KI-Zitierungsverhalten über Modelle hinweg: Erkenntnisse aus 17,2 Millionen Zitierungen
Jedes KI-Modell zitiert anders. Das ist wichtiger, als den meisten Unternehmen bewusst ist.
Kurzfassung
Wenn Verbraucher*innen ein KI-Modell über ein Unternehmen befragen, hängt die Antwort, die sie erhalten, stark davon ab, welches Modell sie fragen. Nicht weil die Modelle unterschiedliche Dinge wissen, sondern weil sie ihre Informationen aus verschiedenen Quellen in unterschiedlichem Umfang und in je nach Branche variierenden Mustern beziehen.
Unsere Analyse von 17,2 Millionen verschiedenen KI-Zitierungen im vierten Quartal 2025 zeigt, dass das Zitierungsverhalten vorhersehbaren, modellspezifischen Mustern folgt. Diese Studie baut auf früheren Arbeiten aus dem Jahr 2025 auf, bei denen wir 6,9 Millionen Zitierungen ausgewertet und unser Standort-Kontext-Framework entwickelt haben.
Drei Ergebnisse stechen hervor:
-
Zitierungsmuster variieren stärker innerhalb der Sektoren als sektorenübergreifend. „Restaurants“ und „Feinkostläden und Cafés“ gehören zum selben Sektor (Lebensmittel und Getränke), weisen jedoch deutlich unterschiedliche Zitierungsprofile auf. Rein sektorale Analysen übersehen dies oft.
-
Claude verlässt sich viel mehr auf nutzergenerierten Inhalt als andere Modelle. Die Zitierungsrate von „Eingeschränkte Kontrolle“ (Rezensionen, soziale Medien) ist in allen sieben von uns untersuchten Sektoren 2–4 mal höher als bei konkurrierenden Modellen. Das ist kein Zufall in einer einzelnen Kategorie. Es ist konsistent.
-
SearchGPT behandelt Hotel-Websites ganz anders. SearchGPT zitiert offizielle Hotel-Websites zu 38,1 %, während konkurrierende Modelle zwischen 16,7 % und 22,4 % liegen. Dies ist die größte Abweichung zwischen einzelnen Modellen, die wir jemals in einem Sektor beobachtet haben.
Die praktische Implikation ist, dass es nicht nur eine einzige „KI-Optimierung“-Strategie gibt. Der Quellenmix, der eine Marke in Gemini sichtbar macht, ist nicht derselbe Mix, der sie in Claude sichtbar macht. Unternehmen, die die KI-Suche als ein monolithisches System betrachten, optimieren für einen Durchschnitt, der nicht existiert.
Einführung
Unsere aktuelle Studie „Rise of AI Search Archetypes“ (Der Aufstieg von KI-Such-Archetypen), eine globale Umfrage unter 2.237 Verbraucher*innen in den USA, Großbritannien, Frankreich und Deutschland, ergab, dass 75 % der Verbraucher*innen heute KI-Tools häufiger verwenden als vor einem Jahr und fast die Hälfte täglich die KI-Suche nutzt.
Diese Veränderung ist wichtig, weil die KI-Suche anders funktioniert als die herkömmliche Suche. In der traditionellen Suche konkurrieren Marken um Platzierungen auf einer Ergebnisseite. Bei der KI-Suche synthetisiert das Modell eine Antwort und gibt seine Quellen an. Sichtbarkeit hängt davon ab, ob man zitiert wird, nicht davon, ob man in einem Ranking aufgeführt wird. Und wie diese Studie zeigt, zitieren verschiedene Modelle unterschiedliche Quellen.
Dadurch entsteht ein Problem, das die meisten Unternehmen noch nicht vollständig verstanden haben. Eine Marke könnte in Gemini (das sich stark auf Websites von Erstanbietern stützt) eine hervorragende Sichtbarkeit haben und in Claude (das mehr aus Bewertungen und sozialen Inhalten schöpft) nahezu unsichtbar sein. Die „KI-Suchstrategie” der Marke könnte für ein Modell perfekt funktionieren und für ein anderes Modell fehlschlagen, und ohne Daten auf Modellebene hätte die Marke keine Möglichkeit, dies zu erkennen.
