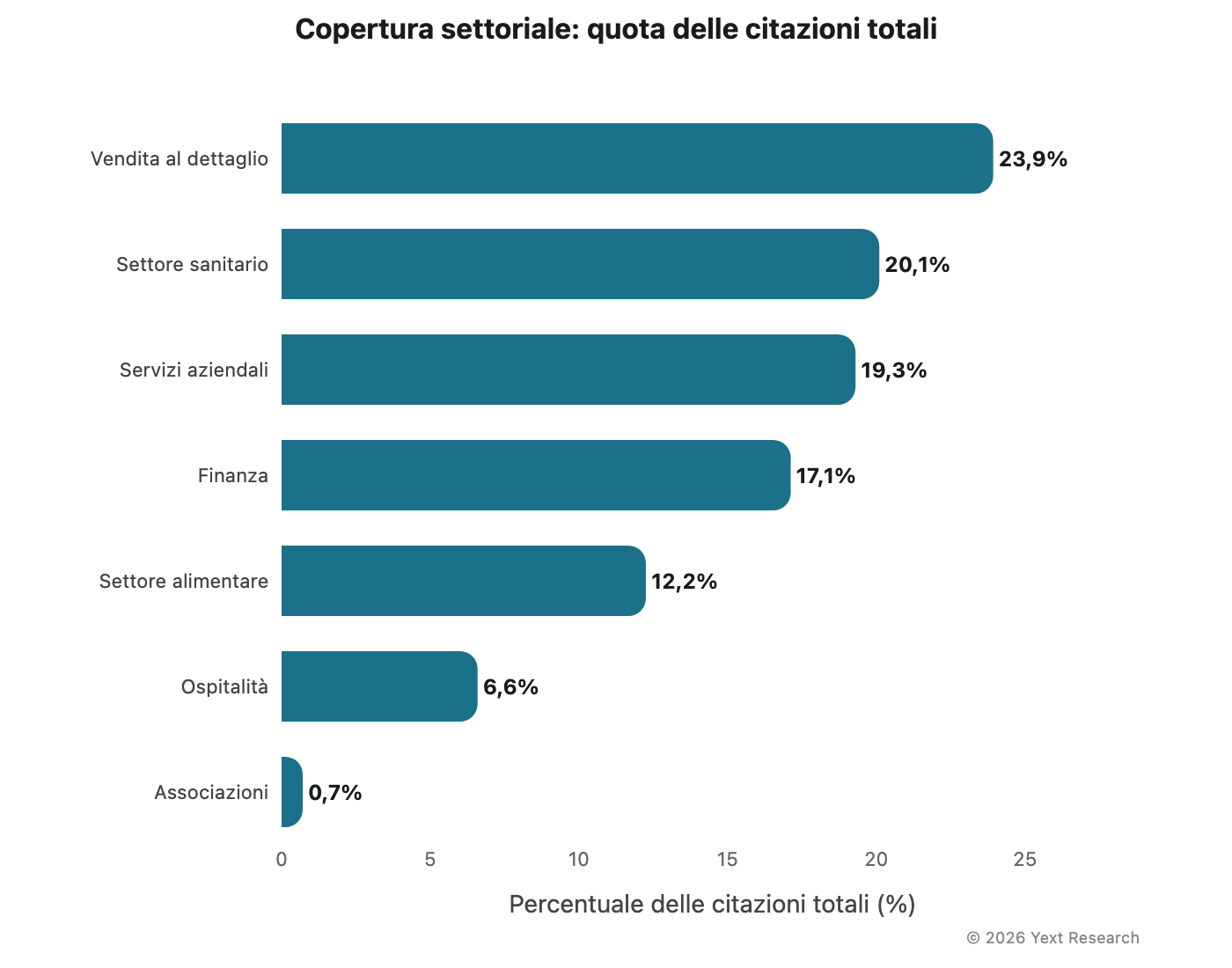
Copertura settoriale
L'analisi comprende sette settori:
Risultati
Figura 1: tendenze di citazione a livello di modello
Ogni modello di IA dimostra preferenze di citazione coerenti che persistono in tutti i settori, anche se l'entità varia.
Gemini mostra la preferenza più marcata per le fonti a controllo totale nella maggior parte dei settori, con percentuali che vanno dal 22,4% (ospitalità) al 54,0% (associazioni). Questo probabilmente riflette l'integrazione da parte di Google dei segnali E-E-A-T nella logica di citazione di Gemini, di cui parleremo ulteriormente nella sezione sull'architettura.
Claude mostra costantemente un'elevata dipendenza da fonti a controllo limitato, variando dal 6,3% (associazioni) al 24,4% (cibo e bevande). Si tratta di un valore da due a quattro volte superiore rispetto ad altri modelli nella maggior parte dei settori.
Perplexity è il modello che mostra il comportamento più uniforme tra le diverse industrie, con una preferenza per le fonti a controllo totale generalmente compresa tra il 37% e il 50% nella maggior parte dei settori. La stabilità sembra integrata nella sua architettura orientata alla ricerca.
SearchGPT è il modello che presenta la maggiore variabilità tra le diverse industrie: la quota di fonti a controllo totale varia dal 28,2% (cibo e bevande) al 43,7% (associazioni), con un picco significativo nel settore dell’ospitalità al 38,1%.
Figura 2: l’anomalia di SearchGPT nel settore dell’ospitalità
Il settore dell'ospitalità presenta la divergenza di modello più marcata nel dataset:
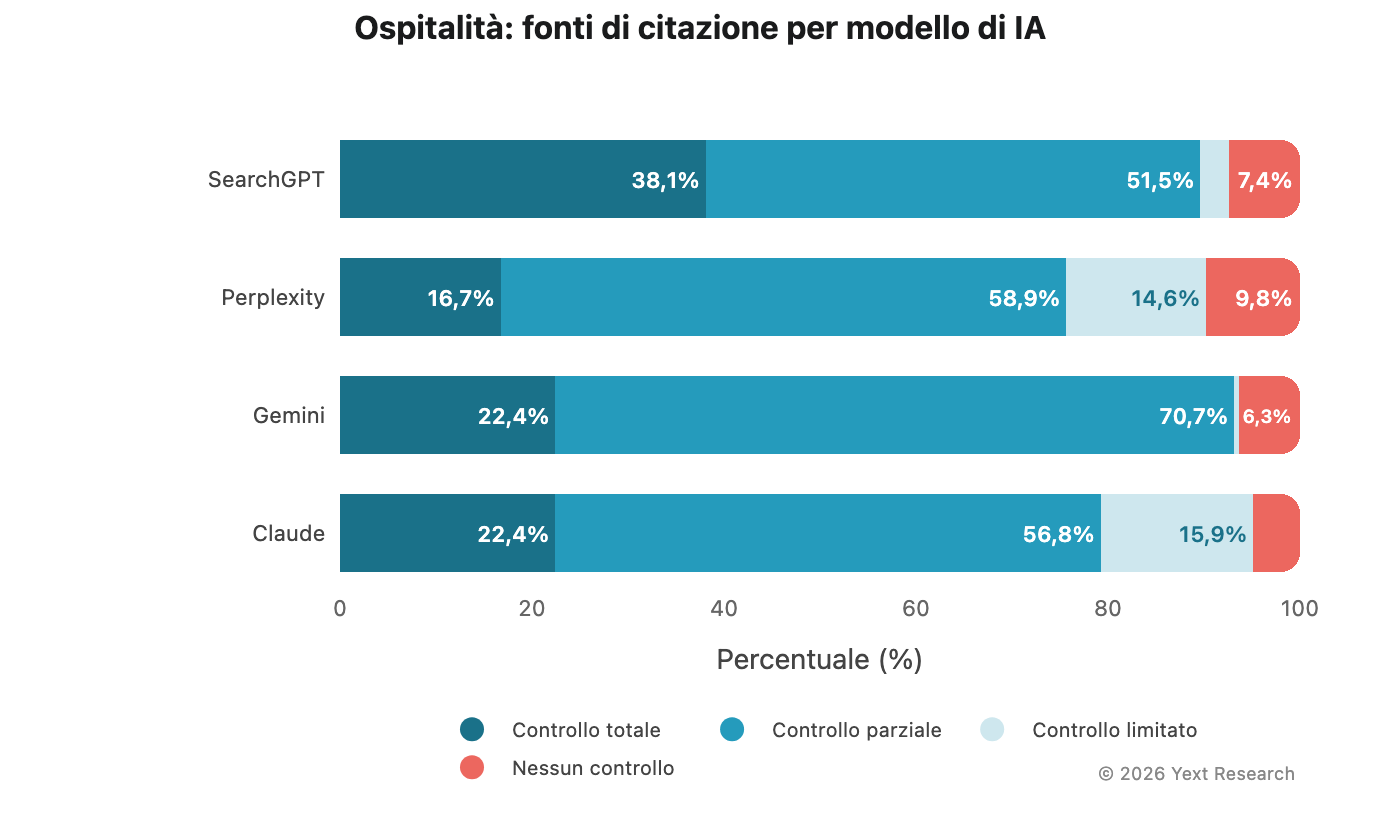
La quota del 38,1% di fonti a controllo totale registrata da SearchGPT è circa il doppio rispetto a quella degli altri modelli in questo settore. La tendenza si conferma a livello di settore per l'ospitalità.
