KI-Zitate, Benutzerstandorte und Abfragekontext
Analyse auf Standortebene von 6,8 Millionen KI-Zitaten zeigt, warum der geografische Kontext die Grundlage der Markensichtbarkeitsstrategie sein sollte
Christian Ward, Anthony Rinaldi, Adam Abernathy und Alan Ai, 2025
Okt. 9, 2025
Einführung
In dieser Studie werden 6,8 Millionen Quellenzitate aus 1,6 Millionen Antworten untersucht, die von den drei großen KI-Modellen generiert wurden. Sie unterstreicht die Bedeutung der Absicht, des Standorts und der Speicherbedingungen (Kontext) der Benutzer*innen als zentrale Rahmenbedingungen für das Verständnis der Sichtbarkeit der KI-Suche.
Die meisten aktuellen Studien zu KI-Zitaten basieren auf einer markenbezogenen Perspektive, die den Standort oder den Kontext der Benutzer*innen außer Acht lässt. Dieser markenorientierte Ansatz erklärt, warum Quellen wie Wikipedia oder Reddit oft als wichtigste Referenzquelle angegeben werden. Diese Methode eignet sich zwar gut, um einer Marke eine Stimme zu verleihen, sie spiegelt jedoch nicht genau die typischen Zitationsmuster wider, wenn einzelne Benutzer*innen mit der KI interagieren.
Sobald der Standort und Kontext der Benutzer*innen berücksichtigt werden, wie dies normalerweise bei den meisten geschäftsbezogenen Fragen der Fall ist, verschieben sich die Zitationsmuster erheblich. Dieser standortbezogene Ansatz ist eine Funktion, die von den KI-Modellen selbst bereitgestellt wird. Auf direkte Nachfrage bestätigen Modelle von Google, OpenAI und Perplexity, dass sie den Standort von Verbraucher*innen verwenden, wenn sie auf Fragen zu Unternehmen und Dienstleistungen antworten.
Um diese Auswirkungen zu quantifizieren, haben wir standortbezogene Abfragen in vier großen Branchen getestet. Durch die Verwendung eines systematischen Vier-Quadranten-Rahmens (mit Markennamen/ohne Markennamen und objektiv/subjektiv) zeigen die Ergebnisse wesentliche Unterschiede darin, wie KI-Plattformen Informationen beschaffen und zitieren. Die Unterschiede je nach Branche, Abfragetyp und Verbraucherkontext etablieren die Analyse auf Standortebene als neue Grundlage für die KI-Sichtbarkeitsstrategie.
Diese Studie zeigt einen klaren und strategischen Weg für Marken auf, um ihre lokale Sichtbarkeit im Bereich KI zu stärken.
Wesentliche Erkenntnisse
Die Analyse auf Standortebene zeigt Zitations- und Quellenmuster, die mit den aktuellen Studien auf Markenebene nicht erkennbar sind. Eine Einzelhandelskette könnte landesweit eine Erstzitierungsrate von 47 % melden, aber eine Standortanalyse könnte Raten von 70 % in ländlichen Märkten und 20 % in wettbewerbsfähigen städtischen Märkten ergeben, wo Aggregatoren stärker vertreten sind. Diese geografischen Unterschiede machen nationale Metriken für eine lokale Sichtbarkeitsstrategie weniger nützlich.
- Die Macht von First-Party-Inhalten für faktische Fragen. Wenn Verbraucher*innen objektive Fragen ohne Bezug zu Markennamen stellen (z. B. „Welche [Kategorie] ist in meiner Nähe?“). Websites sind die dominierende Zitierquelle in allen drei Modellen und machen über 40 % der Zitate für Gemini, OpenAI und Perplexity aus. Dies ist die größte Chance für Marken, ihre Darstellung zu kontrollieren, indem sie klare, sachliche Informationen auf ihren eigenen Websites bereitstellen.
- Die starke Abhängigkeit von OpenAI von Verzeichnissen für subjektive Suchanfragen. Wenn eine Anfrage subjektiv wird (z. B. „Was ist das beste …?“), verschiebt sich das Zitierverhalten von OpenAI dramatisch. Sowohl bei markenspezifischen als auch markenneutralen Suchanfragen werden Verzeichnisse von Drittanbietern zu einer Primärquelle, wobei ein Spitzenwert von 46,3 % bei subjektiven Fragen mit Markennamen erreicht wird. Dies bedeutet, dass für meinungsbasierte Fragen auf OpenAI die Präsenz einer Marke in Verzeichnissen von größter Bedeutung ist.
- Der Fokus auf branchenspezifische Verzeichnisse für Perplexity. Perplexity zeigt durchweg eine starke Präferenz für branchenspezifische Verzeichnisse, insbesondere bei subjektiven Suchanfragen, bei denen Fachwissen eine Rolle spielt. Bei markenneutralen subjektiven Suchanfragen machen diese spezialisierten Verzeichnisse 24 % der Zitate aus, der höchste Wert aller Modelle. Dies zeigt, dass für Perplexity die Optimierung für Nischen- und branchenspezifische Plattformen ein wichtiger strategischer Hebel ist.
- Das ungenutzte Potenzial lokaler Websites. In nahezu allen Modellen und Abfragetypen stellen lokale Websites durchgängig eine bedeutende Referenzquelle dar, die in einigen Fällen von 8 % bis fast 20 % reicht (objektiv ohne Markennamen bei Gemini). Dies unterstreicht, wie wichtig es ist, für jeden Unternehmensstandort unterschiedliche, inhaltsreiche Seiten zu pflegen.
KI-Suche aus der Perspektive der Verbraucher*innen
Die Betrachtung von KI-Zitaten aus einer allgemeinen, markenbezogenen Perspektive, wie es bei den meisten aktuellen Sichtbarkeitsstudien der Fall ist, lässt die Aspekte der georäumlichen Suche unberücksichtigt. Eine echte Analyse auf Markenebene muss realistisches Benutzerverhalten berücksichtigen, indem granulare, standortbasierte KI-Abfragen im Kontext aggregiert werden. Dieser Prozess offenbart ein weitaus differenzierteres Quellmuster.
Die Sichtbarkeit in der KI ist nicht monolithisch; das Zitierverhalten ändert sich je nach Standort der Verbraucher*innen, dem Kontext ihrer Fragen, der Branche, dem KI-Modell und den einzelnen Referenzquellen selbst.
Die Beziehung zwischen dem Grad der Kontrolle einer Marke, dem erforderlichen Aufwand und der daraus resultierenden Nutzung von KI-Zitaten bietet einen leistungsstarken Rahmen für die Priorisierung von Maßnahmen.
Das Standort-Kontext-Framework
Die Sichtbarkeit von KI muss aus der Perspektive der Verbraucher*innen verstanden werden. Um das KI-Verhalten systematisch aus der Perspektive der Verbraucher*innen zu untersuchen, haben wir das Standort-Kontext-Framework entwickelt, ein Modell, das mit dem Standort der Verbraucher*innen beginnt und dann die Art der Fragen berücksichtigt, um Zitationsmuster zu verstehen. Dies steht im Gegensatz zu aktuellen Untersuchungen, die auf Analysen auf Markenebene basieren und möglicherweise einen „Query Fan-Out“-Ansatz verwenden, bei dem die KI nachfolgende Fragen generiert. Diese Methode ist zwar für Markenkommentare nützlich, führt jedoch dazu, dass häufig allgemeine Quellen wie Wikipedia oder Foren angezeigt werden. Dies hat zur Folge, dass die KI eher Kommentare liefert als Antworten auf spezifische Verbraucherbedürfnisse.
