Citazioni IA, posizioni degli utenti e contesto delle query
Analisi a livello locale di 6,8 milioni di citazioni generate dall’IA: perché il contesto geografico dovrebbe essere la base di ogni strategia di visibilità del brand.
Christian Ward, Anthony Rinaldi, Adam Abernathy, e Alan Ai, 2025
ott 9, 2025
Introduzione
Questo studio analizza 6,8 milioni di citazioni di fonti provenienti da 1,6 milioni di risposte generate dai tre principali modelli di IA. Evidenzia come l’intento dell’utente, la posizione e le condizioni di memoria (contesto) rappresentino i principali framework per comprendere la visibilità nella ricerca basata sull’IA.
La maggior parte delle ricerche attuali sulle citazioni dell'IA si basa su una prospettiva a livello di brand che ignora la posizione o il contesto dell'utente. Questo approccio incentrato sul brand spiega perché fonti come Wikipedia o Reddit appaiono spesso come principali fonti di citazione. "Sebbene questo metodo funzioni bene per stabilire la voce del brand, non riflette accuratamente gli schemi di citazione tipici quando i singoli utenti interagiscono con l'IA.
Una volta considerata la posizione e il contesto dell'utente, come di solito accade per la maggior parte delle domande di carattere commerciale, i modelli di citazione cambiano in modo significativo. Questo approccio incentrato sulla posizione è una funzione dichiarata degli stessi modelli di IA. Quando interrogati direttamente, i modelli di Google, OpenAI e Perplexity hanno confermato di utilizzare la posizione di un consumatore per rispondere a domande su aziende e servizi.
Per quantificare queste implicazioni, abbiamo testato query incentrate sulla posizione per i quattro settori principali. Utilizzando un framework sistematico a quattro quadranti (con brand/senza brand e oggettivo/soggettivo), i risultati mostrano differenze sostanziali nel modo in cui le piattaforme di IA reperiscono e citano le informazioni. Le variazioni tra settori, tipi di query e contesti dei consumatori confermano che l’analisi a livello locale è la nuova base strategica per la visibilità nell’ambito dell’IA.
Questa ricerca presenta un percorso chiaro e strategico per i brand per rafforzare la loro visibilità locale nell'IA.
Risultati principali
L'analisi a livello di posizione mostra modelli di citazioni e fonti che non sono rilevabili con gli attuali studi a livello di brand. Una catena retail potrebbe registrare a livello nazionale un tasso di citazioni di prima parte del 47%, ma un’analisi a livello locale potrebbe rivelare percentuali del 70% nei mercati rurali e solo del 20% in quelli urbani più competitivi, dove gli aggregatori sono più diffusi. Queste variazioni geografiche rendono le metriche nazionali meno utili per una strategia di visibilità locale.
- Il potere dei contenuti proprietari per le query basate sui fatti. Quando i consumatori pongono domande oggettive e senza brand (ad esempio, "Qual è la [categoria] più vicina a me?"). I siti web sono la fonte di citazioni dominante in tutti e tre i modelli, rappresentando oltre il 40% delle citazioni per Gemini, OpenAI e Perplexity. Questa è la più grande opportunità per i brand di controllare la loro narrazione fornendo informazioni chiare e precise attraverso i propri siti web.
- La forte dipendenza di OpenAI dalle directory per query soggettive. Quando una query diventa soggettiva (ad esempio, "Qual è il migliore...?"), il comportamento di OpenAI in materia di citazioni cambia radicalmente. Per le query soggettive sia con brand che senza brand, le directory di terze parti diventano una fonte primaria, con un picco del 46,3% per le domande soggettive con brand. Ciò significa che, per le domande basate su opinioni su OpenAI, la presenza di un brand nelle directory è fondamentale.
- L’attenzione di Perplexity per le directory di settore. Perplexity mostra costantemente una forte preferenza per le directory specifiche di settore, soprattutto per le query soggettive in cui la competenza rappresenta un fattore chiave. Per le query soggettive senza brand, queste directory specializzate rappresentano il 24% delle sue citazioni, la percentuale più alta di qualsiasi modello. Questo indica che, per Perplexity, l’ottimizzazione della presenza su piattaforme di nicchia e pertinenti per il proprio settore è una leva strategica fondamentale.
- Il potenziale inesplorato dei siti web locali. In quasi tutti i modelli e tipi di query, i siti web locali rappresentano regolarmente una fonte di citazione significativa, che va dall'8% a quasi il 20% in alcuni casi (obiettivo senza brand su Gemini). Questo sottolinea l’importanza strategica di mantenere pagine locali distinte e ricche di contenuti per ogni sede o punto vendita.
La ricerca IA dal punto di vista del consumatore
Considerare le citazioni dell'IA da una prospettiva generalizzata a livello di brand, come fa la maggior parte delle attuali ricerche sulla visibilità nella ricerca, lascia inesplorati gli aspetti della ricerca geospaziale. Una vera analisi a livello di brand deve tenere conto dei comportamenti reali degli utenti, aggregando query di IA granulari e basate sulla posizione nel loro contesto, un processo che rivela schemi di provenienza delle fonti molto più sfumati.
La visibilità nell'IA non è monolitica: il comportamento delle citazioni cambia in base alla posizione del consumatore, al contesto delle sue domande, al settore, al modello di IA e alle singole fonti di citazione.
La relazione tra il livello di controllo di un brand, lo sforzo richiesto e il conseguente utilizzo delle citazioni IA offre un potente framework per dare priorità alle azioni.
Il Location-Context Framework
La visibilità nell’ambito dell’IA deve essere compresa dal punto di vista del consumatore. Per studiare in modo sistematico i comportamenti dell’IA da questa prospettiva, abbiamo sviluppato il Location-Context Framework, un modello che parte dalla posizione del consumatore e tiene poi conto dei diversi tipi di domande per analizzare i modelli di citazione. Questo approccio si differenzia dalle ricerche attuali basate sull’analisi a livello di brand, che spesso utilizzano un metodo "espansione delle query" in cui l'IA genera domande successive. Sebbene utile per analisi di tipo descrittivo sui brand, questo metodo spiega perché spesso compaiono fonti generiche come Wikipedia o i forum: in questi casi, l’IA tende a fornire un commento generale invece di rispondere a bisogni specifici dei consumatori.