Panoramica del settore:
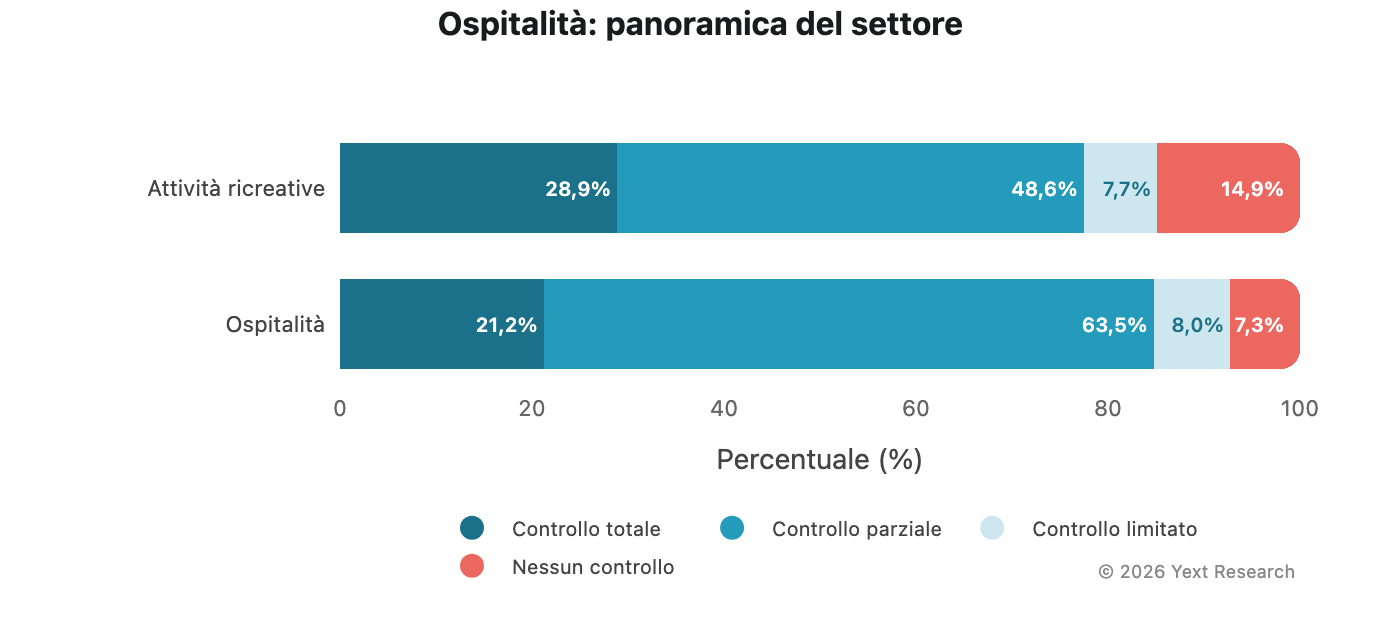
La categoria "attività ricreative" mostra una maggiore preferenza per le fonti a controllo totale (28,9%) e una quota più elevata di fonti con nessun controllo diretto (14,9%), a indicare che attrazioni e attività si basano maggiormente su recensioni indipendenti e pubblicazioni di viaggio.
Perché SearchGPT favorisce così tanto i siti web degli hotel? I dati non ce lo dicono. Tra le possibili spiegazioni rientrano differenze nella composizione dei dati di addestramento, nella configurazione del sistema di raccolta o nella valutazione esplicita verso fonti del brand nelle query di viaggio. Si tratta di una domanda senza risposta certa.
Figura 3: servizi aziendali
I servizi aziendali mostrano una chiara differenziazione dei modelli, con Gemini in testa per le fonti a controllo totale:
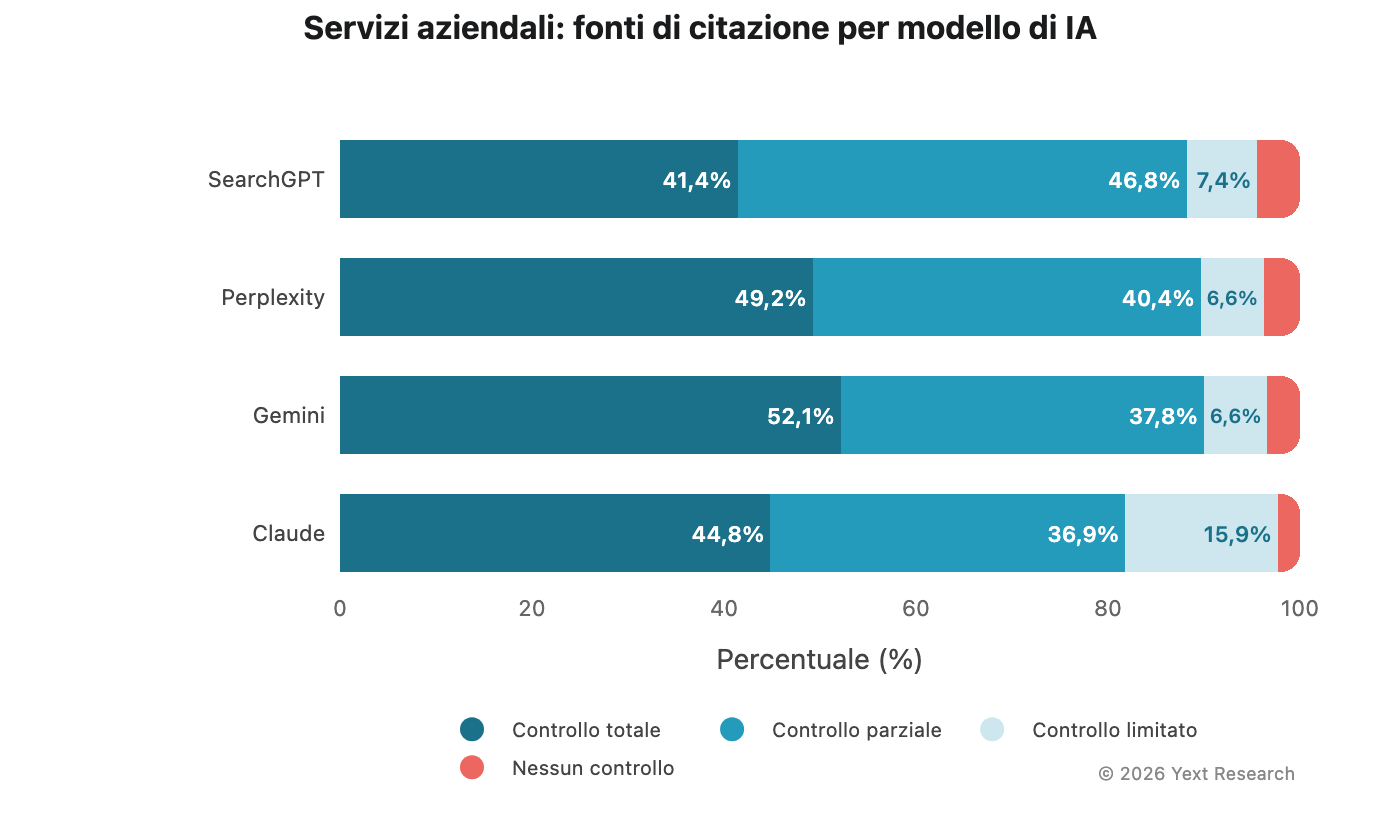
Mentre, la dipendenza da fonti a controllo limitato di Claude (15,89%) è più del doppio di qualsiasi altro modello.
Panoramica del settore:
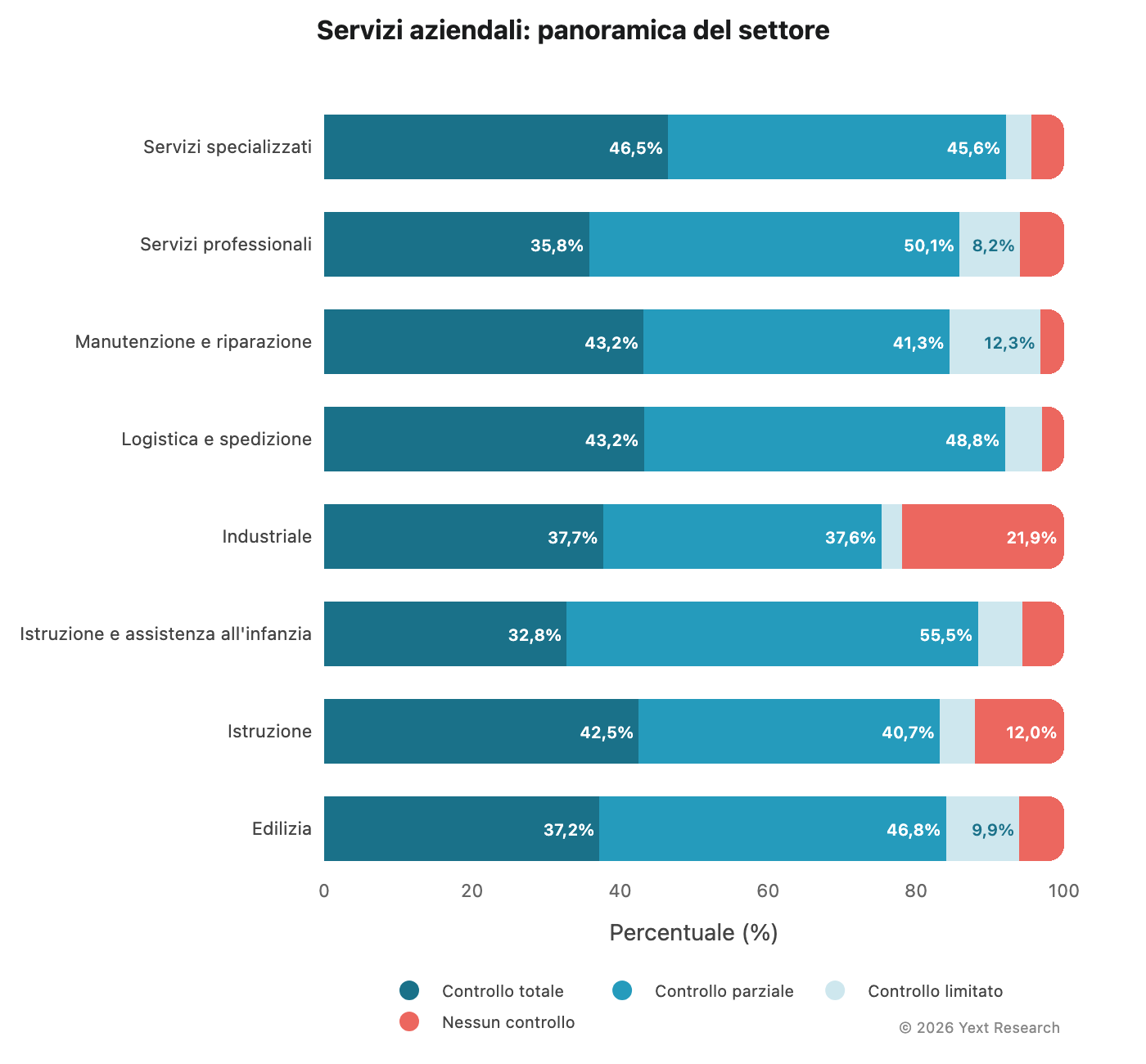
La categoria manutenzione e riparazione si distingue per una quota più elevata di fonti a controllo limitato (12,31%), un dato coerente con le dinamiche del comparto: piattaforme di recensioni come Yelp, Angi e HomeAdvisor svolgono un ruolo centrale nel modo in cui le persone trovano idraulici ed elettricisti.