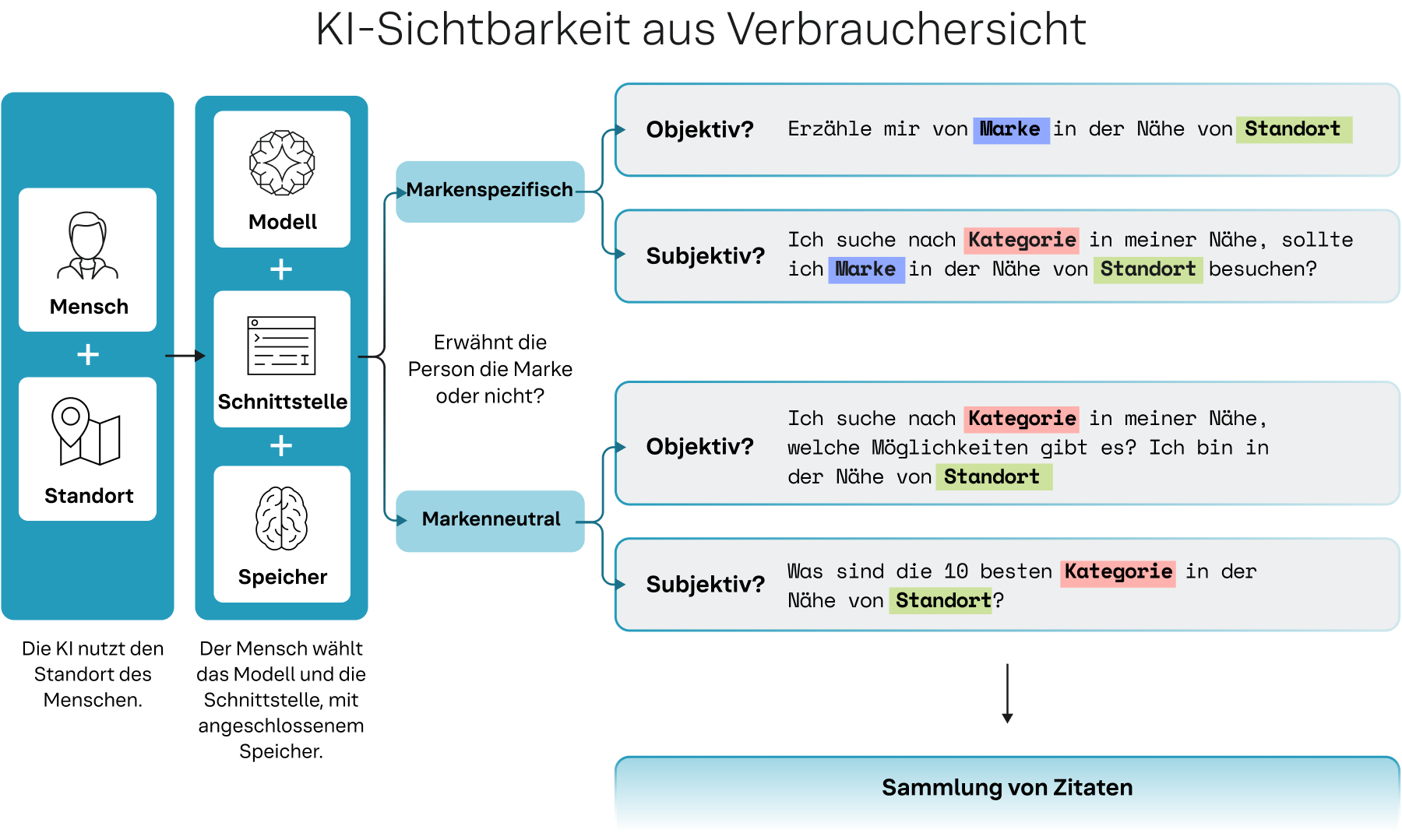 Abbildung 1: Anstelle eines generierten Fan-Outs folgt unser Standort-Kontext-Framework einem klaren und vorhersehbaren Pfad.
Abbildung 1: Anstelle eines generierten Fan-Outs folgt unser Standort-Kontext-Framework einem klaren und vorhersehbaren Pfad.
Das Standort-Kontext-Framework definiert einen klaren und vorhersehbaren Pfad, der das Verhalten der durchschnittlichen Verbraucher*innen simuliert, wenn sie mit einem KI-Modell zu verschiedenen suchbezogenen Themen interagieren.
- Ein Mensch hat ein Bedürfnis und befindet sich an einem bestimmten Ort. Die KI verwendet diesen geografischen Kontext als grundlegenden Filter, ähnlich wie bei der klassischen Suche (Google).
- Die Verbraucher*innen wählen ein Modell (wie Gemini oder ChatGPT) und eine Benutzeroberfläche. Die Verbraucher*innen bringen zudem ihr Gesprächsgedächtnis in die Sitzung ein, was die nachfolgenden Antworten beeinflussen kann.
- Die Verbraucher*innen gestalten ihre Anfragen intrinsisch entlang zweier Dimensionen: markenbezogen vs. markenneutral und objektiv vs. subjektiv.
Unsere Ergebnisse zeigen einen klaren Kompromiss. Je mehr Kontrolle eine Marke über eine Quelle hat, desto größer ist auch das Potenzial, dass diese als Zitat in KI-Antworten verwendet wird. Allerdings ist hierfür oft ein größerer Aufwand erforderlich. Die strategische Chance liegt darin, das richtige Gleichgewicht zu finden. Während „Full Control“-Quellen, wie Websites von Erstanbietern, die höchste Effektivität bieten, stellen „Controllable“-Einträge auf Websites von Drittanbietern einen kritischen Sweet Spot dar, der ein hohes Volumen an Zitaten mit einem moderaten Verwaltungsaufwand liefert. Der von uns vorgeschlagene Rahmen ermöglicht es Marken, über einen reaktiven Ansatz hinauszugehen und ihre Ressourcen proaktiv auf die Aktivitäten zu konzentrieren, die den größten Einfluss auf ihre KI-Sichtbarkeit haben werden.
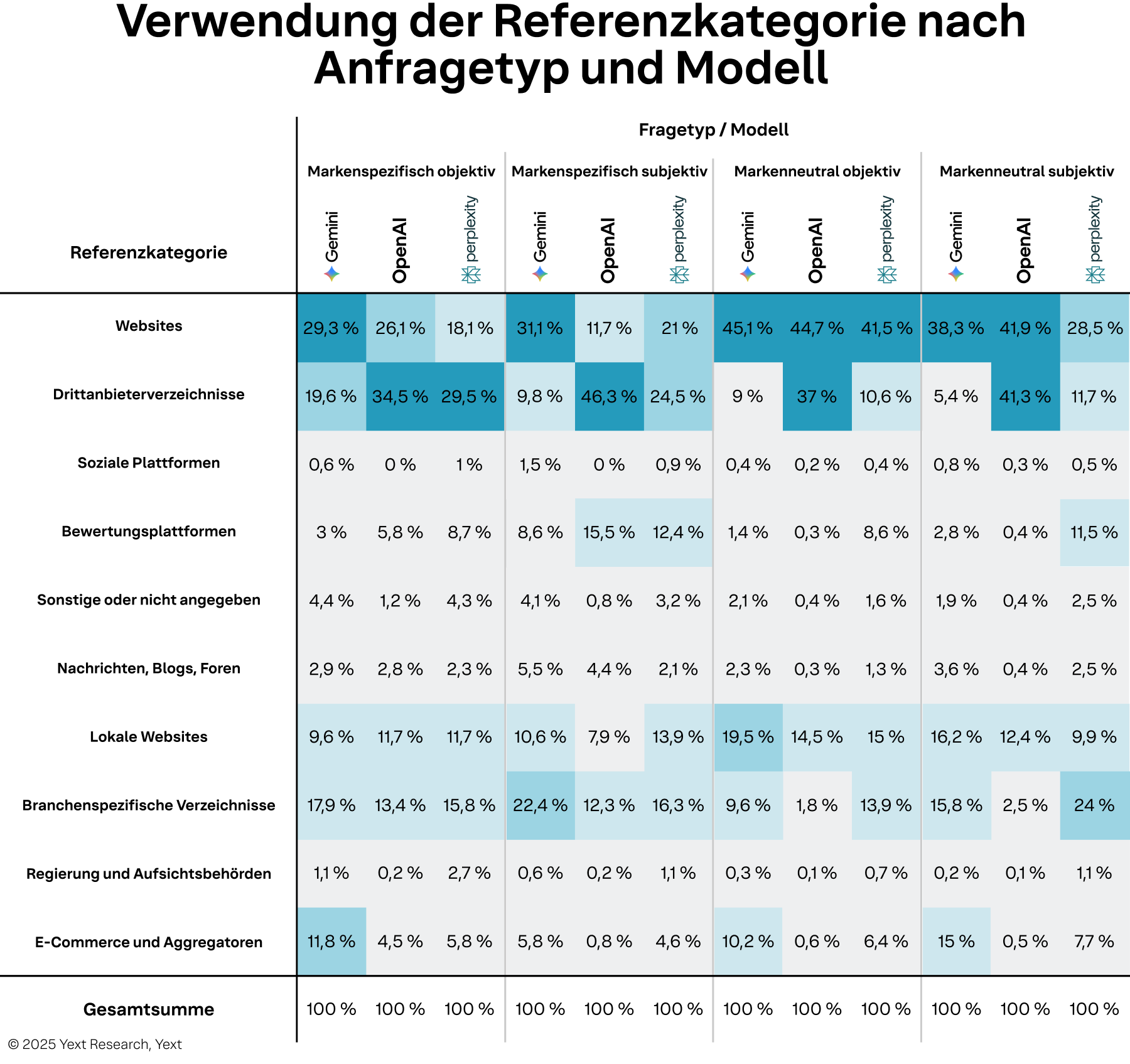 Tabelle 1
Tabelle 1
Während viele Studien auf Markenebene darauf hinweisen, dass Foren wie Reddit eine dominierende Quelle für Zitate sind, zeigt die Anwendung einer standortbasierten Verbraucherperspektive, dass diese Quellen weitaus seltener vorkommen und nur etwas mehr als 2 % (154.000) der gesamten Zitate ausmachen. Dies mindert nicht ihre Bedeutung für Markenkommentare, zeigt aber, dass sich ihre Rolle bei standortspezifischen Verbraucheranfragen ändert.