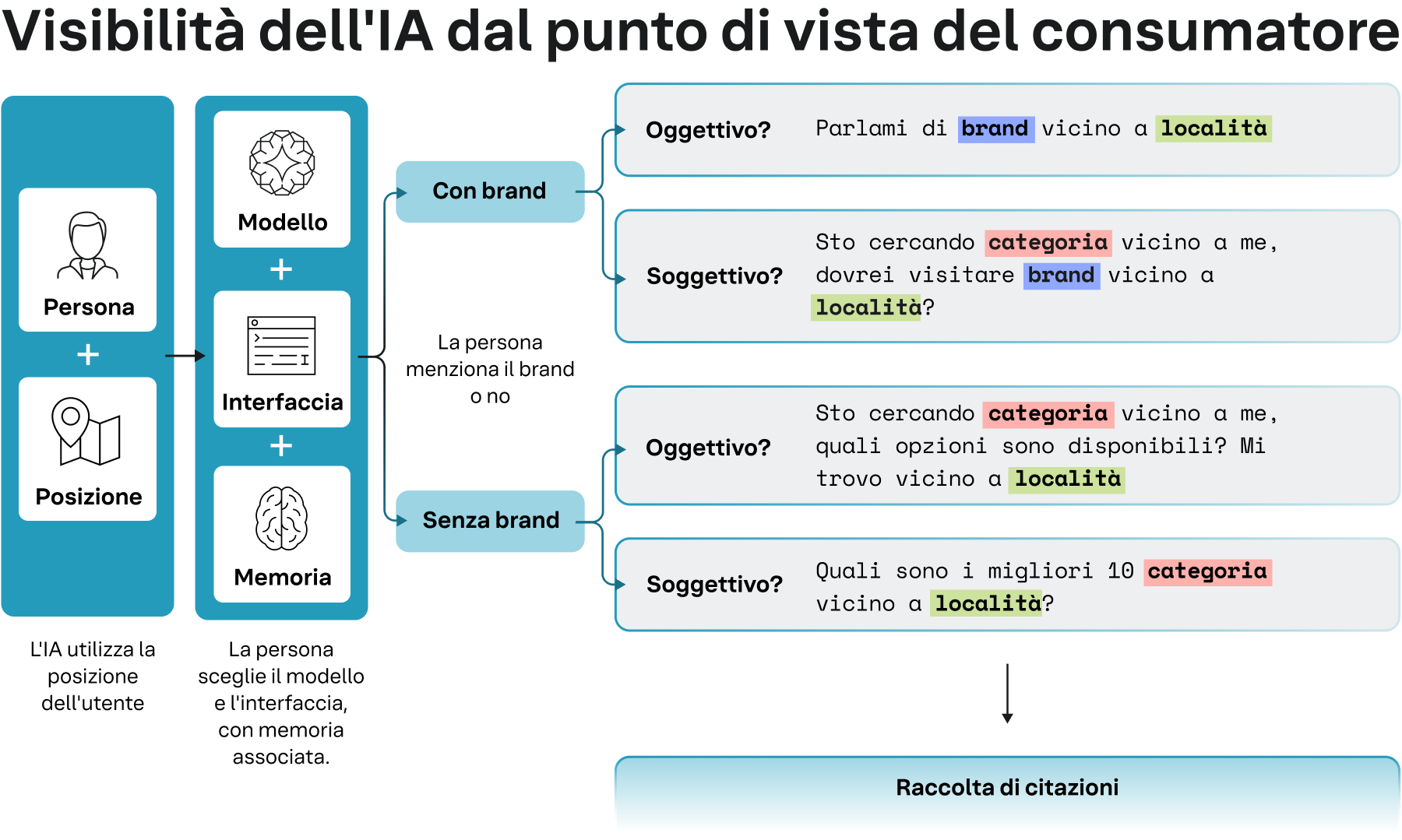 Figura 1: invece di un'espansione generata, il nostro Location-Context Framework segue un percorso chiaro e prevedibile.
Figura 1: invece di un'espansione generata, il nostro Location-Context Framework segue un percorso chiaro e prevedibile.
Il Location-Context Framework definisce un percorso chiaro e prevedibile che simula il comportamento del consumatore medio quando interagisce con un modello di IA su vari argomenti legati alla ricerca.
- Una persona ha un’esigenza e si trova in una posizione geografica specifica . L'IA utilizza questo contesto geografico come filtro fondamentale, simile alla ricerca classica (Google).
- Il consumatore sceglie un modello (come Gemini o ChatGPT) e un'interfaccia. Inoltre, apporta la propria memoria conversazionale alla sessione, che può influenzare le risposte successive.
- Infine, il consumatore formula la propria query secondo due dimensioni fondamentali : con brand o senza brand e oggettiva o soggettiva.
I nostri risultati mostrano un chiaro bilanciamento. man mano che aumenta il controllo di un brand su una fonte, cresce anche la probabilità che venga utilizzata come citazione nelle risposte generate dall’IA. Tuttavia, ciò richiede spesso un maggiore impegno. L'opportunità strategica sta nel trovare il giusto equilibrio. Mentre le fonti a “controllo totale”, come i siti web di prima parte, offrono la massima efficacia, le fonti “controllabili” su piattaforme di terze parti rappresentano un punto di forza cruciale: garantiscono un alto volume di citazioni con un livello di gestione moderato. Il framework che proponiamo consente ai brand di superare un approccio reattivo, concentrando in modo proattivo le proprie risorse sulle attività che avranno il maggiore impatto sulla visibilità nell’ambito dell’IA.