Figura 4: finanza
Il settore finanziario mostra una forte preferenza per fonti a controllo parziale sui diversi modelli, guidata dagli archivi finanziari e dalle piattaforme di confronto:
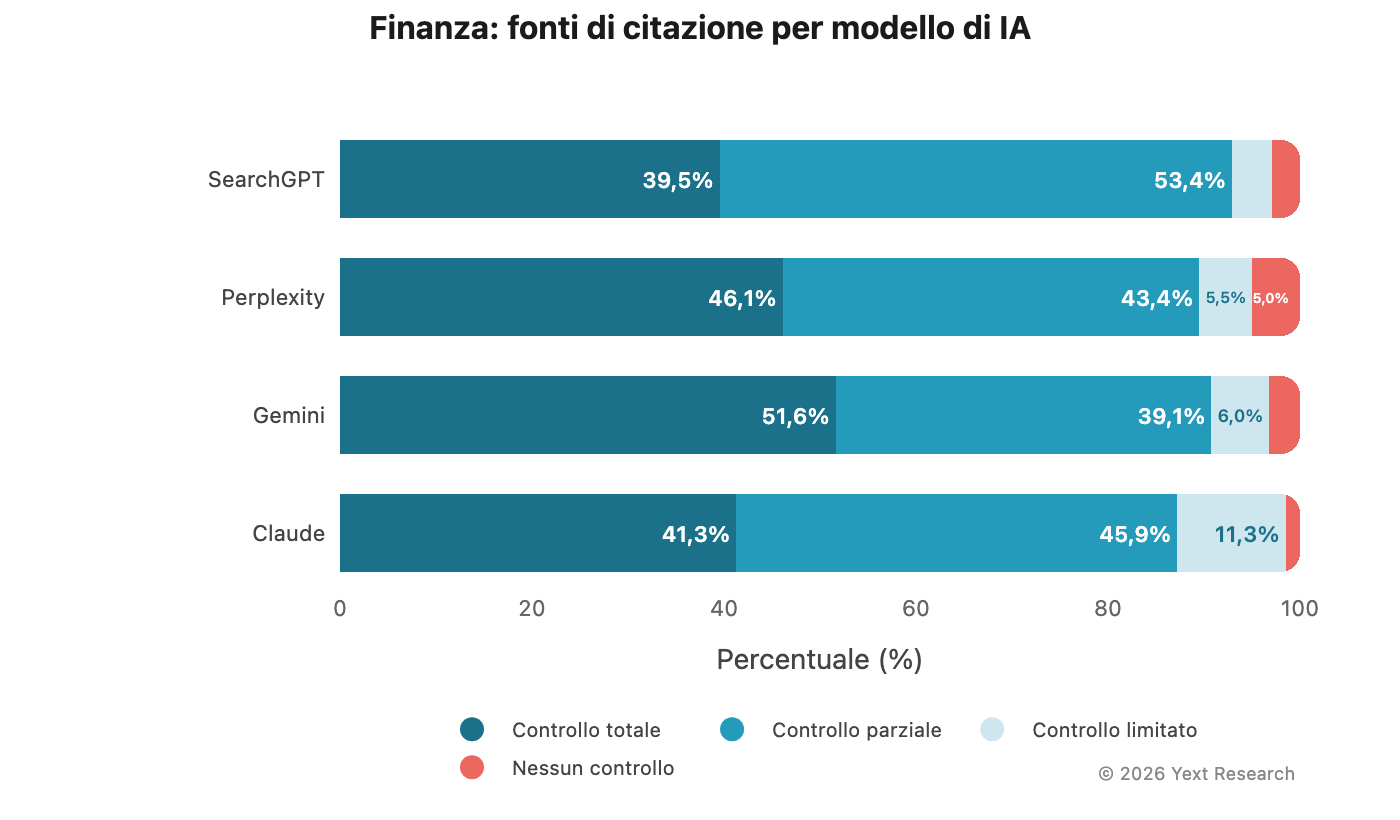
La quota del 51,62% di fonti a controllo totale registrata da Gemini è la più alta in questo settore, in linea con la sua generale preferenza per fonti autorevoli e proprietarie.
Panoramica del settore:
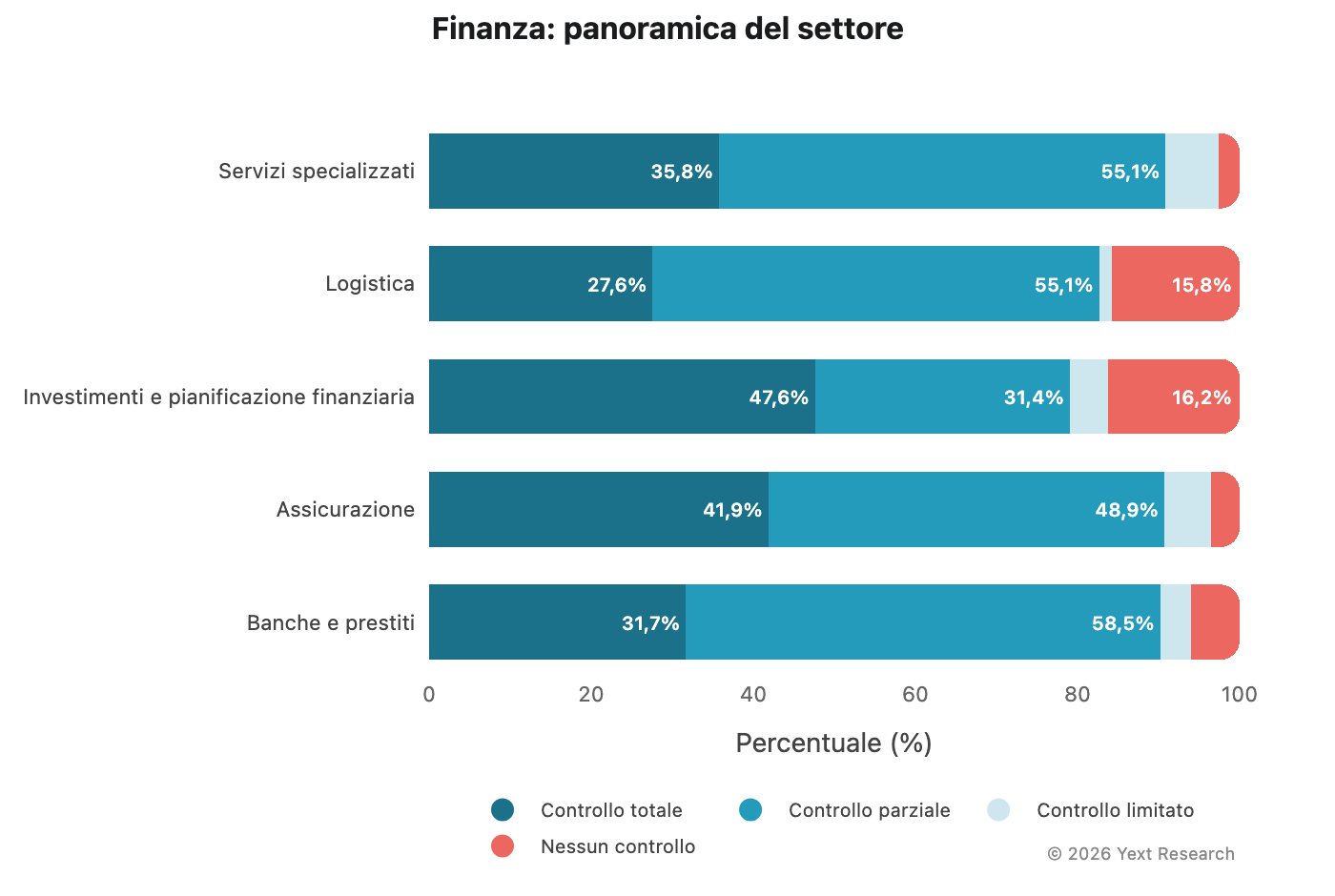
Il settore bancario registra la più alta preferenza per le fonti a controllo parziale (58,52%), a indicare un forte ricorso ad archivi finanziari e siti di comparazione. Le categorie di investimenti e pianificazione finanziaria e della logistica mostrano una percentuale elevata per fonti con nessun controllo (16,19% e 15,78%), suggerendo una maggiore dipendenza da notizie e pubblicazioni finanziarie indipendenti. (Nota: la categoria di investimenti e pianificazione finanziaria ha solo 315 URL, quindi va interpretato in modo indicativo.)