Definition von KI-Zitationsquellen nach Grad der Markenkontrolle
Es ist notwendig, Zitationsquellen auf der Grundlage der Fähigkeit einer Marke zu kategorisieren, die darin enthaltenen Informationen zu kontrollieren. Das Kontroll-Framework teilt die Zitierquellen in vier verschiedene Kategorien ein, von Quellen, die einer Marke vollständig gehören, bis hin zu solchen, auf die sie keinen direkten Einfluss hat. Diese strategische Klassifizierung ermöglicht es Marken, ihre Bemühungen zu priorisieren, indem sie Ressourcen dort einsetzen, wo sie die größte Wirkung erzielen können.
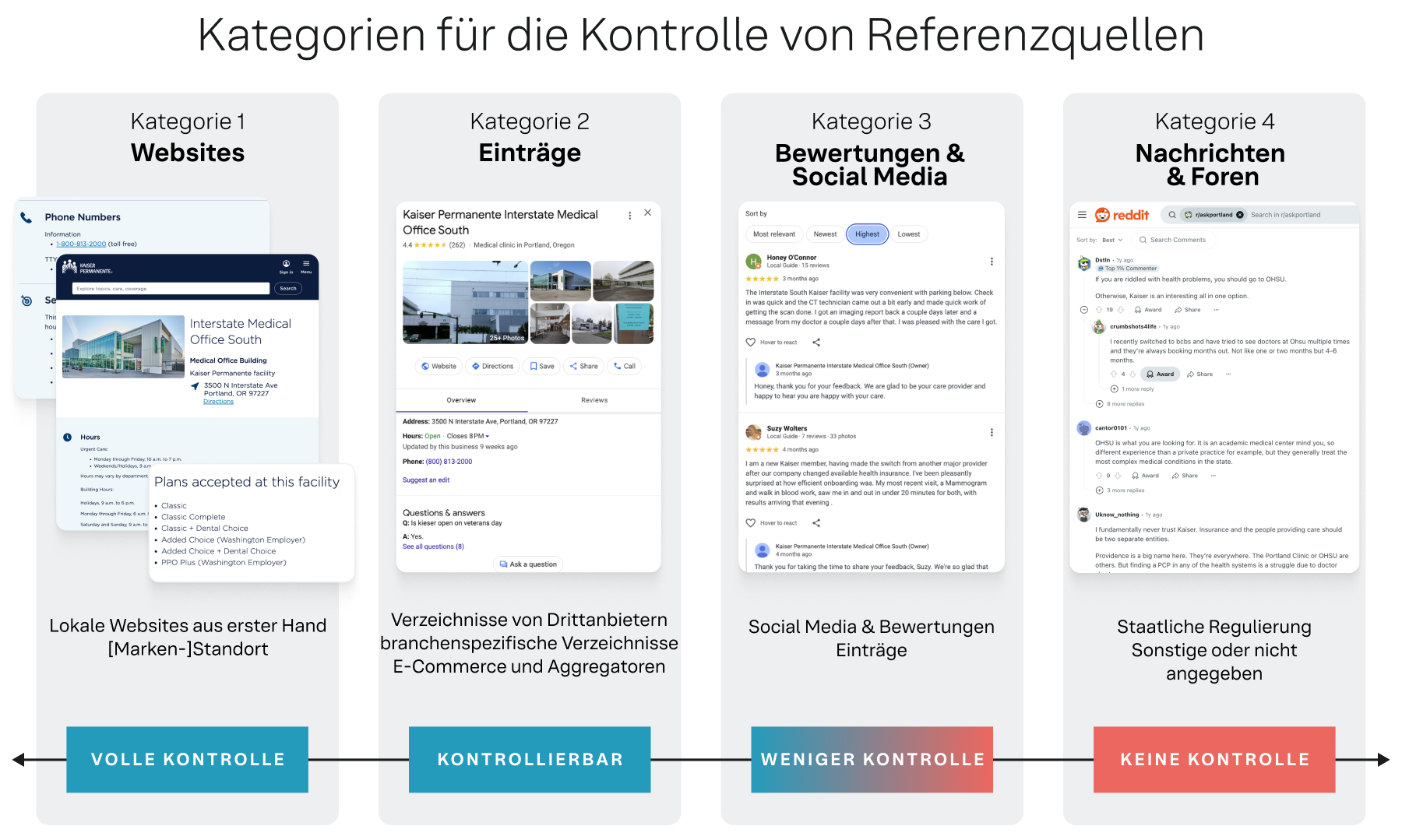 Abbildung 2
Abbildung 2
Kategorie 1: Volle Kontrolle (Websites) umfasst die eigenen digitalen Objekte einer Marke. Marken haben die vollständige und direkte Kontrolle über alle Inhalte. Diese Kategorie ist die am häufigsten zitierte in der Studie, mit über 2,9 Millionen Zitaten von Unternehmensdomains (z. B. wendys.com), lokalen Seiten (z. B. locations.bankofamerica.com) und anderen markeneigene Web-Assets.
Kategorie 2: Kontrollierbar (Einträge) umfasst eine breite Palette von Drittanbieter-Verzeichnissen und Plattformen, auf denen eine Marke ihr Profil beanspruchen und verwalten kann. Obwohl die Marke nicht Eigentümer der Plattform ist, kann sie die Genauigkeit ihrer Informationen direkt kontrollieren. Diese Kategorie umfasst über 2,9 Millionen Zitate und beinhaltet branchenübergreifende Plattformen, Google-Unternehmensprofil und Mapquest sowie branchenspezifische Verzeichnisse wie TripAdvisor (Gastronomie/Lebensmittel) oder Zocdoc (Gesundheitswesen).
Kategorie 3: Beeinflusst (Bewertungen und Social Media) umfasst Plattformen, auf denen Inhalte hauptsächlich nutzergeneriert sind, aber Marken aktiv teilnehmen können. Diese Kategorie basiert auf dem Ruf und umfasst über 545.000 Zitate aus Quellen wie Google Reviews, Yelp und Facebook.