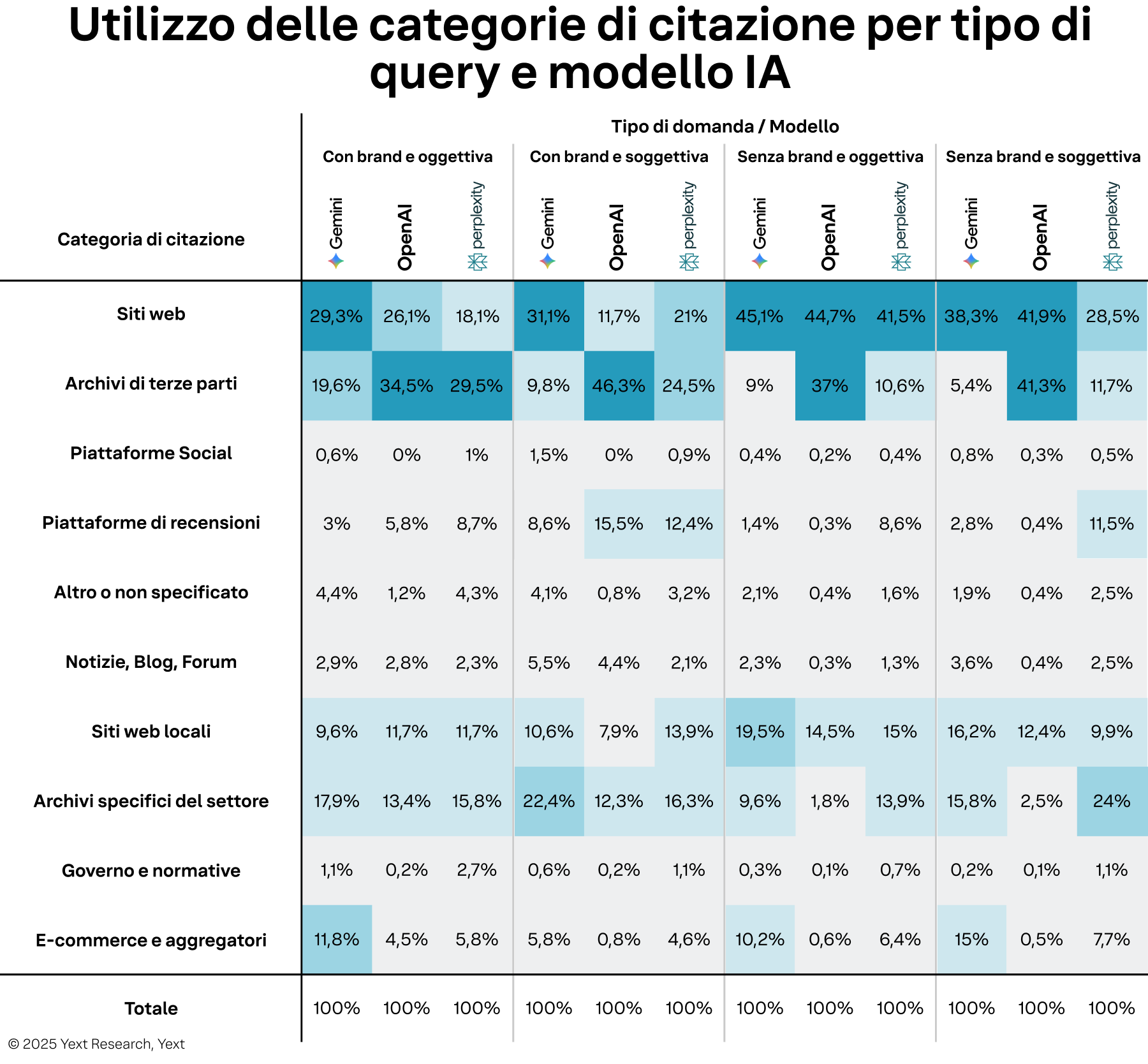 Tabella 1
Tabella 1
Sebbene molti studi a livello di brand indicano che forum come Reddit rappresentano una delle principali fonti di citazione, applicando una prospettiva basata sulla posizione del consumatore emerge un quadro diverso: queste fonti compaiono molto più raramente, rappresentando poco più del 2% (circa 154.000) delle citazioni complessive. Ciò non diminuisce la loro importanza per i commenti sui brand, ma dimostra che per le richieste dei consumatori legate a una posizione, il loro ruolo cambia.
Definizione delle fonti di citazione dell'IA in base al livello di controllo del brand
È necessario classificare le fonti di citazione in base alla capacità di un brand di controllare le informazioni che contengono. Il Framework di controllo ordina le fonti di citazione in quattro categorie distinte, che vanno da quelle interamente di proprietà del brand a quelle su cui non ha alcuna influenza diretta. Questa classificazione strategica consente a un brand di dare priorità ai propri sforzi, concentrando le risorse dove possono avere il massimo impatto.
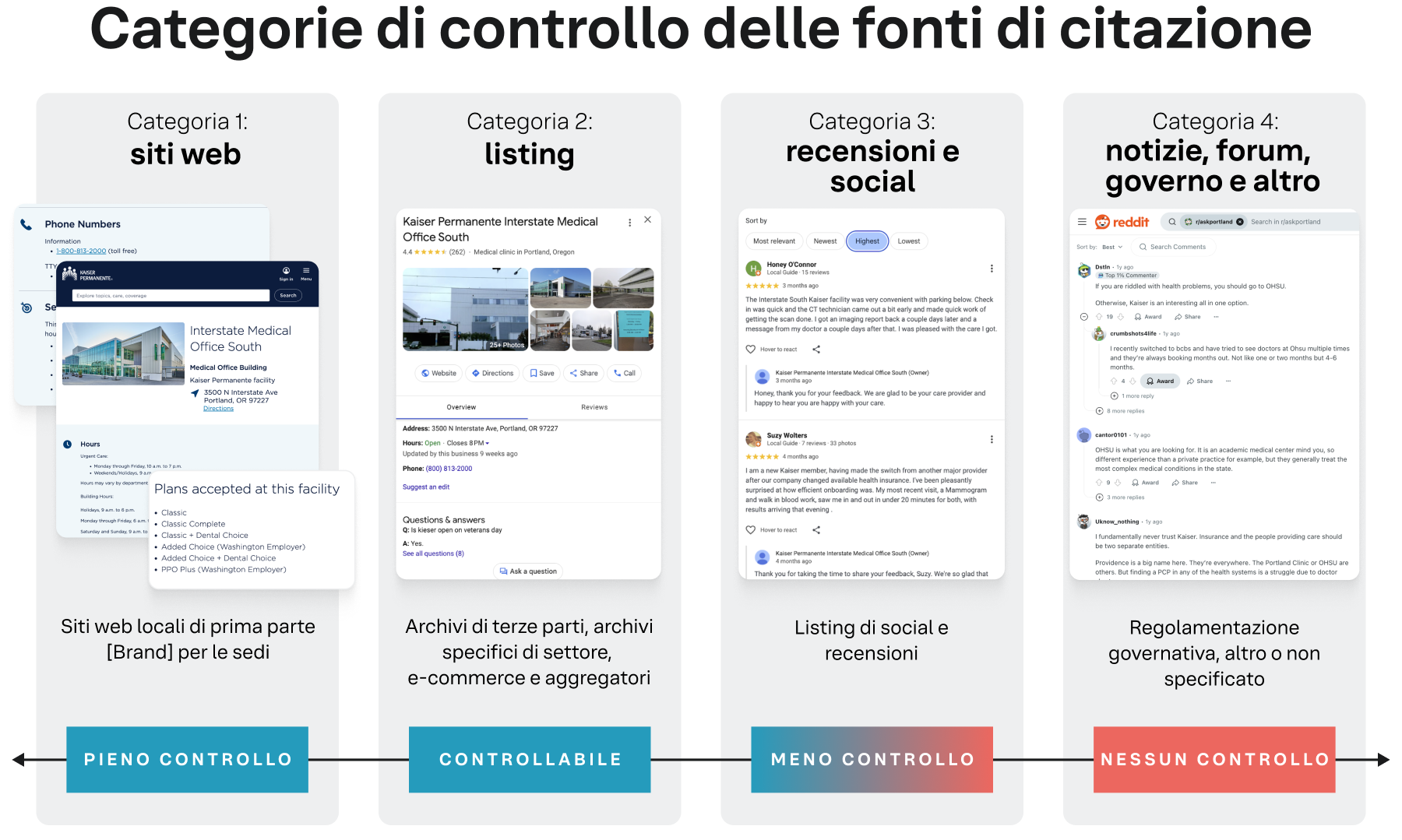 Figura 2
Figura 2
Categoria 1: controllo totale (siti web) comprende le proprietà digitali di prima parte di un brand. I brand hanno il pieno e diretto controllo su tutti i contenuti. Questa categoria è la più citata nello studio, con oltre 2,9 milioni di citazioni provenienti da domini aziendali (ad es. wendys.com), pagine delle sedi (ad es. locations.bankofamerica.com), e altre risorse web di proprietà del brand.