Figura 5: settore sanitario
Il settore sanitario mostra la divergenza più ristretta tra i modelli di qualsiasi settore:
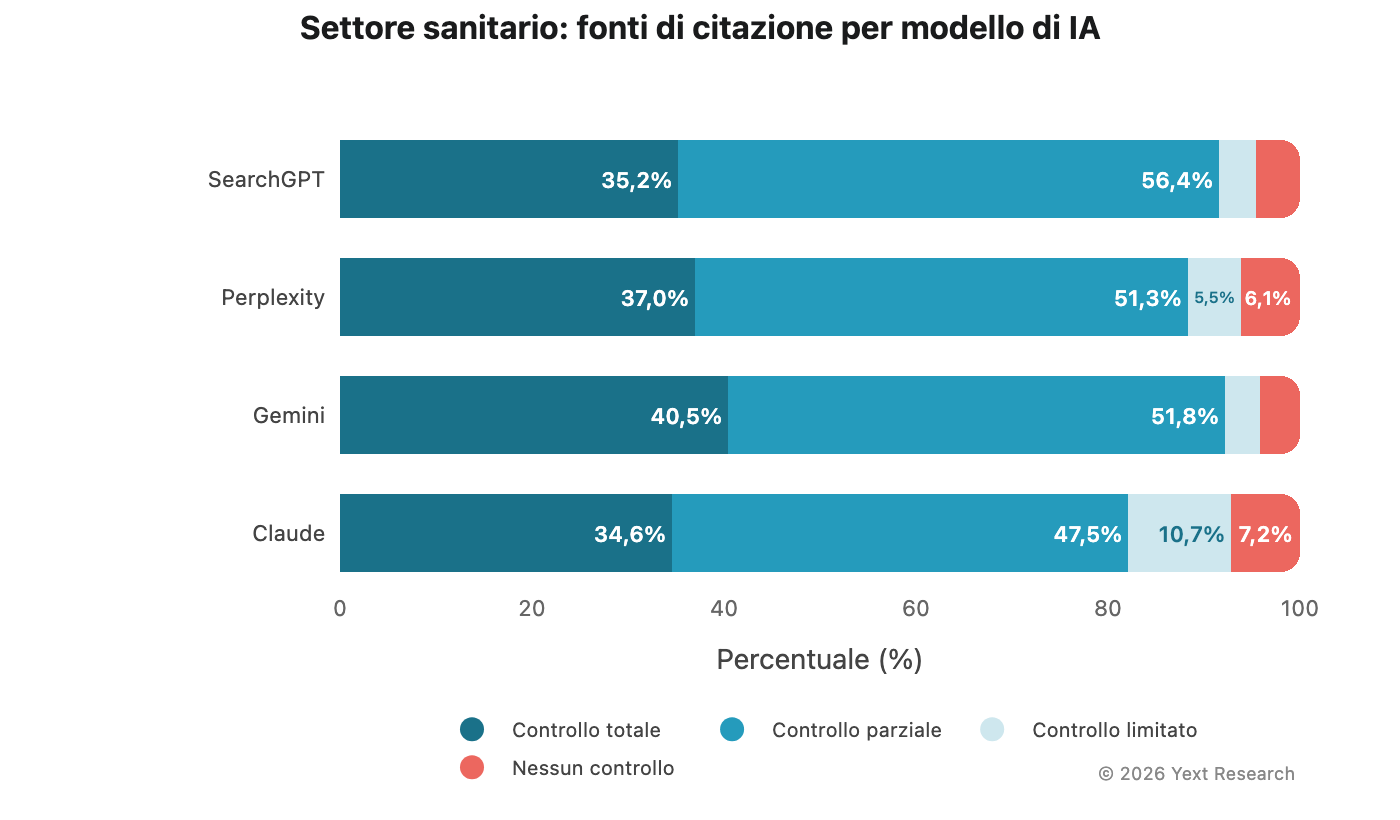
Le fonti a controllo totale variano dal 34,60% (Claude) al 40,45% (Gemini), una differenza minima inferiore a 6 punti percentuali. Si tratta di uno scarto molto contenuto. Nella maggior parte degli altri settori, la differenza è di 10-15 punti percentuali o più. Tutti e quattro i modelli sembrano convergere verso un comportamento di citazione orientato a fonti autorevoli e ricco di directory quando l’argomento è di natura medica.
Questa convergenza merita di essere sottolineata proprio perché è insolita. Potrebbe riflettere una sensibilità condivisa rispetto all’accuratezza delle informazioni mediche, nonostante le diverse architetture dei modelli; oppure potrebbe dipendere dalla struttura stessa delle fonti disponibili in ambito sanitario, dominate da grandi piattaforme directory come Zocdoc e Healthgrades. Probabilmente entrambe le cose.
Panoramica del settore:
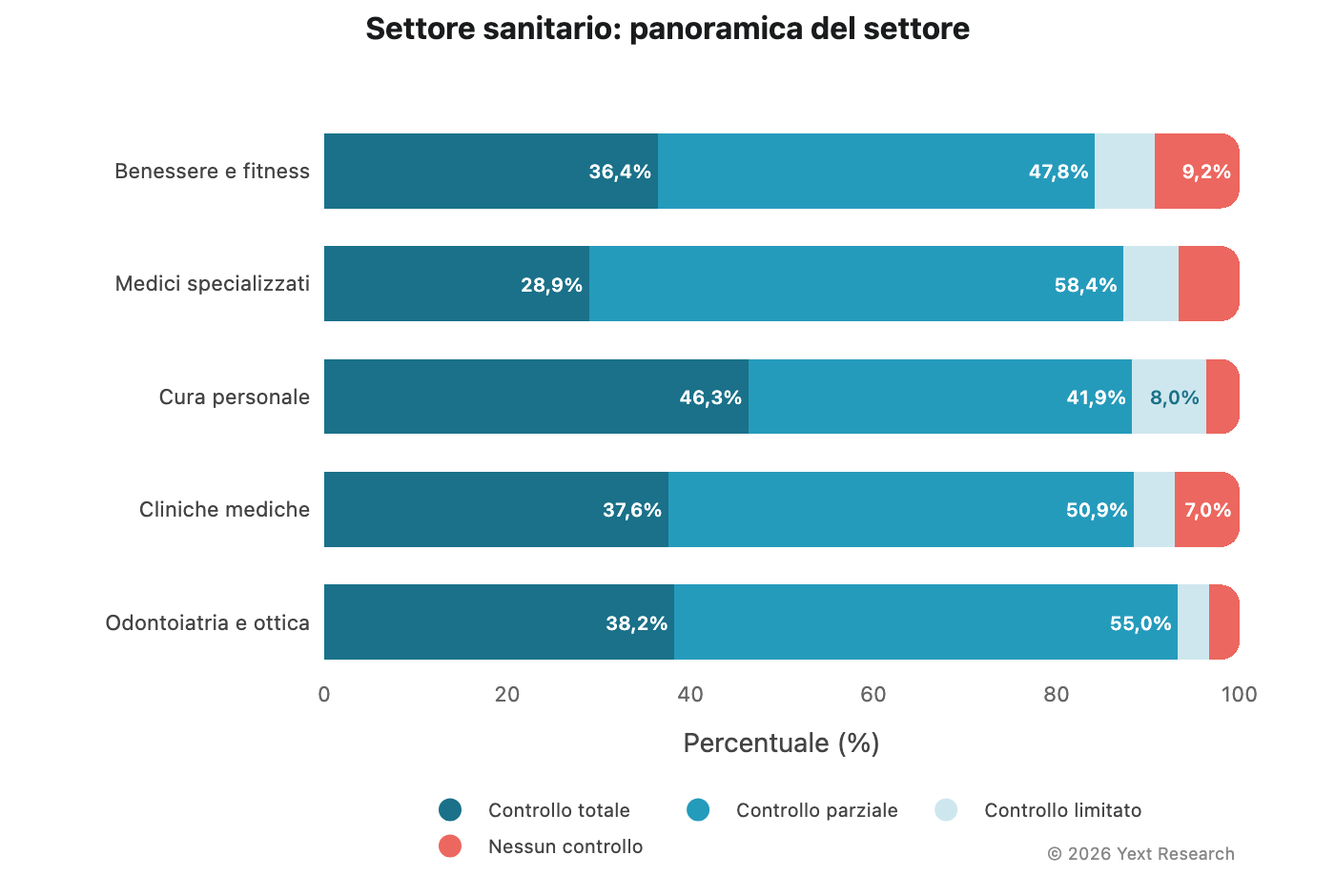
I medici specializzati mostrano il più alto tasso di fonti a controllo parziale (58,39%), a dimostrazione della centralità degli archivi sanitari per la scoperta di specialisti.