Kategorie 4: Unkontrolliert (Nachrichten, Foren, Sonstige) umfasst alle Quellen, über die eine Marke keine direkte Kontrolle hat. Ein interessantes Ergebnis dieser Studie ist die relativ geringe Anzahl der Zitate in dieser Kategorie.
Die wichtigste Erkenntnis aus diesen Daten ist optimistisch: Marken können die Quellen, die für etwa 86 % aller Zitate mit Verbraucherbezug verantwortlich sind, direkt beeinflussen oder verwalten. Dieses hohe Maß an Kontrolle wird erst durch den Wechsel von der Marken- zur Standortperspektive deutlich.
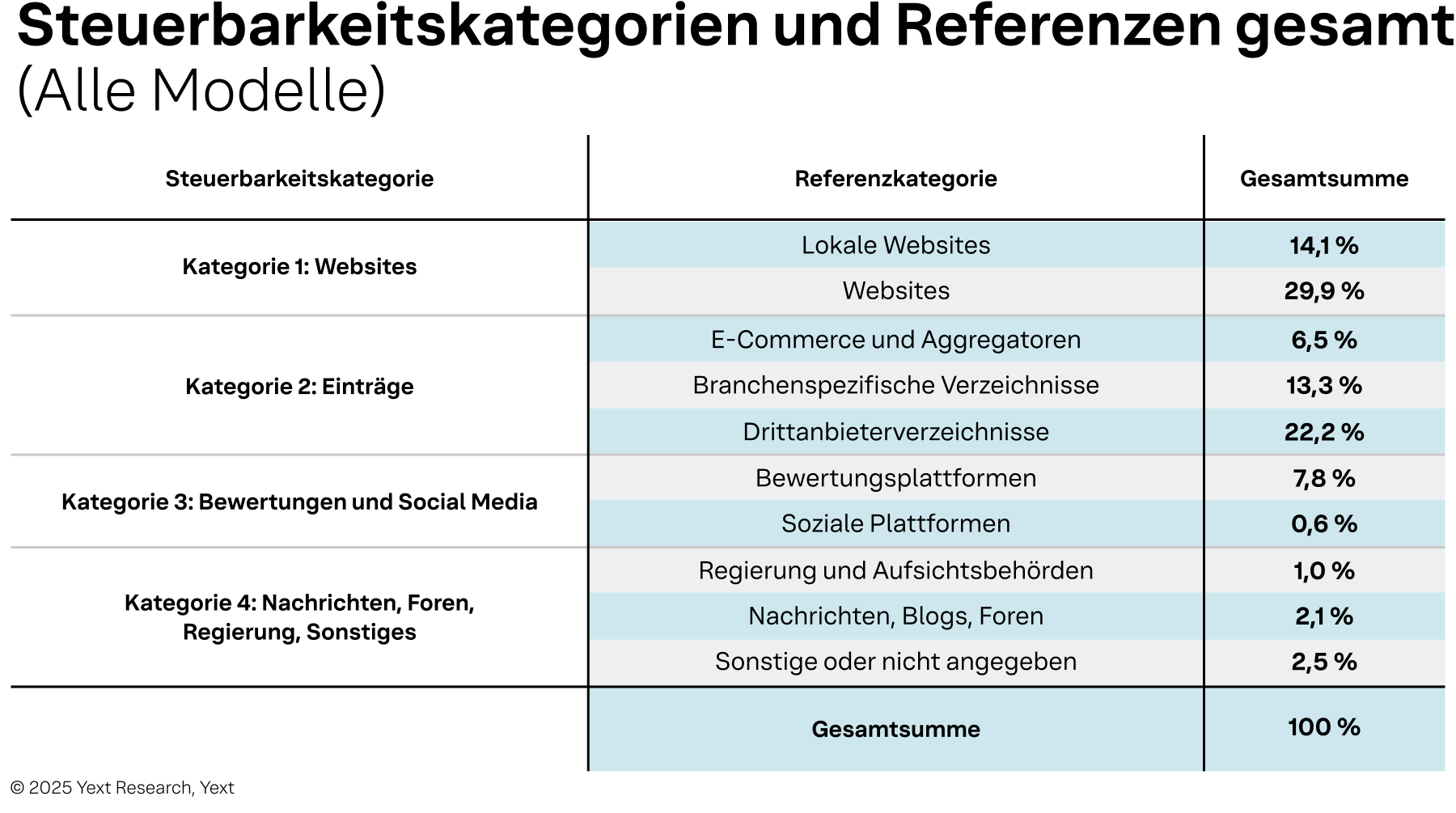 Tabelle 2
Tabelle 2
Durch das Verständnis der Zitationsmuster an einzelnen Verbraucherstandorten kann eine Marke diese Daten aggregieren, um eine präzise und umsetzbare Strategie zur Verbesserung ihrer Sichtbarkeit in der KI zu entwickeln. Ohne dieses detaillierte Verständnis ist es nahezu unmöglich, einen klaren Weg zu finden, um die Verbraucher*innen dort zu erreichen, wo sie sich befinden.
Unterschiede zwischen Modellen
Das Zitationsverhalten ist in allen KI-Modellen nicht einheitlich. Tatsächlich variiert es erheblich. Wir stellen fest, dass die Sichtbarkeitsstrategie einer Marke die unterschiedlichen Beschaffungspräferenzen der einzelnen Plattformen berücksichtigen muss.
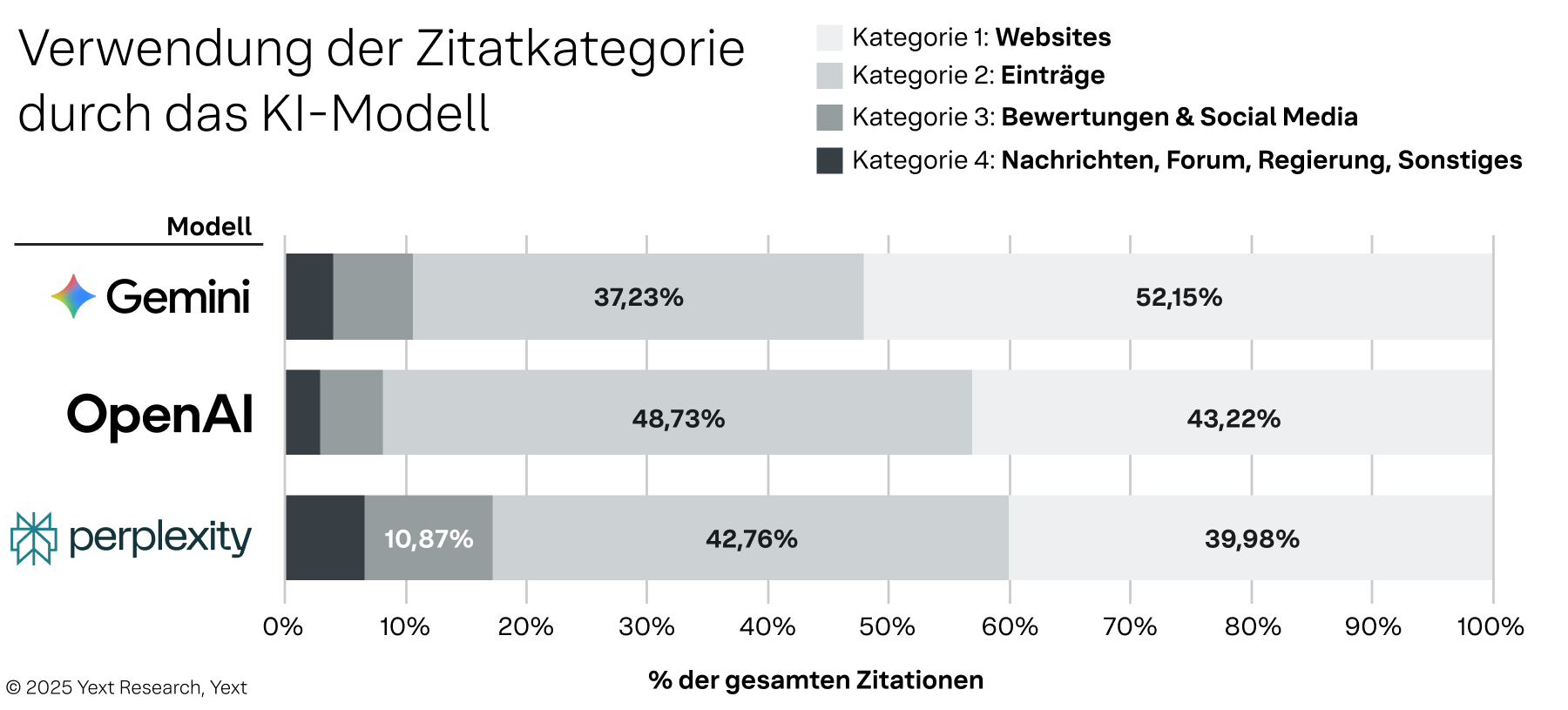 Abbildung 3
Abbildung 3
Es gibt viele Unterschiede in den Quellen für jedes Modell. Gemini zeigt eine starke Präferenz für Websites von Erstanbietern und bezieht 52,15 % seiner Zitate aus diesen vollständig kontrollierten Quellen. Im Gegensatz dazu ist OpenAI stark von Einträgen abhängig, wobei 48,73 % seiner Zitate von diesen kontrollierbaren Drittanbieter-Plattformen stammen. Diese Präferenzen werden noch deutlicher, wenn man einzelne Bereiche untersucht. Die Abhängigkeit von OpenAI von Einträgen konzentriert sich überwiegend auf Google, auf das über 465.000 Zitate entfallen. Perplexity hingegen diversifiziert seine Quellen und bevorzugt MapQuest für Einträge (über 364.000 Zitate) und TripAdvisor für Bewertungen (über 239.000 Zitate).