Categoria 2: controllabile (listings) comprende un'ampia gamma di directory e piattaforme di terze parti su cui un brand può rivendicare e gestire il proprio profilo. Pur non essendo proprietario della piattaforma, il brand può controllare direttamente l’accuratezza delle informazioni pubblicate. Questa categoria conta oltre 2,9 milioni di citazioni e include piattaforme che riguardano vari settori, il Profilo di Google Business e Mapquest, oltre a directory specifiche di settore come TripAdvisor (ristorazione/ospitalità) o Zocdoc (settore sanitario).
Categoria 3: influenzabile (recensioni e social) include piattaforme dove il contenuto è principalmente generato dagli utenti, ma i brand possono partecipare attivamente. Questa categoria è caratterizzata dalla reputazione e conta oltre 545.000 citazioni da fonti come le recensioni di Google, Yelp e Facebook.
Categoria 4: non controllata (notizie, forum, altro) comprende tutte le fonti su cui un brand non ha un controllo diretto. Un risultato interessante di questa ricerca è il numero relativamente basso di citazioni per questa categoria.
Il risultato più significativo emerso da questi dati è incoraggiante: i brand possono influenzare o gestire direttamente le fonti che rappresentano circa l’86% di tutte le citazioni visibili ai consumatori. Questo alto grado di controllo emerge solo passando da una prospettiva a livello di brand a una a livello di sede.
 Tabella 2
Tabella 2
Comprendendo i modelli di citazione a livello delle singole località dei consumatori, un brand può aggregare tali dati per sviluppare una strategia precisa e operativa volta a migliorare la propria visibilità nell’ambito dell’IA. Senza questa comprensione granulare, è quasi impossibile costruire un percorso chiaro per raggiungere il consumatore.
Differenze tra modelli
Il comportamento delle citazioni non è uniforme tra i vari modelli di IA, anzi, varia in modo significativo. Riteniamo che la strategia di visibilità di un brand debba tenere conto delle distinte preferenze di fonti di ciascuna piattaforma.
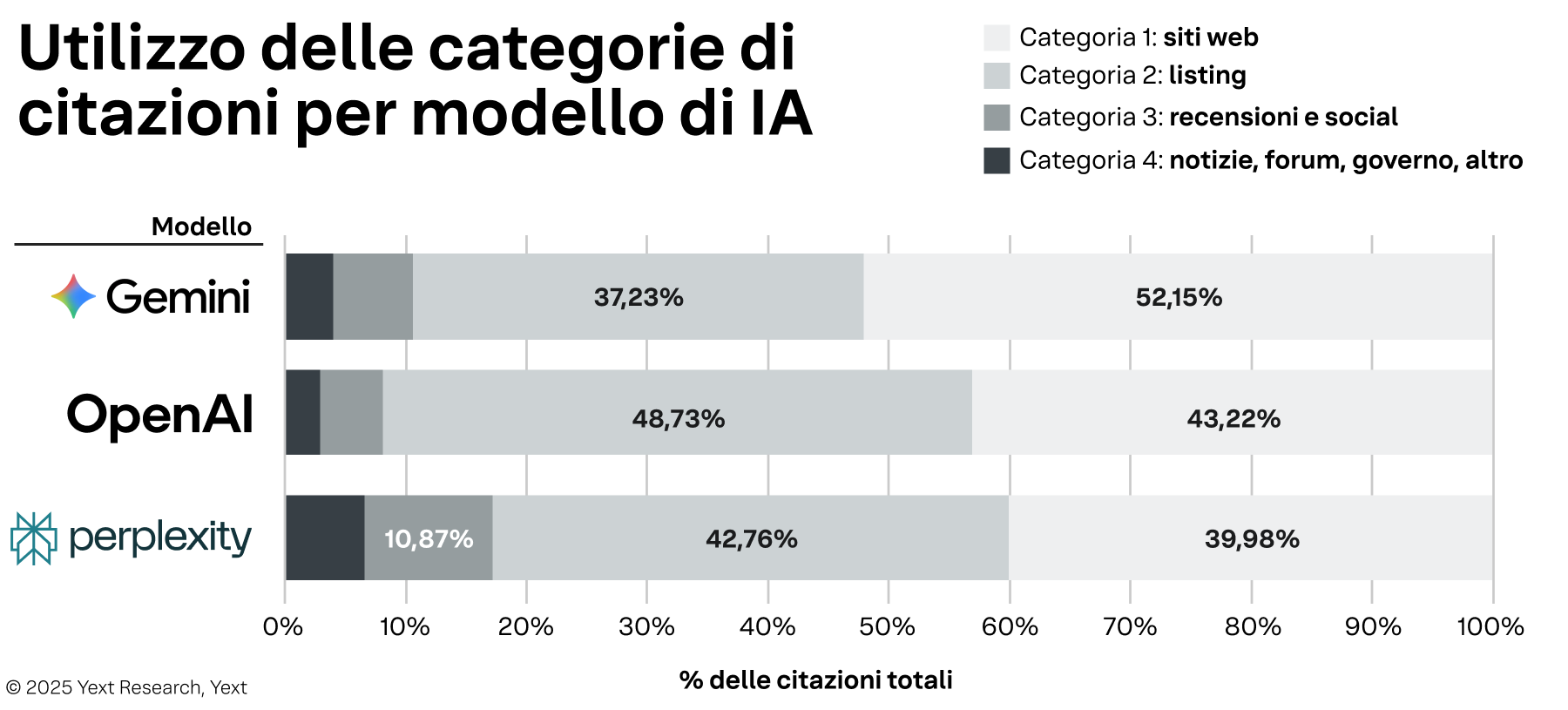 Figura 3
Figura 3
Esistono numerose differenze tra le fonti utilizzate da ciascun modello. Gemini mostra una netta preferenza per i siti web proprietari, che rappresentano il 52,15% delle sue citazioni e sono fonti sotto il pieno controllo del brand. Al contrario, OpenAI si affida ai listing, che rappresentano il 48,73% delle sue citazioni e provengono da piattaforme di terze parti controllabili. Queste preferenze diventano ancora più marcate quando si esaminano i singoli domini. Il ricorso di OpenAI ai listing si concentra soprattutto su Google, con un totale di oltre 465.000 citazioni. Perplexity, invece, diversifica le sue fonti, privilegiando MapQuest per i listing (oltre 364.000 citazioni) e TripAdvisor per le recensioni (oltre 239.000 citazioni).
È anche importante notare ciò che non viene conteggiato come citazione. Gemini, per esempio, utilizza le informazioni del Profilo di Google Business nelle sue risposte, ma non le cita come fonte perché sono dati proprietari.
Queste sfumature comportamentali significano che la presenza di un brand in un modello non ne garantisce la visibilità in un altro, un argomento che verrà esplorato in un'analisi successiva.