Figura 6: settore alimentare
Quello alimentare è il settore in cui la dipendenza da fonti a controllo limitato di Claude è più evidente:
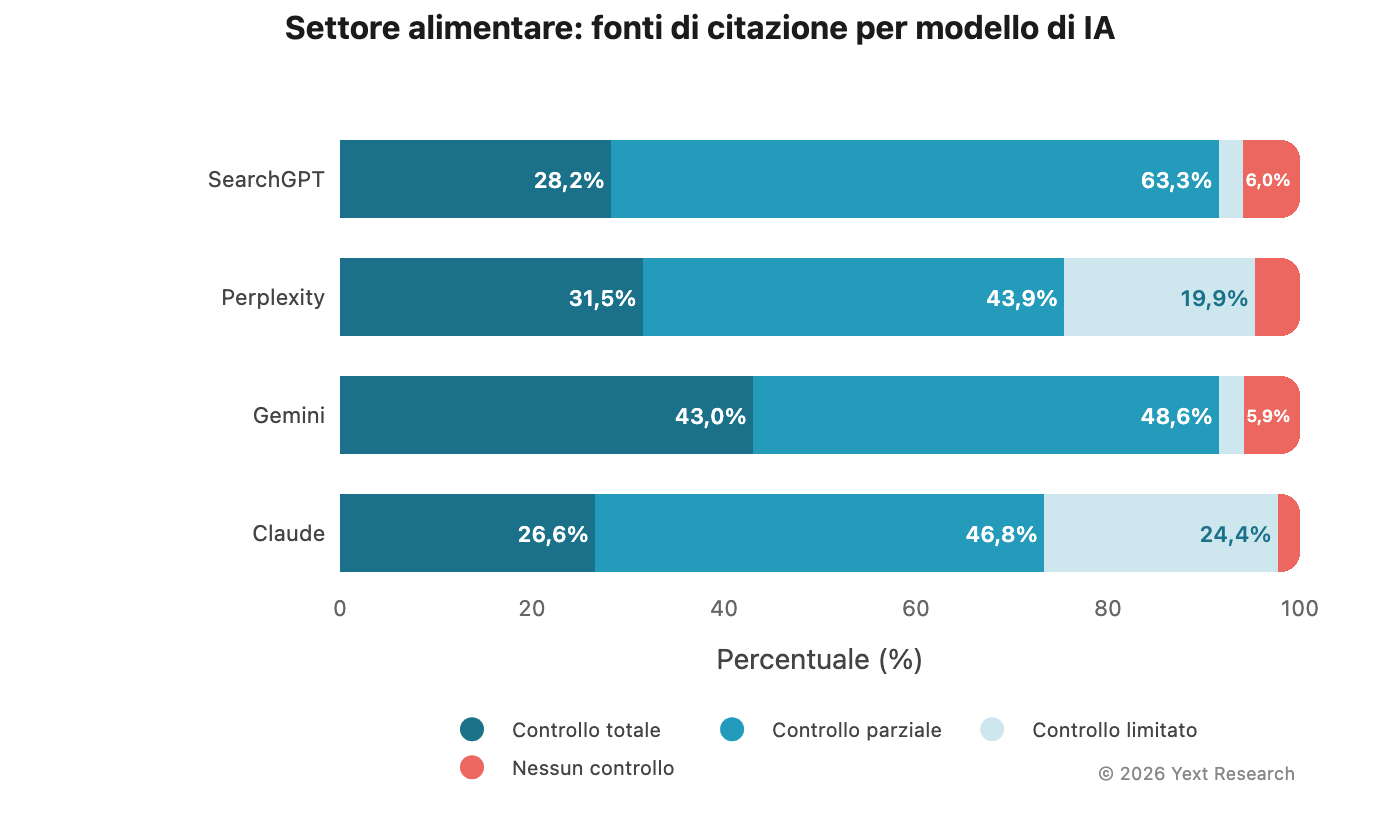
La percentuale di fonti a controllo limitato di Claude (24,35%) è quasi 10 volte superiore a quella di Gemini (2,57%). Chiedi a Claude informazioni su un ristorante e circa una su quattro delle fonti citate sarà una recensione o un post sui social media. Chiedi a Gemini la stessa domanda e quel rapporto scende a uno su quaranta.
Panoramica del settore:
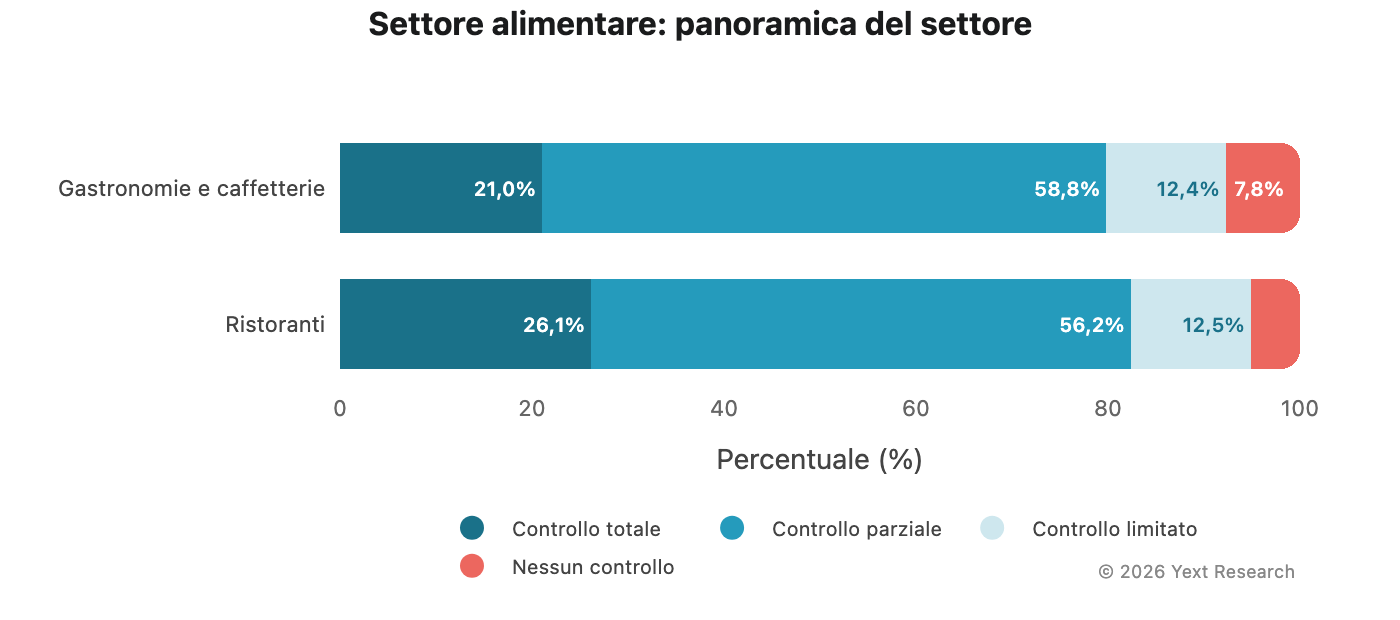
Entrambe le categorie mostrano livelli di controllo limitato simili (circa il 12,5%), ma la categoria che comprende gastronomie e caffetterie mostra una quota più bassa di fonti a controllo totale (21,03% contro 26,15%) e una quota più alta di fonti con nessun controllo diretto (7,75% contro 5,12%), segnalando un maggiore ricorso a food blog e recensioni indipendenti.