Es ist auch wichtig zu beachten, was nicht als Zitat gezählt wird. Gemini verwendet beispielsweise die Informationen des Google-Unternehmensprofils in seinen Antworten, nennt sie aber nicht als Quelle, da es sich um firmeneigene Daten handelt.
Diese Verhaltensnuancen bedeuten, dass die Präsenz einer Marke in einem Modell nicht ihre Sichtbarkeit in einem anderen garantiert. Dieses Thema wird in der nachfolgenden Analyse untersucht.
Unterschiede nach Branche
Ähnlich wie bei unseren früheren Erkenntnissen bei der Analyse von Google-Unternehmensprofilen zeigen sich auch bei den KI-Zitaten nach Branche deutliche Verhaltensmuster.
Sie können nicht von einem homogenen Verhalten in allen Branchen ausgehen. Wir haben schnell eine einzigartige Mischung von Zitatquellen für jede Branche gefunden. Die Mischung aus markeneigenen Websites (Kategorie 1) und Drittanbieterquellen (Kategorien 3–4) bestimmt letztendlich das Ausmaß der Kontrolle eines Unternehmens über seine Darstellung in KI-generierten Ergebnissen.
(Hinweis: Ausführliche Berichte für Finanzwesen, Gastronomie, Gesundheitswesen und Einzelhandel werden separat veröffentlicht.)
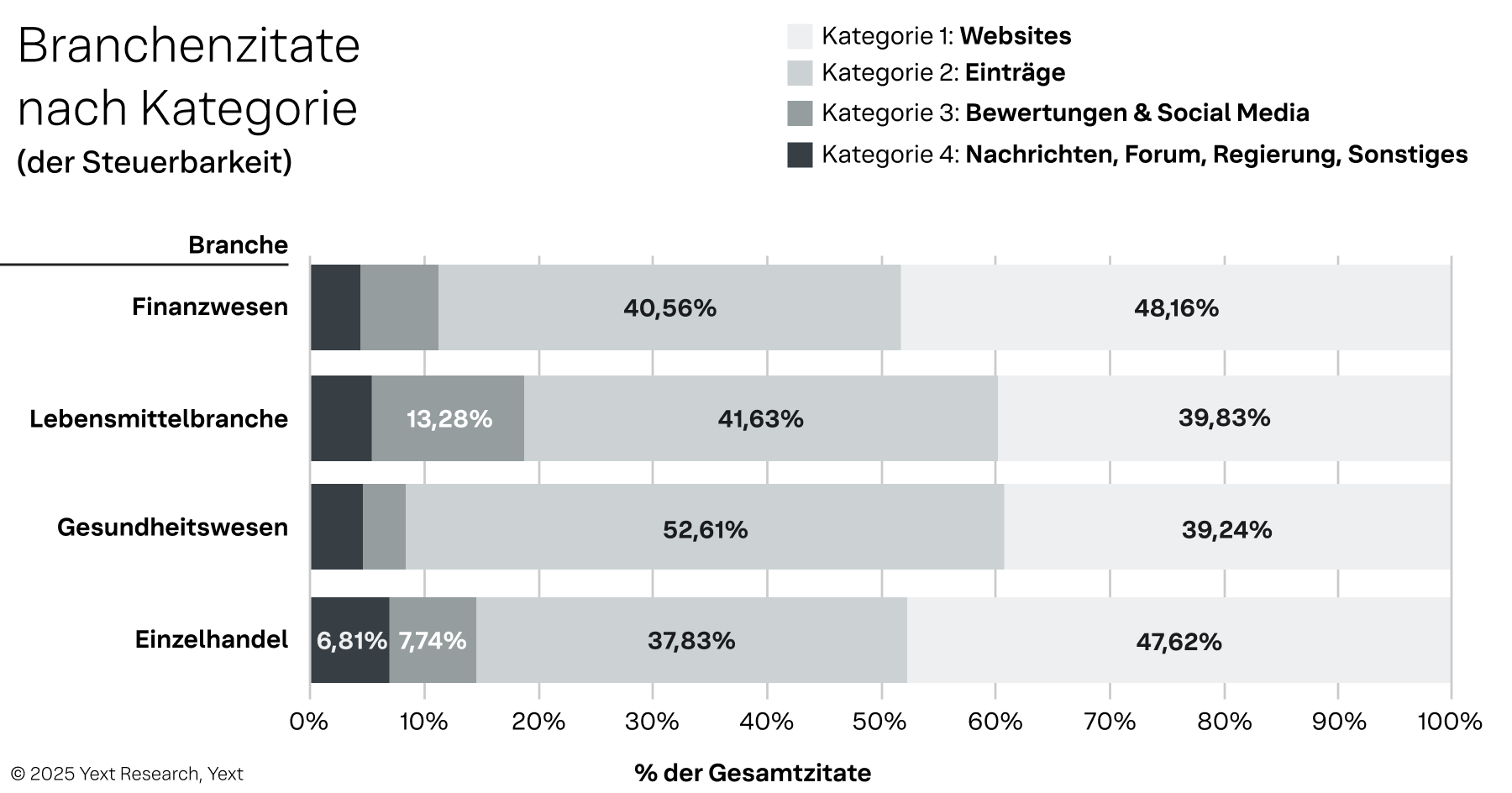 Abbildung 4
Abbildung 4
Bemerkenswerte Unterschiede nach Branchen:
- Finanzdienstleistungen und Einzelhandel weisen das größte Potenzial für die First-Party-Kontrolle auf, wobei Websites (Kategorie 1) 48,16 % bzw. 47,62 % ihrer Zitate ausmachen. Die regulierte Natur des Finanzwesens und die E-Commerce-Infrastruktur des Einzelhandels treiben KI-Modelle zu autoritativen, markeneigenen Quellen.
- Das Gesundheitswesen ist am stärksten auf die Validierung durch Dritte angewiesen, wobei 52,61 % aller Zitate auf Einträge (Kategorie 2) entfallen. Dies zeigt, wie wichtig medizinische Verzeichnisse, Zulassungsdatenbanken und Versicherungsplattformen für den Aufbau von Vertrauen sind.