Differenze per settore
Analogamente ai nostri risultati precedenti quando abbiamo esaminato i profili di Google Business, le citazioni dell'IA per verticale rivelano modelli di comportamento distinti.
Sarebbe ingenuo presumere un comportamento omogeneo tra i diversi settori. Abbiamo riscontrato fin da subito una combinazione unica di fonti di citazione per ciascun settore. Il mix tra siti di proprietà del brand (Categoria 1) e fonti di terze parti (Categorie 3-4) determina, in ultima analisi, il grado di controllo che un’azienda può esercitare sulla propria narrazione nei risultati generati dall’IA.
(Nota: i report approfonditi per settore finanziario, servizi di ristorazione, settore sanitario e vendita al dettaglio saranno pubblicati separatamente.)
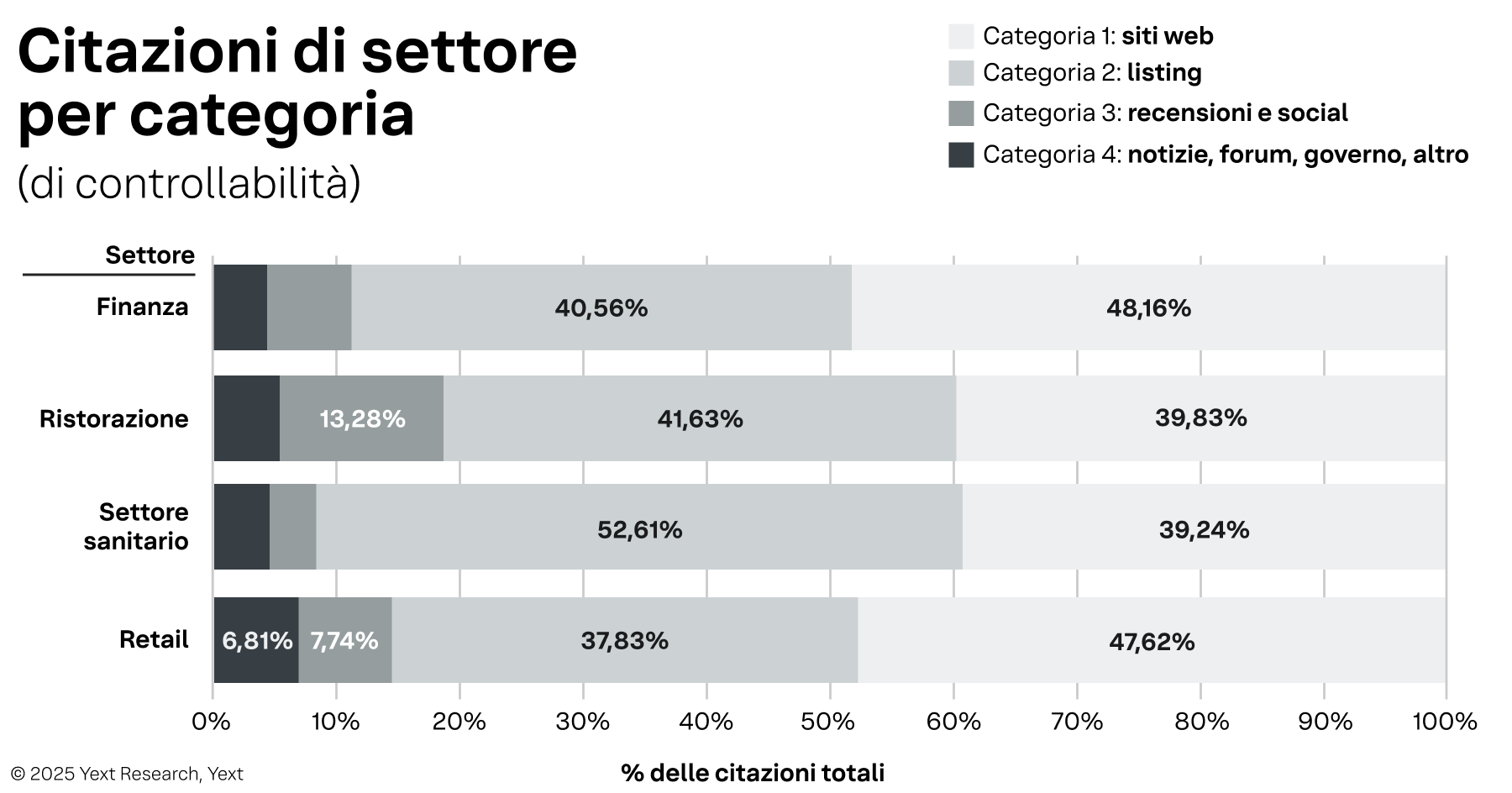 Figura 4
Figura 4
Differenze significative per settore:
- Servizi finanziari e vendita al dettaglio mostrano maggiore potenziale di controllo diretto, con i siti web (categoria 1) che rappresentano rispettivamente il 48,16% e il 47,62% delle citazioni. La natura regolamentata della finanza e l'infrastruttura di e-commerce della vendita al dettaglio spingono i modelli di IA verso fonti autorevoli e di proprietà del brand.
- Il settore sanitario mostra invece la maggiore dipendenza da fonti di terze parti, con i listing (categoria 2) che rappresentano il 52,61% di tutte le citazioni. Ciò riflette l’importanza di directory mediche, database di licenze e piattaforme assicurative nel rafforzare la fiducia.
- Il settore della ristorazione rappresenta una sfida unica, con una dipendenza significativa sia dai listing (41,63%) che dalle recensioni (13,28%). La quota di citazioni proveniente da fonti di Categoria 3 (13,28%) è la più alta tra tutti i settori, a dimostrazione del fatto che, per i brand della ristorazione, la reputazione e i contenuti generati dagli utenti sono fattori cruciali per la visibilità nell’ambito dell’IA.
Metodologia
Questa ricerca si basa sull’analisi di 6,8 milioni di citazioni raccolte dalle risposte dei risultati di ricerca generati dall’IA tra il 1º luglio 2025 e il 31 agosto 2025. I dati sono stati raccolti da uno studio globale condotto su clienti e potenziali clienti di Yext che utilizzano la piattaforma Yext Scout. Sebbene i dati provengano da un gruppo di utenti specifico, l'ampiezza delle fonti citate è notevole e comprende una lunga lista di 20.820 domini univoci.
Utilizzando un sistema automatizzato, sono state poste circa 1,6 milioni di domande individuali a ciascuno dei tre principali modelli di IA: Gemini, OpenAI e Perplexity. Le domande sono state progettate per rappresentare quattro distinti quadranti delle intenzioni dei consumatori (oggettive con brand, soggettive con brand, oggettive senza brand e soggettive senza brand), e sono state testate in tutte le sedi di clienti e prospect appartenenti a quattro settori chiave: finanza, ristorazione, sanità e retail. Questi dati sono stati raccolti utilizzando le singole API fornite da ciascun modello.