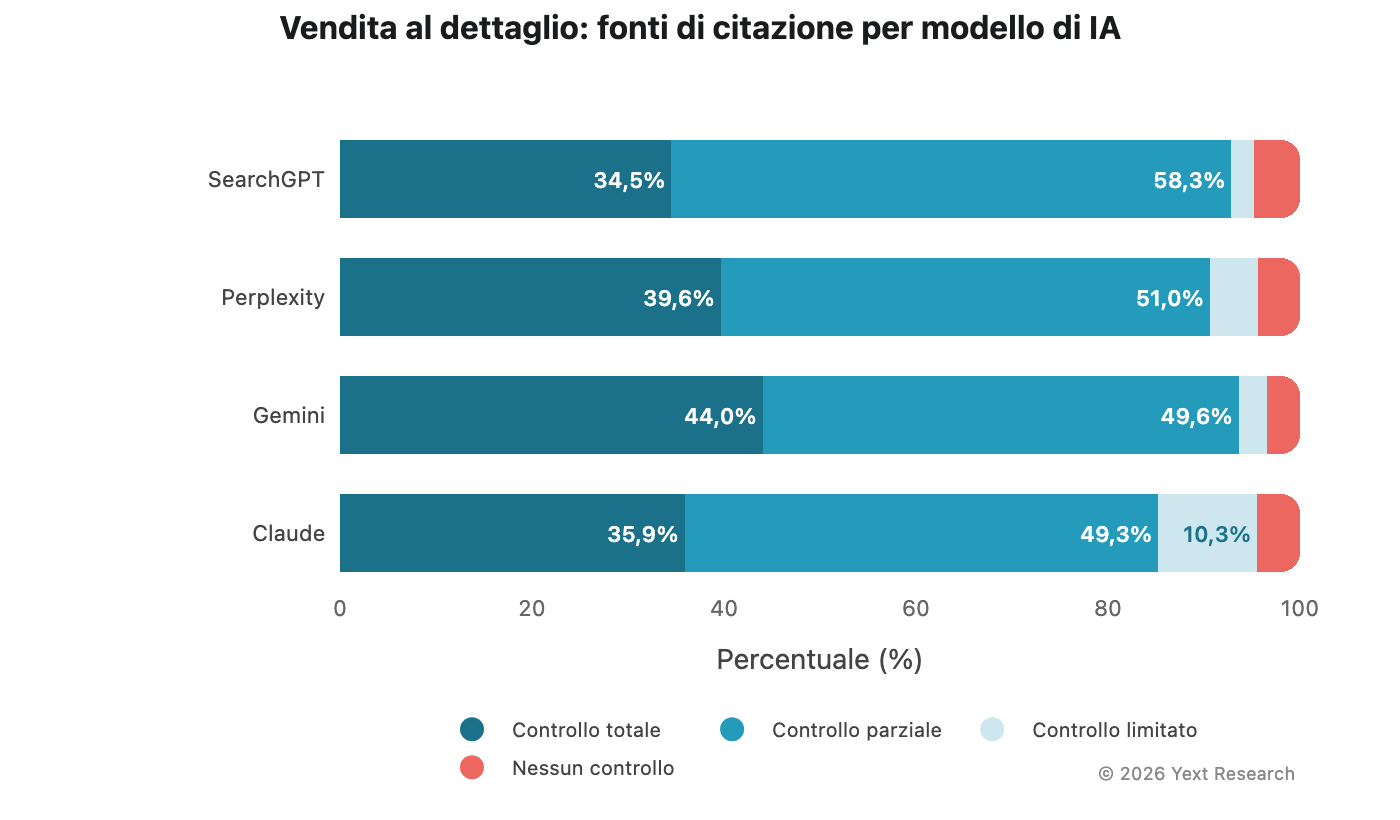
Figura 7: vendita al dettaglio
Il settore della vendita al dettaglio mostra variazioni moderate tra i modelli con una distribuzione delle citazioni relativamente equilibrata:
Panoramica del settore:
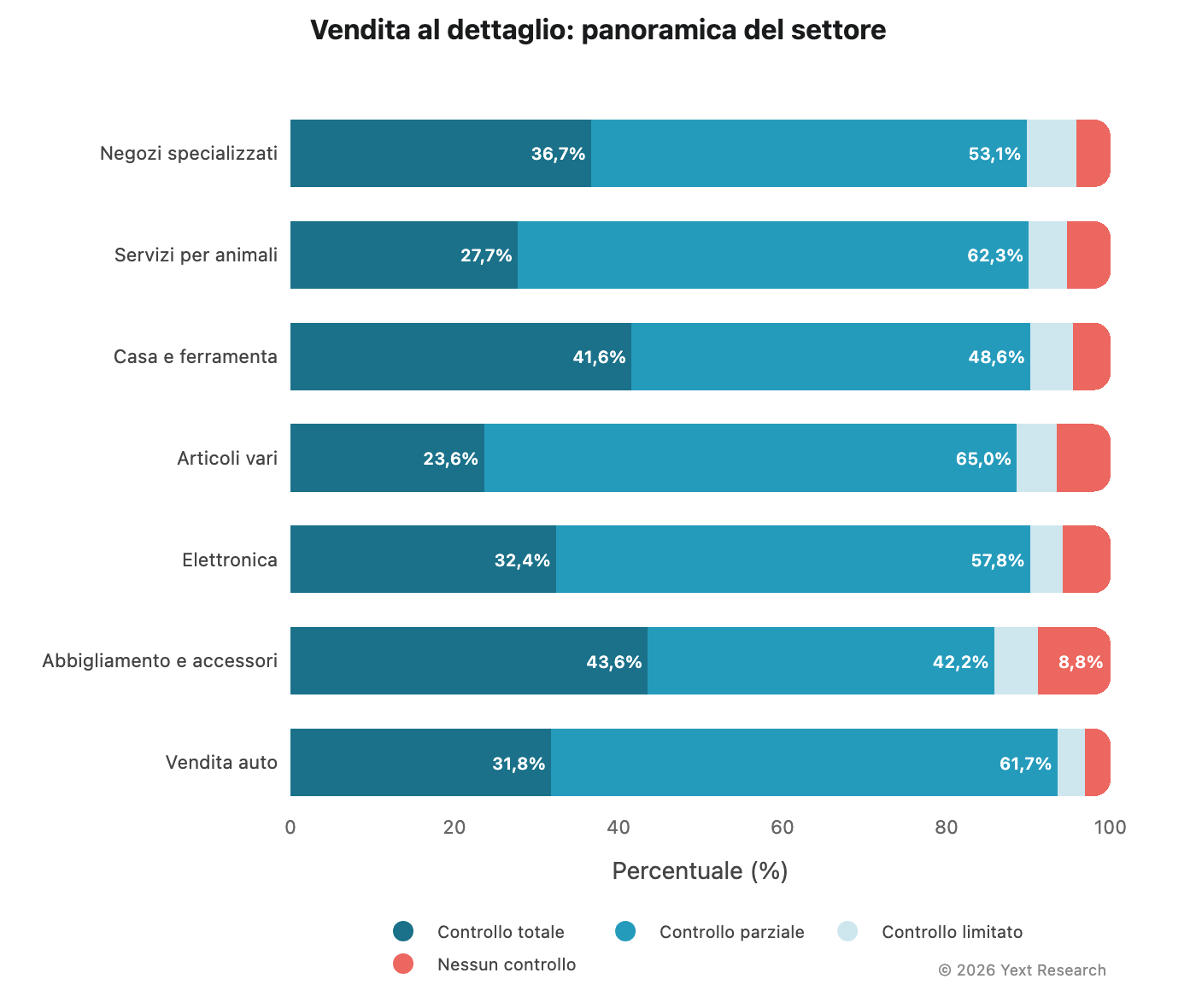
La categoria di articoli registra la quota più alta di fonti a controllo parziale (64,99%) e la più bassa di fonti a controllo totale (23,60%), a indicare un forte affidamento su aggregatori e siti di comparazione. La categoria di abbigliamento e accessori presenta la quota più alta di fonti con nessun controllo diretto (8,82%), probabilmente a testimonianza dell’influenza di riviste di moda e fashion blog.
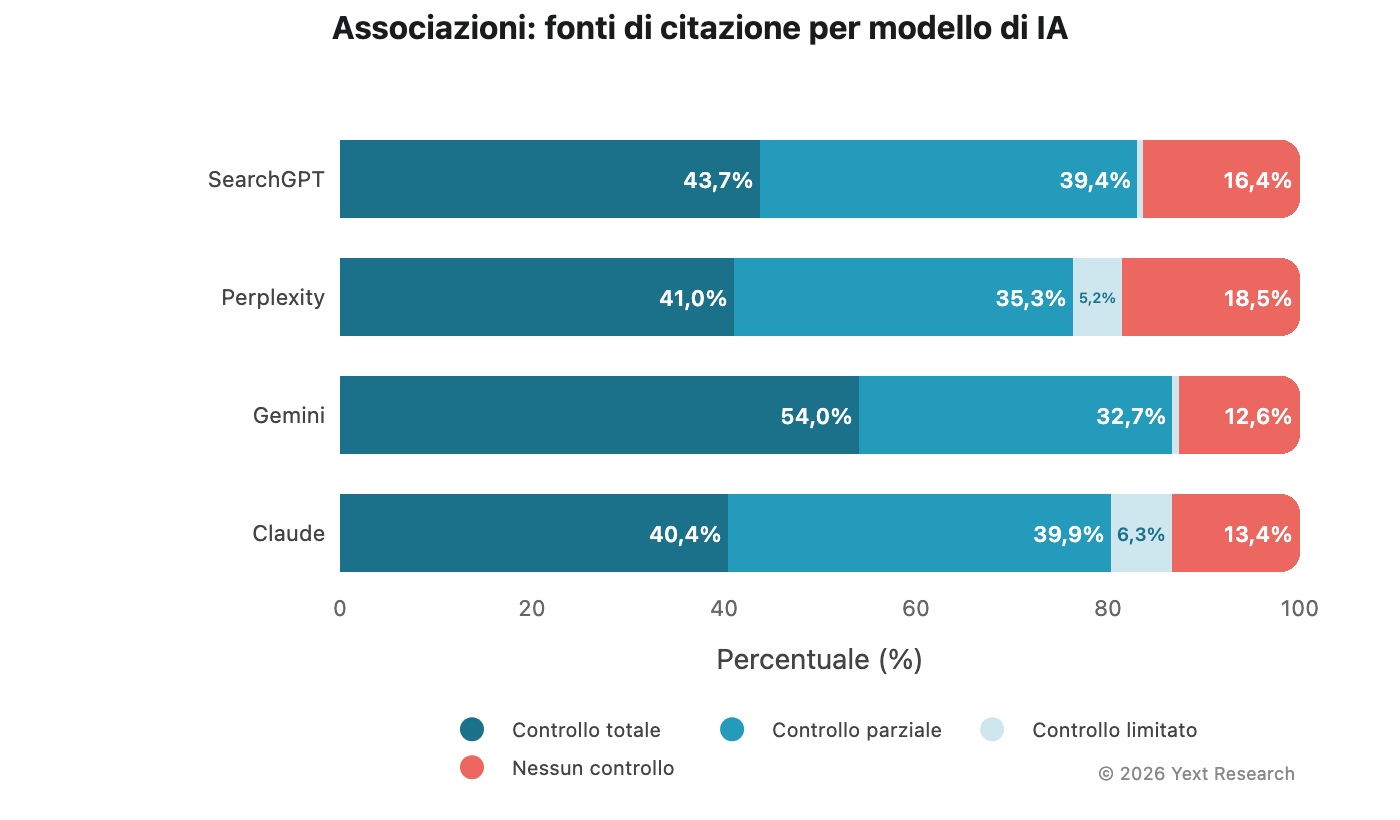
Figura 8: associazioni
Le associazioni (no profit o religiose) mostrano tassi particolarmente elevati di fonti con nessun controllo:
La quota di fonti con nessun controllo diretto varia dal 12,58% (Gemini) al 18,53% (Perplexity), un livello nettamente superiore rispetto agli altri settori. Il motivo è abbastanza intuitivo: le associazioni no profit e religiose sono oggetto di articoli nei notiziari e nelle pubblicazioni locali più di quanto producano contenuti propri facilmente reperibili.