- Gastronomie stellt eine besondere Herausforderung dar, da dieser Bereich sowohl von Einträgen (41,63 %) als auch von Bewertungen (13,28 %) stark abhängig ist. Der Anteil der Zitate aus Quellen der Kategorie 3 ist mit 13,28 % der höchste aller Branchen. Dies zeigt, dass für Gastronomiemarken Reputation und nutzergenerierte Inhalte entscheidende Faktoren für die Sichtbarkeit in der KI sind.
Methode
Diese Studie basiert auf der Analyse von 6,8 Millionen Zitationen, die zwischen dem 1. Juli 2025 und dem 31. August 2025 aus KI-Suchergebnissen gesammelt wurden. Die Daten wurden im Rahmen einer globalen Studie über Yext-Kund*innen und -Interessenten erhoben, die die Yext Scout-Plattform nutzen. Obwohl die Daten von einer bestimmten Benutzergruppe stammen, ist die Bandbreite der zitierten Quellen beträchtlich und umfasst einen Long Tail von 20.820 einzigartigen Domains.
Mithilfe eines automatisierten Systems wurden rund 1,6 Millionen einzelne Abfragen für jedes der drei großen KI-Modelle gestellt: Gemini, OpenAI und Perplexity. Die Abfragen wurden so konzipiert, dass sie vier verschiedene Quadranten von Verbraucherintentionen repräsentieren (objektive Fragen mit Markennamen, subjektive Fragen mit Markennamen, objektive Fragen ohne Markennamen und subjektive Fragen ohne Markennamen). Sie wurden an jedem Kunden- und Interessentenstandort in vier wichtigen Branchen getestet: Finanzwesen, Lebensmittel, Gesundheitswesen und Einzelhandel. Diese Daten wurden mithilfe der einzelnen APIs erfasst, die von jedem Modell bereitgestellt werden.
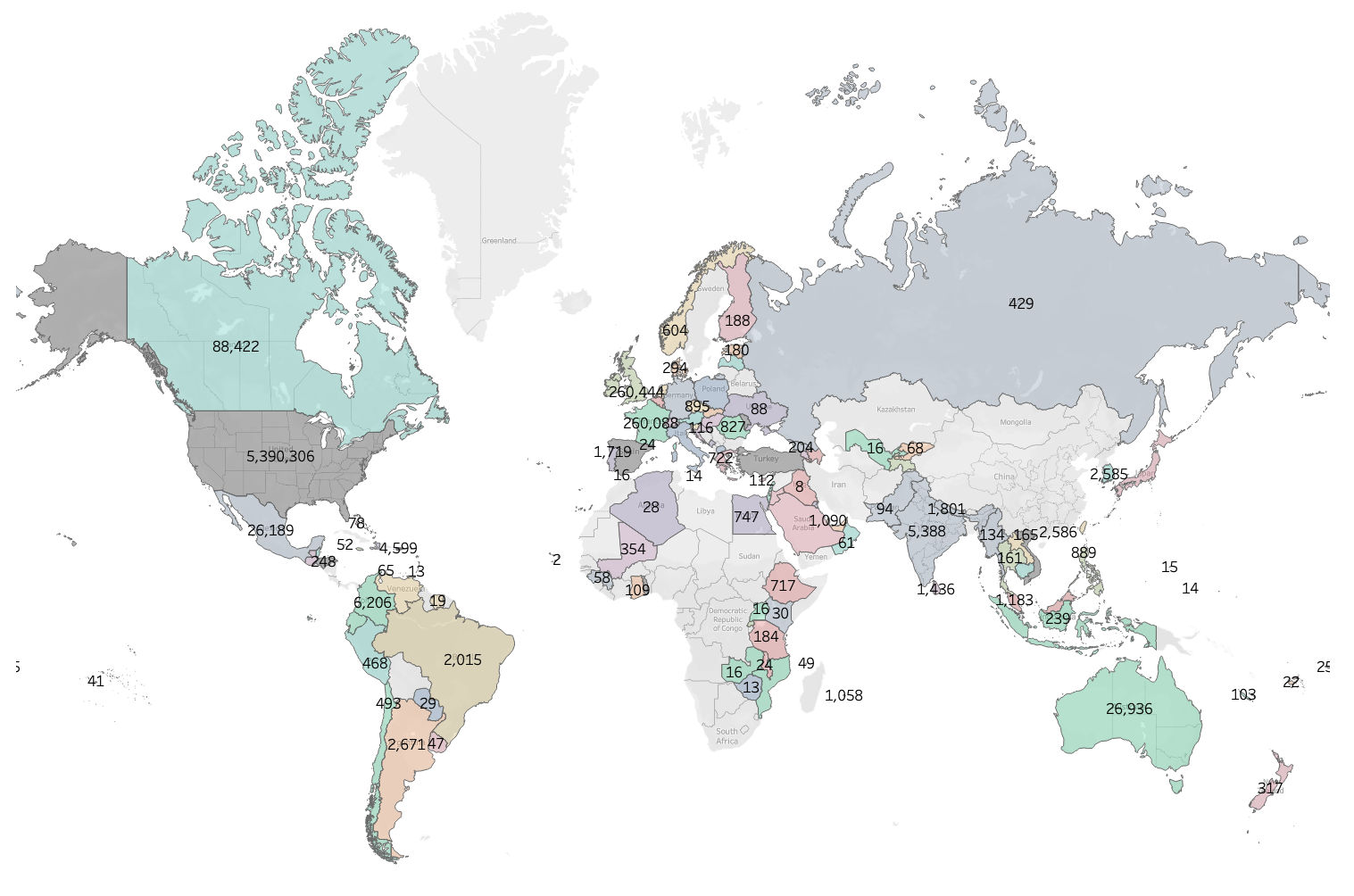
Abbildung 5: Im Rahmen dieser Studie wurden weltweit 6,8 Millionen Zitate gesammelt.
Der Einfluss der Geolokalisierung auf die KI-Suche
Modelle von Google, OpenAI und Perplexity bestätigen, dass sie den Standort von Verbraucher*innen in ihre Antworten zu Unternehmen und Dienstleistungen einbeziehen. Wir glauben nicht, dass dies ein wesentlicher Faktor für die Priorisierung der Relevanz durch diese Systeme ist. So wie eine herkömmliche Suchmaschine standardmäßig Restaurants in der Nähe anzeigt, wenn Sie „Pizza“ eingeben, verwenden moderne KI-Modelle Geolokalisierungssignale, um ihre Antworten im physischen Raum zu verankern. Unabhängig davon, ob die Eingabe von einer IP-Adresse, den Geräteeinstellungen oder einer expliziten Aufforderung der Benutzer*innen stammt, scheint der Standort ein gewichteter Faktor bei der Berechnung des Modells zu sein, was eine nützliche Antwort darstellt.
Der Effekt ist subtil, aber signifikant. Zwei Personen, die dieselbe Frage an verschiedenen Orten stellen, erhalten möglicherweise unterschiedliche Antworten, die von den lokalen Geschäftsdaten, der Serviceabdeckung und sogar dem regionalen Sprachgebrauch geprägt sind. Das bedeutet, dass die „Suche“ im Zeitalter der KI nicht länger ein rein abstrakter Prozess zur Auflösung der Suchabfragen ist. Die KI-gestützte Suche ist untrennbar mit dem Standort der Benutzer*innen und dem lokalen Wissensgraph verbunden.