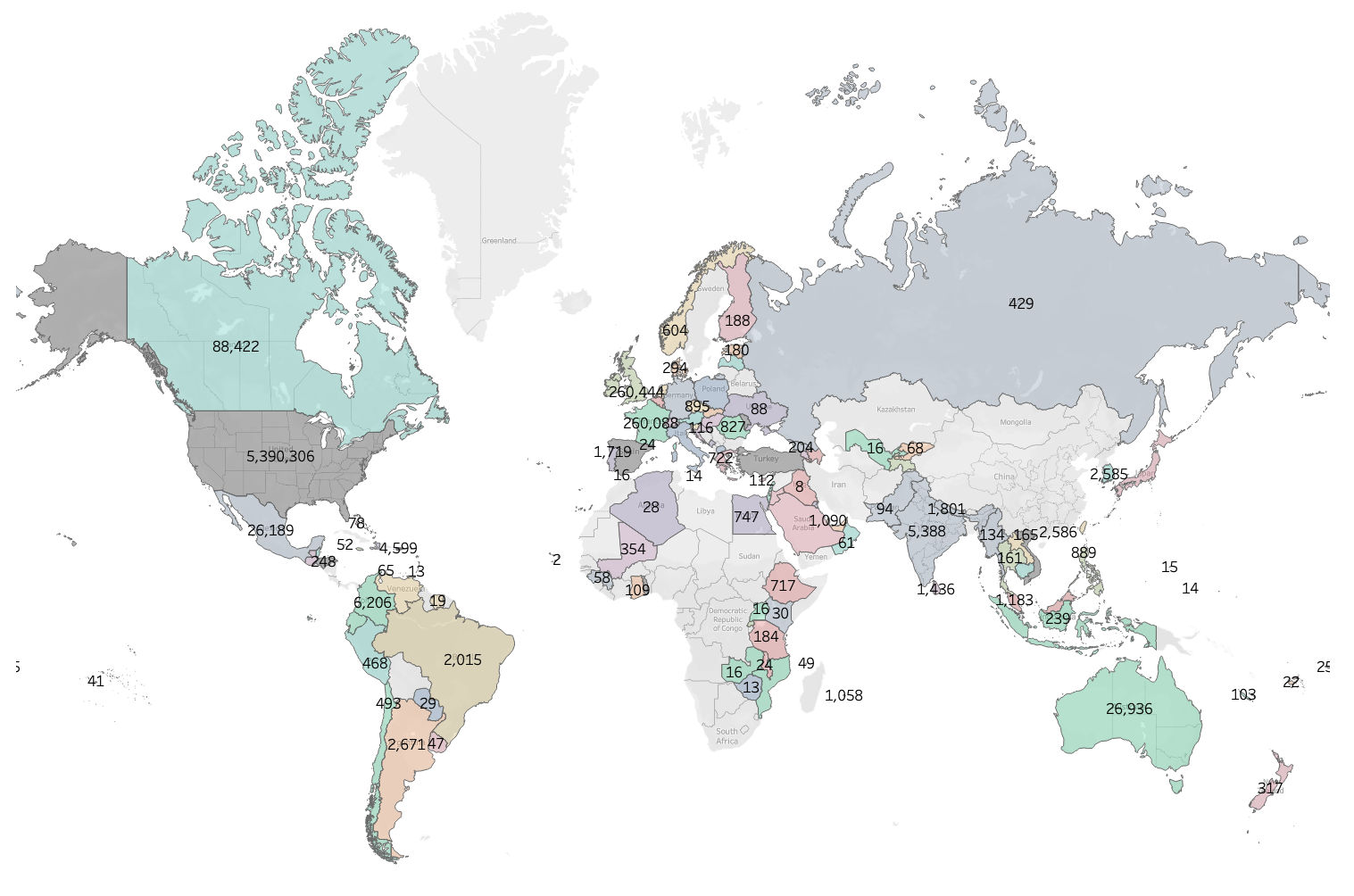
Figura 5: questo studio ha raccolto 6,8 milioni di citazioni a livello globale.
L'impatto della geolocalizzazione sulla ricerca IA
I modelli di Google, OpenAI e Perplexity confermano di tenere conto della posizione geografica del consumatore nelle loro risposte relative ad aziende e servizi. Riteniamo che questo elemento non sia secondario, ma parte integrante del modo in cui questi sistemi determinano la rilevanza delle informazioni. Proprio come un motore di ricerca tradizionale mostra per impostazione predefinita i ristoranti nelle vicinanze quando digiti "pizza", i modelli di IA di oggi utilizzano i segnali di geolocalizzazione per ancorare le loro risposte allo spazio fisico. Che l'input provenga da un indirizzo IP, dalle impostazioni del dispositivo o da una richiesta esplicita dell'utente, la posizione sembra essere un fattore rilevante nel calcolo del modello di ciò che costituisce una risposta utile.
L’effetto è sottile, ma significativo. Due persone che pongono la stessa domanda da posizioni diverse possono ricevere risposte diverse, determinate dai dati aziendali locali, dalla copertura dei servizi e persino dall'uso della lingua regionale. Ciò significa che la ricerca nell'era dell'IA non è più un processo di risoluzione delle query puramente astratto. La ricerca potenziata dall'IA è inestricabilmente legata alla posizione dell'utente e al grafo di conoscenza locale in questione.
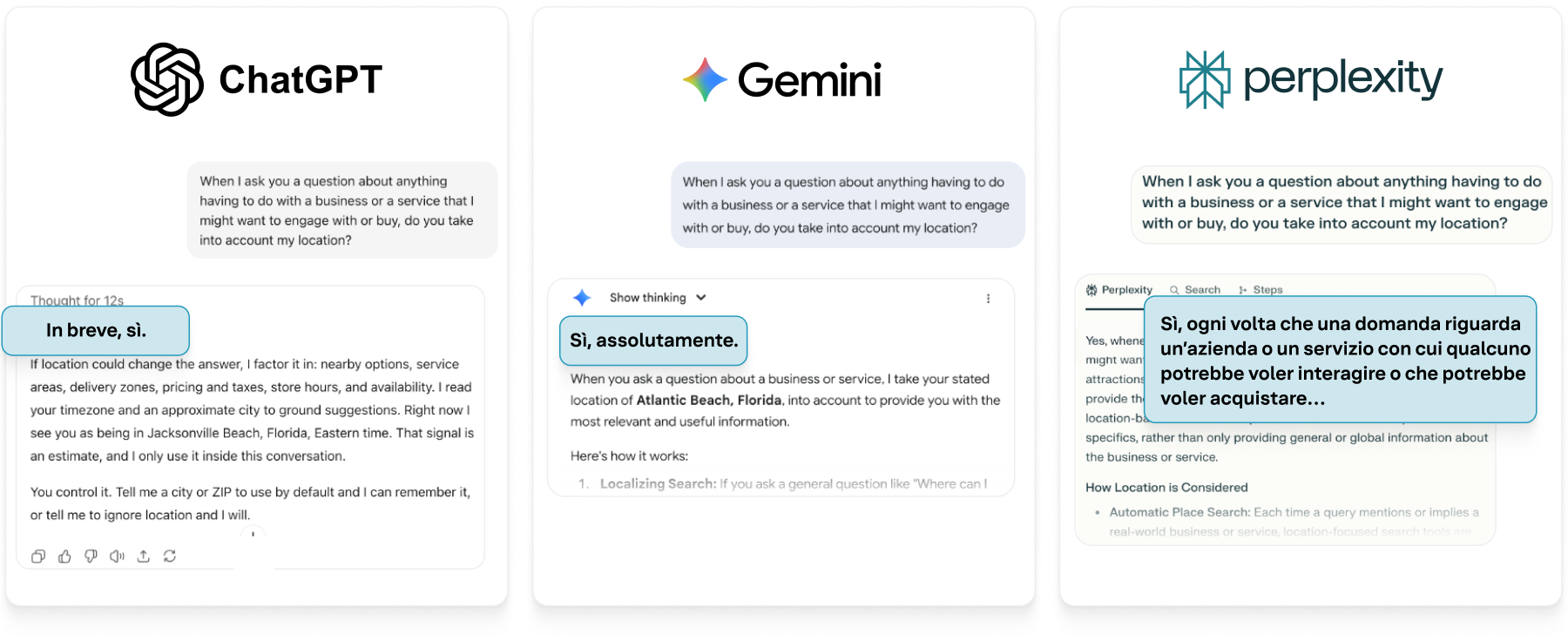 Figura 6: tutti e tre i principali modelli di IA considerano la posizione come parte del loro processo RAG.