Panoramica del settore:
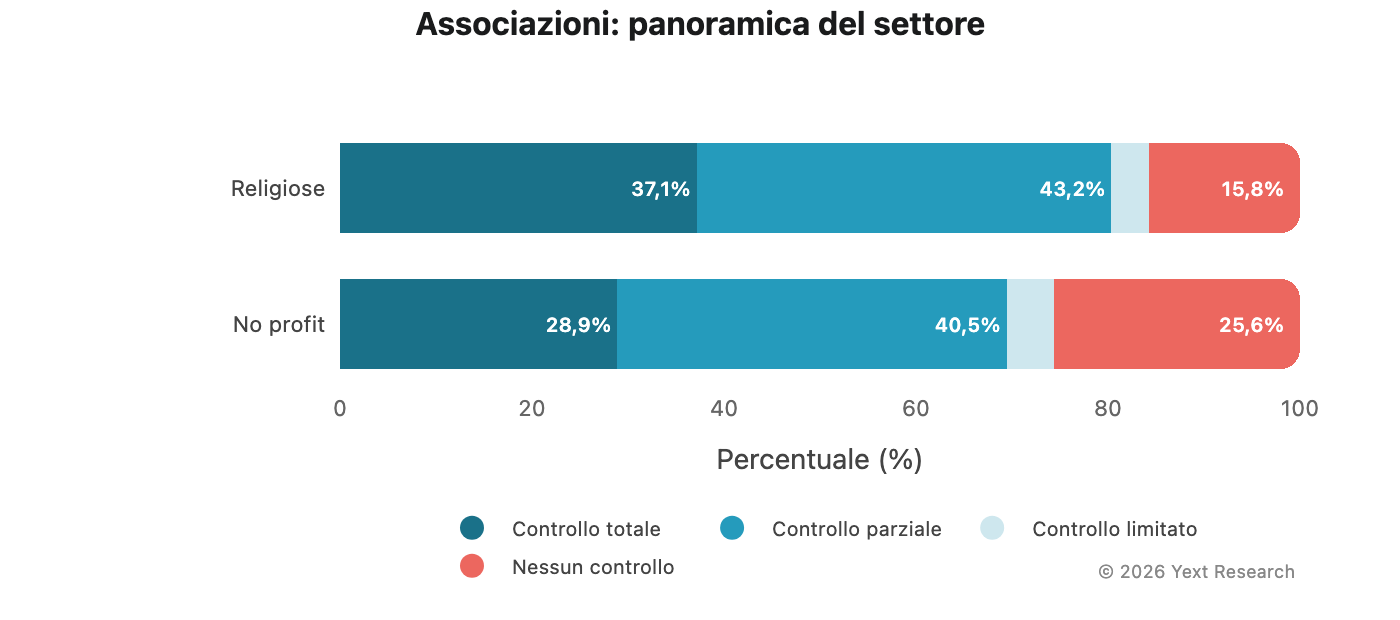
Le associazioni no profit mostrano una percentuale notevole del 25,62% per fonti con nessun controllo. Per queste organizzazioni, la visibilità nella ricerca basata sull'IA è sostanzialmente determinata da ciò che gli altri scrivono su di loro.
Figura 9: dipendenza da fonti a controllo limitato di Claude
L'elevata propensione di Claude per fonti a controllo limitato rappresenta la tendenza più coerente tra i settori nei dati:
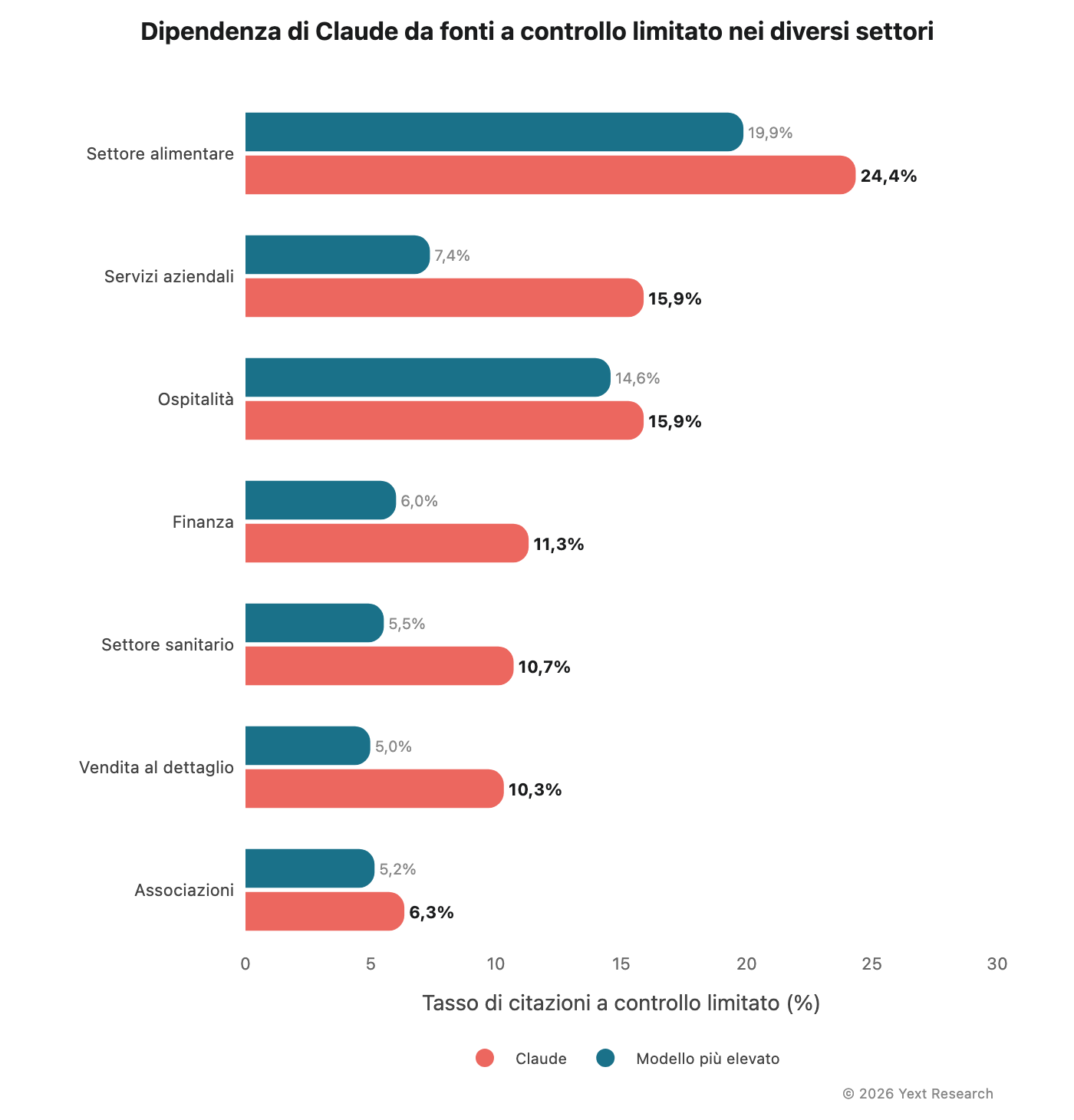
In tutti e sette i settori, Claude è in testa alla classifica per le citazioni da fonti a controllo limitato. Nessun altro modello mostra questo tipo di coerenza direzionale su una singola metrica.
Figura 10: sintesi a livello settoriale
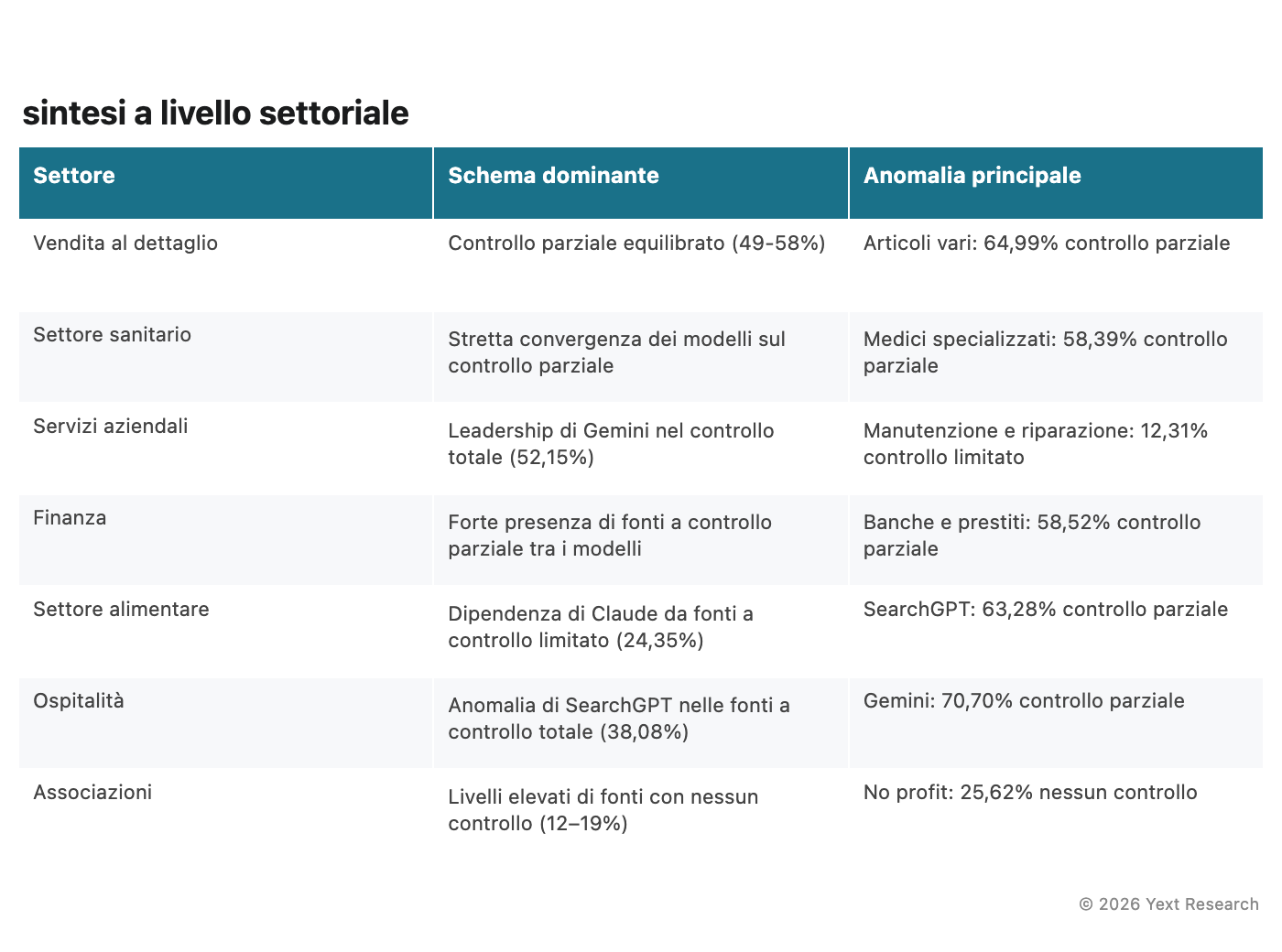
Discussione
Architettura del modello e comportamento delle citazioni
Le tendenze di citazione di questo studio non sono casuali e non sono scelte puramente editoriali dei modelli. Riflettono il modo in cui l'architettura di ciascun modello raccoglie e valuta le fonti. Comprendere queste differenze aiuta a spiegare ciò che osserviamo.