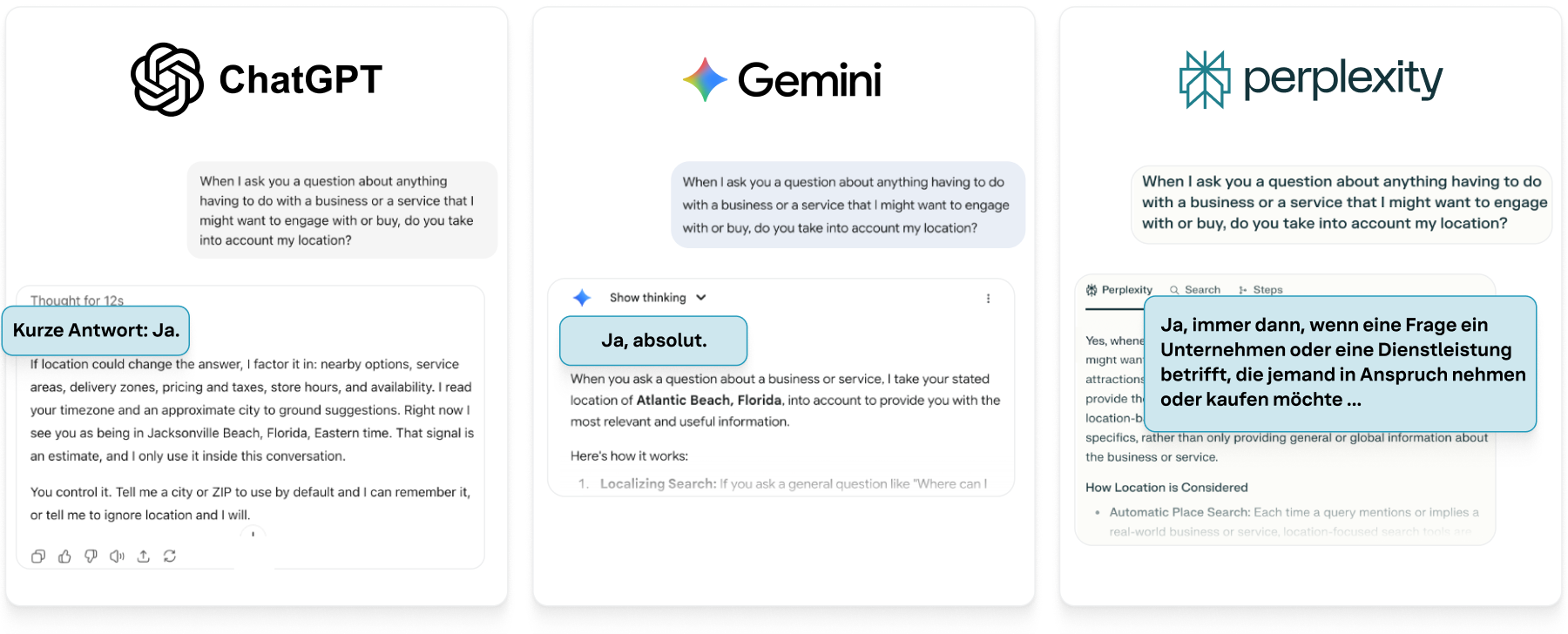
Abbildung 6: Alle drei großen KI-Modelle berücksichtigen den Standort als Teil ihres RAG-Prozesses.
Klassifizierung von Suchanfragen nach Absicht
Wir stellen einen strukturierten Ansatz zur Bestimmung von Abfragetypen in Bezug auf die zugrunde liegende Absicht vor. Das Query Classification Framework (QCF) umfasst vier verschiedene Abfragequadranten, die das tatsächliche Verbraucherverhalten widerspiegeln und unterschiedliche Zitiermuster ergeben. Bei objektiven Suchanfragen werden sachliche Informationen abgefragt, beispielsweise „[Hamburger-Restaurant] in meiner Nähe“. Subjektive Abfragen suchen nach Meinungen wie „Was sind die 10 besten [Hamburger-Restaurants] in der Nähe von [Ort]?“. Dieses Framework ermöglicht eine genauere Analyse der Art und Weise, wie KI-Modelle auf reale Verbraucherbedürfnisse reagieren.
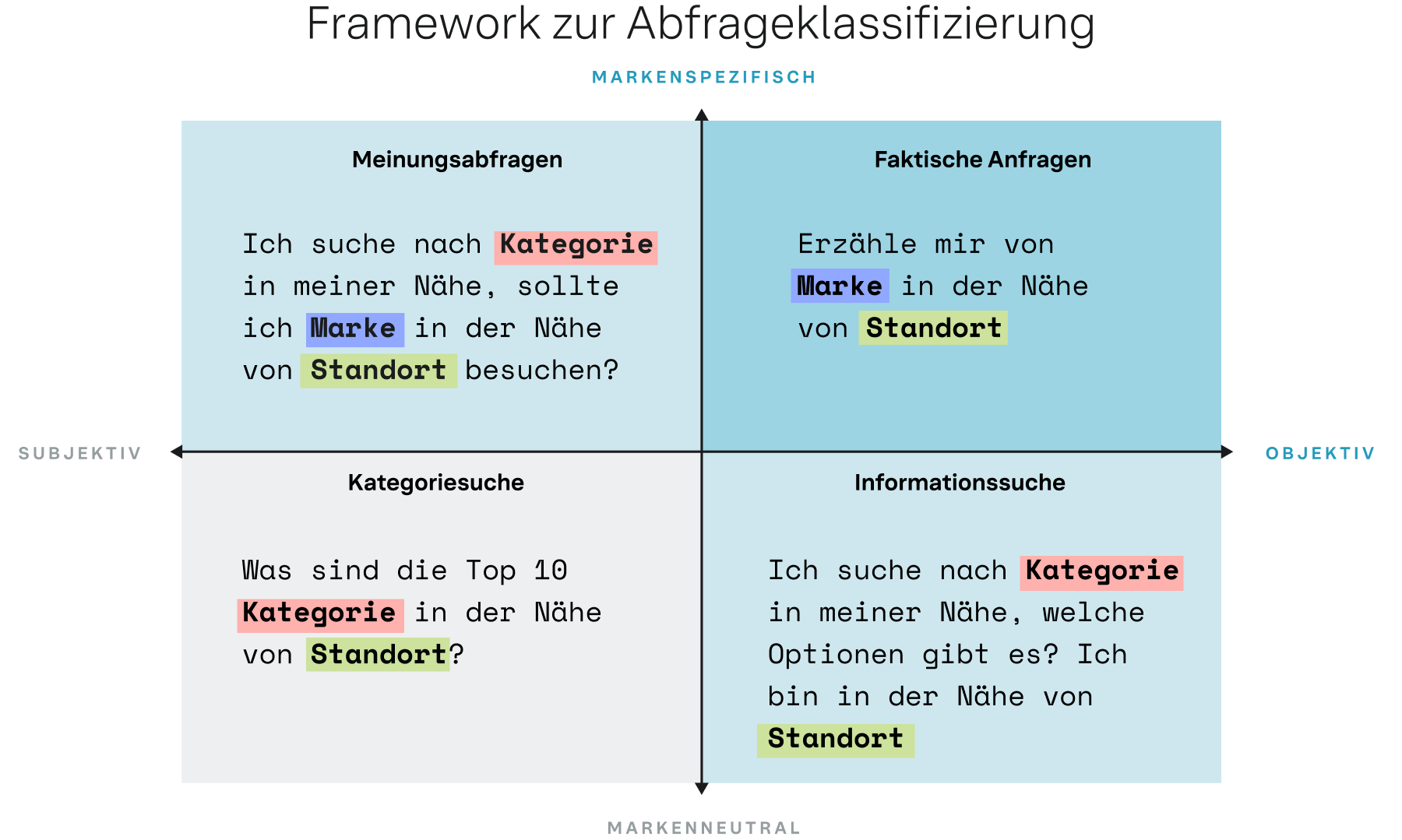 Abbildung 7
Abbildung 7
Wie Sie sehen, sind die Zitate, die über die verschiedenen Abfragetypen verfolgt werden, meist gleichmäßig verteilt, obwohl es größere Branchenunterschiede gibt. Das Design dieses Rahmens ermöglicht eine Analyse, die über eine aggregierte Betrachtung hinausgeht. Durch die Verfolgung der Ergebnisse einzelner Fragetypen auf Modellbasis kann diese Studie genau ermitteln, welche Zitationsquellen jedes KI-Modell bevorzugt, unter Berücksichtigung des Standorts der Verbraucher*innen, der spezifischen Abfrage und des Branchenkontexts.