Figura 6: tutti e tre i principali modelli di IA considerano la posizione come parte del loro processo RAG.
Classificazione delle query in base all'intento
Introduciamo un approccio strutturato per determinare i tipi di query in relazione all'intento di base. Il Framework di classificazione delle query (QCF), presenta quattro quadranti di query distinti che riflettono il vero comportamento dei consumatori e producono diversi modelli di citazione. Le domande oggettive cercano informazioni concrete, come "[Pizzeria] vicino a me". Le domande soggettive cercano opinioni, come "Quali sono le 10 migliori [pizzerie] vicino a [posizione]?". Questo framework consente un'analisi più precisa di come i modelli di IA rispondono alle reali esigenze dei consumatori.
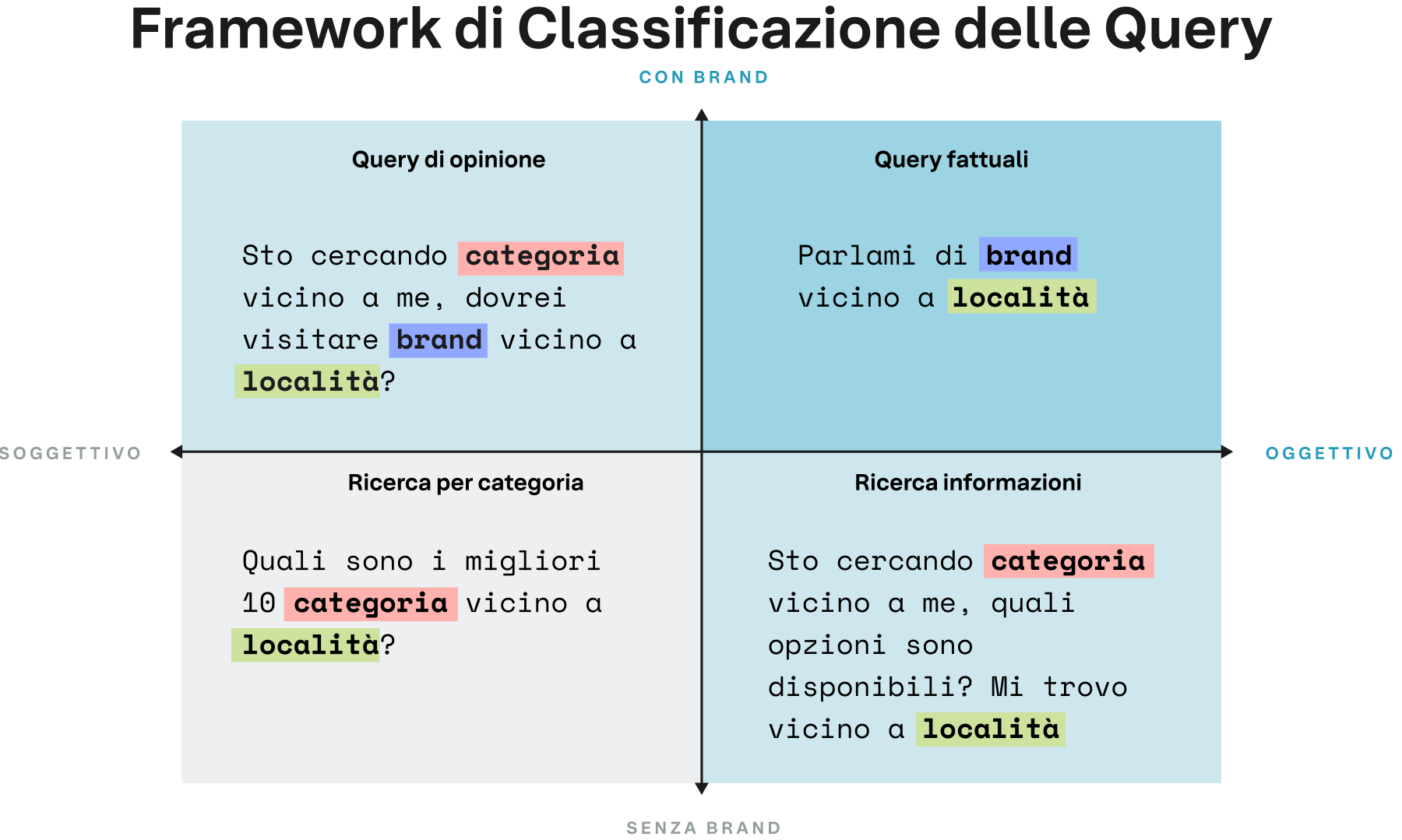 Figura 7
Figura 7
Come mostrato, le citazioni monitorate nei diversi tipi di query risultano per lo più distribuite in modo uniforme, anche se emergono variazioni più significative tra i settori. La struttura di questo framework consente di andare oltre una semplice analisi aggregata: monitorando i risultati dei singoli tipi di domande per ciascun modello, questa ricerca è in grado di identificare con precisione quali fonti di citazione preferisca ogni modello di IA in base alla posizione del consumatore, alla sua query specifica e al contesto del settore.
Applicando il QCF al nostro set di query/citazioni, arriviamo a una distribuzione per lo più uniforme. Ci sono alcune differenze evidenti tra i settori quando si tratta di "domande oggettive".