Perplexity (RAG basata sulla ricerca): Perplexity funziona come un motore di ricerca, avviando una ricerca web sul proprio indice per ogni query. La maggior parte delle risposte si basa in larga misura su "passaggi citabili", ovvero contenuti facilmente estraibili e riportabili direttamente come fonte. Questa architettura spiega la coerenza di Perplexity nei vari settori. La raccolta delle informazioni è ottimizzata per la stabilità piuttosto che per l'adattamento in base al contesto.
SearchGPT (RAG con recupero esterno): il modello di base di SearchGPT non ha accesso diretto al web, quindi si basa su un sistema di interrogazione delle fonti esterne che individua i contenuti rilevanti prima di generare la risposta. Non ci sono prove pubblicate che ChatGPT assegni un punteggio interno ai domini in base a fiducia, autorità o E-E-A-T. Qualsiasi comportamento di questo tipo riflette il sistema di raccolta a monte piuttosto che il modello stesso. Questo potrebbe spiegare l’elevata variabilità tra i diversi settori che osserviamo. I modelli di citazione dipendono fortemente da come il livello di raccolta è configurato per i diversi tipi di query.
Gemini (basato sulla ricerca): Gemini fonda le proprie risposte sui risultati di ricerca, e le citazioni derivano da questo processo iniziale, non dai parametri del modello di base. La fonte di riferimento è la Ricerca Google. Ne consegue logicamente che le citazioni ereditano il sistema di posizionamento di Google. Gemini è una sintesi LLM della Ricerca Google, il che significa che per competere per la visibilità in Gemini è ancora necessario eccellere nell'ottimizzazione della ricerca tradizionale.
Claude (IA costituzionale): Claude utilizza la RAG come altri modelli, ma differisce nel modo in cui valuta la qualità delle citazioni. Ciò che distingue Claude è l'IA costituzionale, un metodo in cui un insieme scritto di principi guida l'addestramento e la valutazione. Il modello critica e verifica i propri risultati in base a una costituzione invece di affidarsi esclusivamente ai posizionamenti di preferenza umani. Questo influisce sul modo in cui Claude valuta la qualità, la sicurezza e la completezza delle risposte, ma non introduce un algoritmo distinto di posizionamento delle citazioni. L'elevata preferenza di Claude per fonti a controllo limitato può riflettere i principi costituzionali che danno importanza a fonti diverse e validate dagli utenti come segnali di rilevanza nel mondo reale. Oppure potrebbe essere semplicemente un artefatto della composizione dei dati di addestramento. Non è possibile distinguere tra queste spiegazioni attraverso i dati della ricerca.
Limitazioni
Questa analisi presenta diverse limitazioni che è opportuno esplicitare con chiarezza:
-
Correlazione, non causalità. I dati descrivono il comportamento delle citazioni ma non spiegano perché i modelli citano in modo diverso. La discussione sull'architettura di cui sopra offre spiegazioni plausibili, ma non confermate.
-
Istantanea temporale. Questi dati rappresentano il quarto trimestre del 2025. Gli aggiornamenti dei modelli sono frequenti e possono alterare i modelli di citazione. Non sappiamo quanto questi modelli siano stabili nel tempo.
-
Distorsione geografica. Sebbene i dati siano stati raccolti a livello globale, la maggior parte delle query riguardava gli Stati Uniti. I mercati internazionali potrebbero mostrare tendenze diverse.
-
Decisioni di classificazione. La categorizzazione delle fonti ha richiesto una valutazione discrezionale. I casi limite (siti web di franchising, aggregatori di recensioni) potrebbero essere classificati diversamente da altri ricercatori.
-
Campioni di dimensioni ridotte in alcuni settori. Le categorie di investimenti e pianificazione finanziaria (315 URL), servizi specializzati (114 URL), e industriale (2.677 URL) sono troppo piccole per trarne conclusioni affidabili.
Aree di approfondimento per ulteriori ricerche
-
Stabilità temporale. Queste tendenze si confermano anche dopo gli aggiornamenti dei modelli o sono transitorie? A questa domanda potrebbe rispondere il tracciamento longitudinale.
-
Impatto sui consumatori. In che modo le diverse tipologie di fonti citate influenzano concretamente le decisioni di acquisto? Il nesso tra visibilità nelle citazioni e comportamento dei consumatori non è ancora stato stabilito.
-
Differenze internazionali. Queste tendenze si verificano anche fuori dagli Stati Uniti? Gli ambienti normativi e la disponibilità delle fonti variano a seconda della regione.
-
Effetti di scelta del modello. I consumatori con diverse preferenze nella ricerca di informazioni tendono a privilegiare modelli il cui comportamento di citazione corrisponde alle loro esigenze? Questa è un'ipotesi verificabile che non abbiamo ancora testato.
Conclusione
In sostanza: i modelli di IA non citano tutti allo stesso modo, e le differenze sono sufficientemente rilevanti da incidere sulla visibilità dei brand.
Gemini privilegia i siti web proprietari, in linea con la sua strategia di ricerca Google. Claude attinge da contenuti generati dagli utenti a tassi dalle due alle quattro volte superiori rispetto ai concorrenti. SearchGPT varia notevolmente a seconda del settore, con una preferenza sproporzionata per i siti ufficiali degli hotel. Perplexity è il più coerente in tutti i settori.
Questi schemi variano inoltre più all’interno dei singoli settori che tra un settore e l’altro. Un brand nel settore bancario e dei prestiti si confronta con un contesto di citazione diverso rispetto a uno operante nel settore assicurativo, pur appartenendo entrambi all’area Finance.
Ciò che non possiamo ancora dire è quanto queste tendenze siano durature o quanto direttamente si traducano nelle decisioni dei consumatori. Le architetture dei modelli cambiano e i sistemi di raccolta vengono aggiornati. Le tendenze che abbiamo misurato nel quarto trimestre del 2025 potrebbero apparire diverse entro la metà del 2026.
Ciò che sembra meno probabile che cambi è la dinamica di fondo: modelli diversi, preferenze di fonti diverse, risultati di visibilità diversi. Le aziende che trattano la ricerca IA come un singolo canale da ottimizzare partono da un presupposto che i dati non supportano.
Appendice
Definizioni delle categorie di controllo
| Categoria | Definizione Completa |
|---|---|
| Controllo totale | Contenuti interamente creati e ospitati dall'azienda. Include siti web ufficiali, blog di proprietà, sale stampa aziendali e pagine di destinazione proprietarie. I brand hanno il pieno controllo editoriale sul messaggio, sull'accuratezza e sulla presentazione. |
| Controllo parziale | Archivi e piattaforme di terze parti dove un brand può rivendicare e gestire il proprio profilo. Pur non essendo proprietario della piattaforma, il brand può controllare direttamente l’accuratezza delle informazioni pubblicate. Include profilo dell'attività su Google, MapQuest e archivi specifici per settore. |
| Controllo limitato | Piattaforme in cui i contenuti sono principalmente generati dagli utenti, ma i brand possono partecipare attivamente attraverso risposte, coinvolgimento e gestione della reputazione. Include Google Reviews, Yelp, Facebook e piattaforme di social media. |
| Nessun controllo | Fonti in cui un brand non ha controllo diretto sui contenuti. Include notizie, discussioni su Reddit, post dei forum, contenuti generati dagli utenti e pubblicazioni indipendenti. |
Ricerche precedenti
Questa analisi si basa sui risultati emersi dagli studi di Yext dedicati alle citazioni dell'IA e agli archetipi della ricerca tramite IA:
- Citazioni IA, posizioni degli utenti e contesto delle query
- Le best practice ti aiutano solo fino a un certo punto
- L'ascesa degli archetipi di ricerca basati su IA
Informazioni su Yext Research
Yext Research conduce analisi indipendenti sul comportamento delle citazioni dell'IA utilizzando la piattaforma Yext Scout. I dati sul comportamento dei consumatori vengono raccolti tramite una partnership con Researchscape International.