Wenn wir das QCF auf unsere Abfrage-/Zitatmenge anwenden, erhalten wir eine weitgehend gleichmäßige Verteilung. Bei „objektiven“ Fragen gibt es zwischen den Branchen zum Teil deutliche Unterschiede.
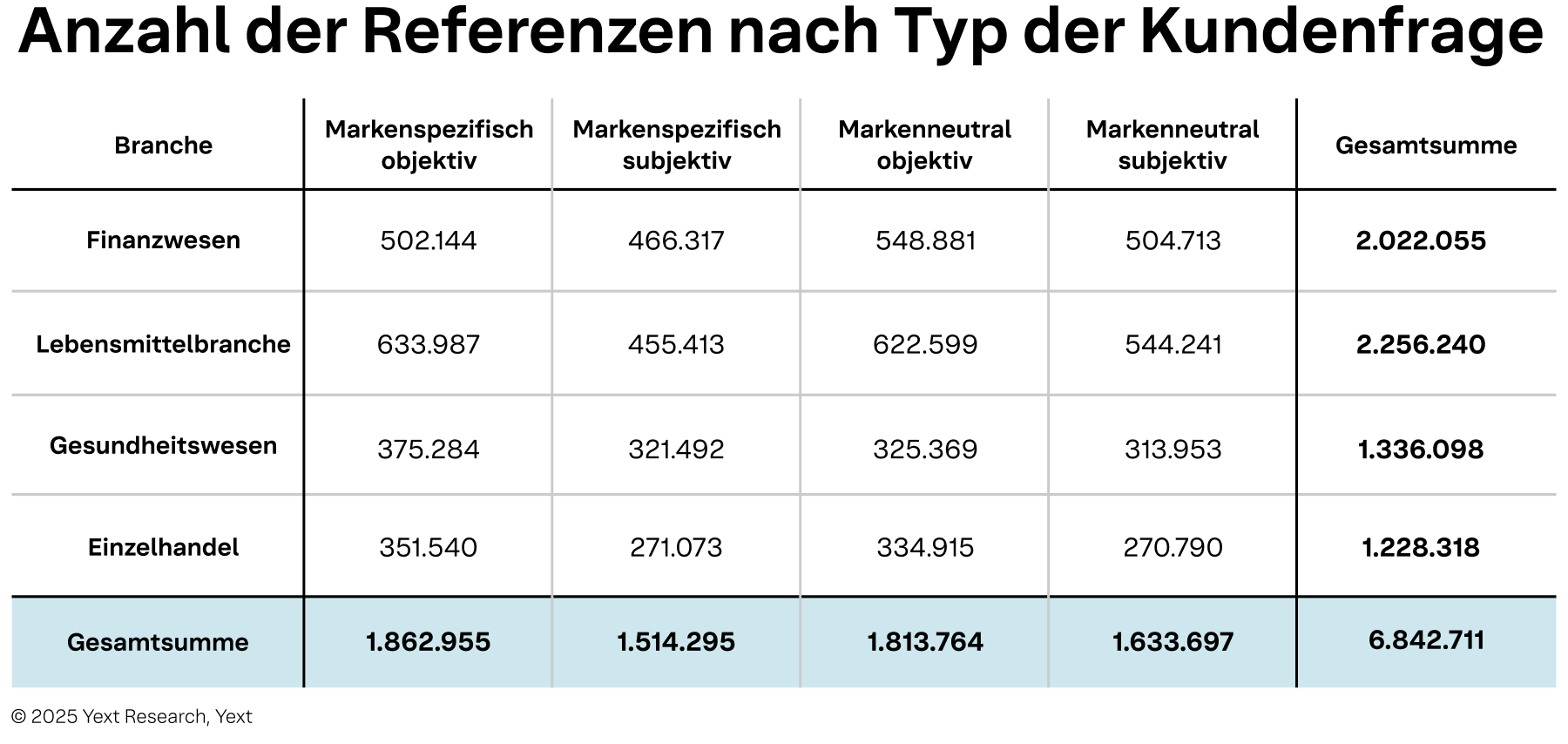 Tabelle 3
Tabelle 3
Einschränkungen und zukünftige Forschung
Diese Analyse basiert auf Daten von Yext-Kund*innen und -Interessenten und umfasst über 200.000 Standorte, an denen sie tätig sind oder tätig sein könnten. Die Yext Scout-Plattform importiert alle verfügbaren Zitate direkt aus den APIs der einzelnen KI-Modelle. Es ist wichtig, die Unterschiede zwischen den über eine API zurückgegebenen Zitaten und denen, die in einer direkten Benutzeranwendung angezeigt werden, zu beachten. Die inhärente Volatilität großer Sprachmodelle bedeutet, dass der Gesprächskontext einer Person, die Verwendung eines bestimmten Modells und das Gesprächsgedächtnis die Antworten beeinflussen können. Folglich können zwischen Benutzer*innen erhebliche Abweichungen auftreten. Durch die Analyse von Tausenden von kontextbezogenen Prompts für Marken und Unternehmen sind wir jedoch der Meinung, dass die daraus resultierenden Zitierquellenmuster wahrscheinlich auf allgemeine Nutzungsmuster innerhalb eines bestimmten Standortes hinweisen.
Bereiche für zusätzliche Forschung
Die Ergebnisse dieses Berichts eröffnen mehrere Möglichkeiten für eine detailliertere Forschung. Zukünftige Analysen werden folgende Aspekte umfassen:
- Modellspezifische Vertiefungen: Eine detaillierte Aufschlüsselung der Zitationsmuster für jedes einzelne KI-Modell, wobei die in diesem Bericht identifizierten Unterschiede in späteren Teilberichten vertieft werden.
- Branchen-Unterberichte: Analyse der spezifischen Domänen und Zitationsquellen, die in den einzelnen Branchenberichten für Finanzwesen, Lebensmittel, Gesundheitswesen und Einzelhandel am häufigsten vorkommen.
- Geografische Variationsanalyse: Eine quantitative Analyse, wie sich die Zitationsmuster zwischen geographischen Markttypen, wie dicht besiedelten Stadtzentren und eher ländlichen Gebieten, unterscheiden, um auf den ersten Beobachtungen in dieser Studie aufzubauen.
- Langfristige Verfolgung: Laufende Überwachung von Zitationsquellen, um zu verstehen, wie sich die Muster entwickeln, wenn die zugrunde liegenden KI-Modelle im Laufe der Zeit aktualisiert und neu trainiert werden.
Fazit
Die Ergebnisse dieser Studie eröffnen eine neue Perspektive auf die Sichtbarkeit von KI. Eine allgemeine Analyse auf Markenebene reicht nicht mehr aus, da sie die Quellmuster, die sich aus den Anfragen realer Verbraucher*innen ergeben, nicht erfasst. Ein echtes Verständnis muss von Grund auf aufgebaut werden, indem detaillierte, standortbasierte Daten gesammelt werden, die den spezifischen Kontext der Bedürfnisse der Verbraucher*innen widerspiegeln.
Dieser standortbezogene Ansatz zeigt einen logischen Weg nach vorn. Während die derzeitige Analyse auf Markenebene oft eine Vielzahl unkontrollierter Quellen hervorhebt, zeigt diese Studie, dass KI-Modelle bei spezifischen Verbraucheranfragen auf einen strukturierteren Satz von Informationen zurückgreifen. Marken können die überwiegende Mehrheit dieser Quellen direkt kontrollieren oder beeinflussen. Die effektivste Strategie ist die bewusste Verwaltung der Websites von Erstanbietern, der Einträge von Drittanbietern und der Online-Reputation einer Marke.
Diese Studie, die auf Daten von Interessenten und Kund*innen aus zwei Monaten auf der Yext Scout-Plattform basiert, ist erst der Anfang.
Angesichts der Weiterentwicklung von KI-Modellen bietet diese Methode zur Analyse auf Standortebene einen dauerhaften, kundenorientierten Ansatz zur Bewertung der Markenleistung bei der KI-Suche.