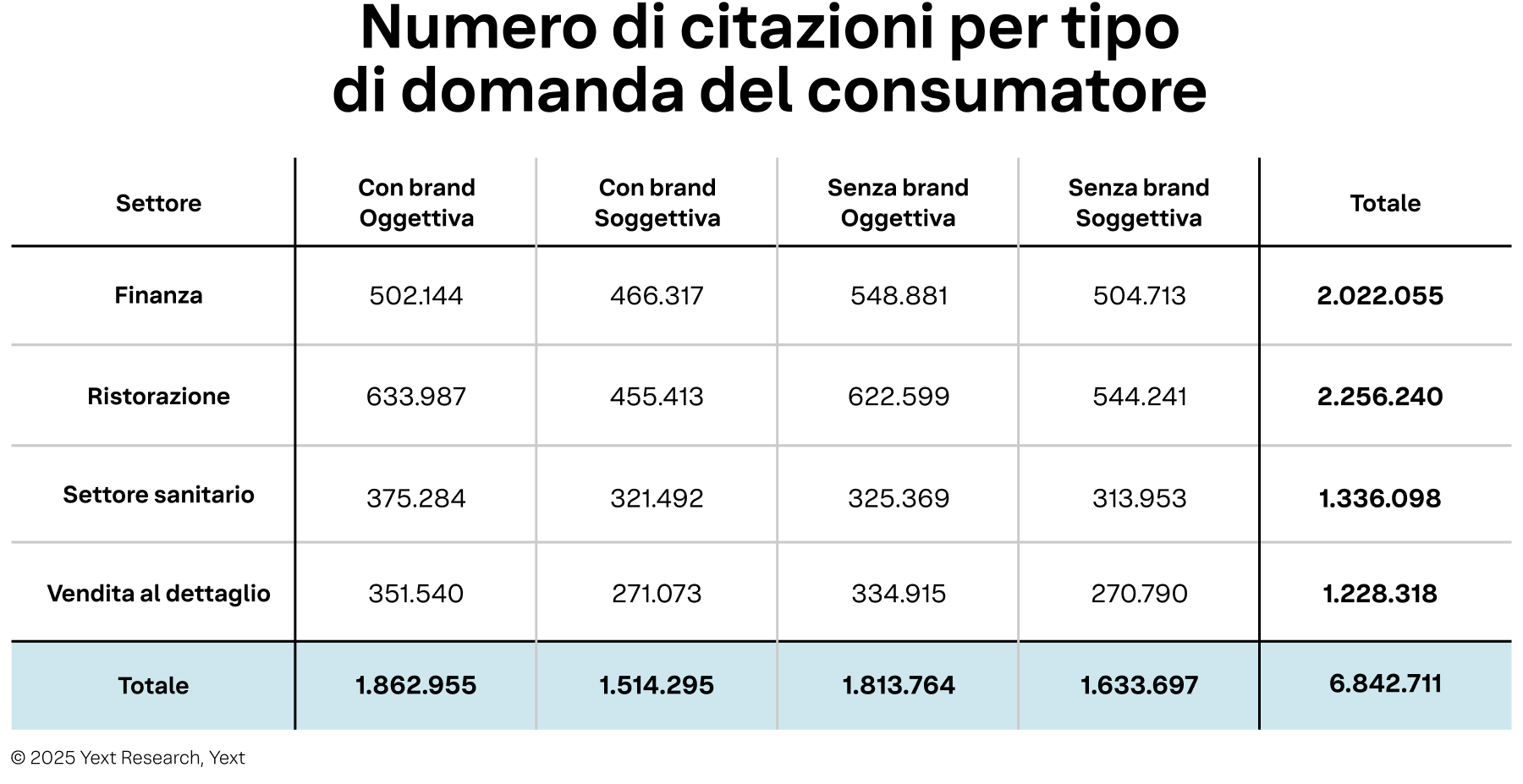 Tabella 3
Tabella 3
Limitazioni e ricerche future
Questa analisi si basa sui dati dei clienti e potenziali clienti di Yext, che comprendono oltre 200.000 sedi in cui operano o potrebbero operare. La piattaforma Yext Scout importa direttamente tutte le citazioni disponibili dalle API dei singoli modelli di IA. È importante riconoscere le differenze tra le citazioni ottenute tramite un'API e quelle presentate in un'applicazione utente diretta. La volatilità intrinseca dei modelli linguistici di grandi dimensioni significa che il contesto conversazionale di un individuo, l'uso specifico del modello e la memoria conversazionale possono influenzare le risposte. Di conseguenza, possono verificarsi variazioni sostanziali da un utente all'altro. Tuttavia, analizzando migliaia di richieste contestuali per brand e aziende, riteniamo che i modelli di citazione risultanti siano probabilmente indicativi di modelli di utilizzo generali all'interno di una posizione geografica specifica.
Aree di approfondimento per ricerche future
I risultati di questo report aprono diverse strade per una ricerca più granulare. Le analisi future includeranno:
- Approfondimenti specifici per modello: un’analisi dettagliata delle tendenze di citazione per ciascun modello di IA, che approfondirà le principali differenze individuate in questo report e sarà pubblicata nei prossimi sotto-report.
- Report secondari di settore: analisi dei domini specifici e delle fonti di citazione che appaiono più frequentemente all'interno nei singoli report di settore relativi a finanza, ristorazione, settore sanitario e vendita al dettaglio.
- Analisi della variazione geografica: un'analisi quantitativa di come i modelli di citazione differiscono tra i tipi di mercato geografici, come i centri urbani più popolati e le aree più rurali, per approfondire le osservazioni iniziali di questo studio.
- Monitoraggio longitudinale: monitoraggio continuo delle fonti di citazione per capire come si evolvono le tendenze man mano che i modelli di IA vengono aggiornati e riaddestrati nel tempo.
Conclusione
I risultati di questa ricerca stabiliscono una nuova prospettiva sulla visibilità nell'ambito dell'IA. Un’analisi generica a livello di brand non è più sufficiente, perché non riesce a cogliere i modelli di provenienza delle fonti che emergono dalle query reali dei consumatori. Una comprensione autentica deve partire dal basso, aggregando dati granulari basati sulla posizione, in grado di riflettere il contesto specifico delle esigenze dei consumatori.
Questo approccio basato sulla posizione rivela un percorso logico da seguire. Mentre le analisi tradizionali a livello di brand tendono a evidenziare un’ampia varietà di fonti non controllate, questo studio dimostra che, per query specifiche dei consumatori, i modelli di IA si affidano a un insieme di informazioni più strutturato. I brand possono controllare o influenzare direttamente la maggior parte di queste fonti. La strategia più efficace consiste in una gestione mirata dei siti web di prima parte, delle schede di terze parti e della reputazione online.
Questo studio, basato su due mesi di dati provenienti da clienti e potenziali clienti della piattaforma Yext Scout, è solo l'inizio.
Con l’evoluzione dei modelli di IA, questo metodo di analisi a livello di posizione offrirà un approccio solido e orientato al cliente per valutare le performance dei brand nella ricerca basata sull’IA.