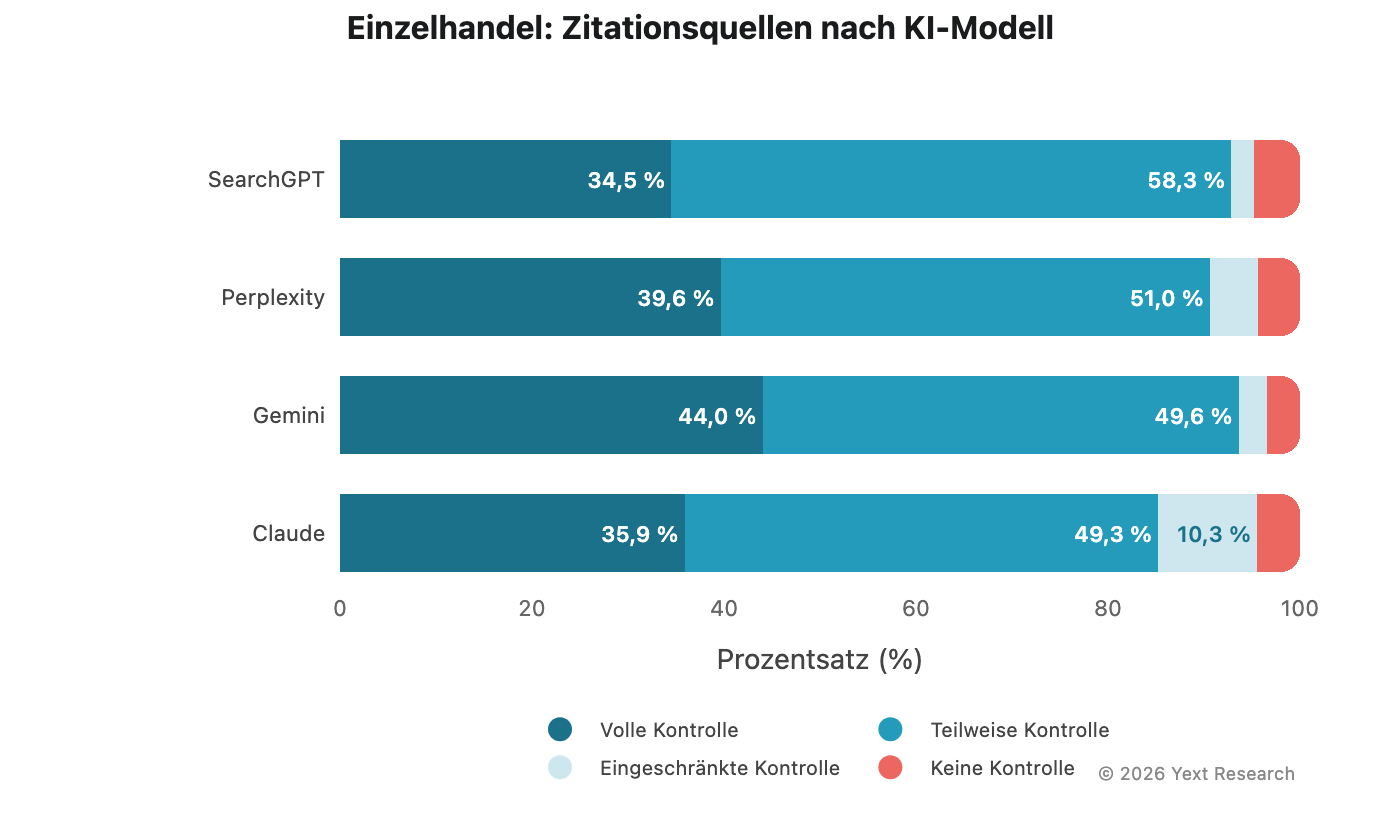
Diese Untersuchung analysiert, wie die vier großen KI-Modelle ihre Zitierungen beziehen, welche Muster in sieben Sektoren und zahlreichen Branchen auftreten und wo die Unterschiede zwischen den Modellen signifikant sind.

Methode
Sammlung von Zitierungsdaten
Diese Analyse untersucht 17,2 Millionen verschiedene KI-Zitierungen, die im vierten Quartal 2025 weltweit über vier wichtige KI-Modelle hinweg gesammelt wurden. Die Daten wurden mithilfe der Yext Scout-Plattform erhoben.
Die Anfragen wurden so strukturiert, dass vier Intention-Quadranten getestet werden konnten: markenspezifisch objektiv, markenspezifisch subjektiv, markenneutral objektiv und markenneutral subjektiv. Daten wurden auf Standortebene statt auf Markenebene erfasst, wodurch geografische und kontextuelle Variationen berücksichtigt werden, die nationale Studien auf Markenebene übersehen.
Rahmenwerk für Kontrollkategorien
Jede Zitierungsquelle wurde aus vier Arten von Fragen abgeleitet, die wir jedem Modell auf der Grundlage unseres Standort-Kontext-Frameworks gestellt haben.
| Kontrollniveau | Definition | Beispiele |
|---|---|---|
| Volle Kontrolle | Content, der vollständig vom Unternehmen erstellt und gehostet wird | Offizielle Websites, eigene Blogs, Unternehmensredaktionen |
| Teilweise Kontrolle | Drittanbieterplattformen, auf denen die Marke ihr Profil verwalten kann | Google Unternehmensprofil, MapQuest, TripAdvisor, Zocdoc |
| Eingeschränkte Kontrolle | Nutzergenerierte Plattformen mit Markenbeteiligung | Google Rezensionen, Yelp, Facebook, soziale Medien |
| Keine Kontrolle | Unabhängige Quellen ohne geschäftlichen Einfluss | Nachrichtenartikel, Reddit, Foren und unabhängige Publikationen |
Die Gesamtaufschlüsselung aller Zitierungen:
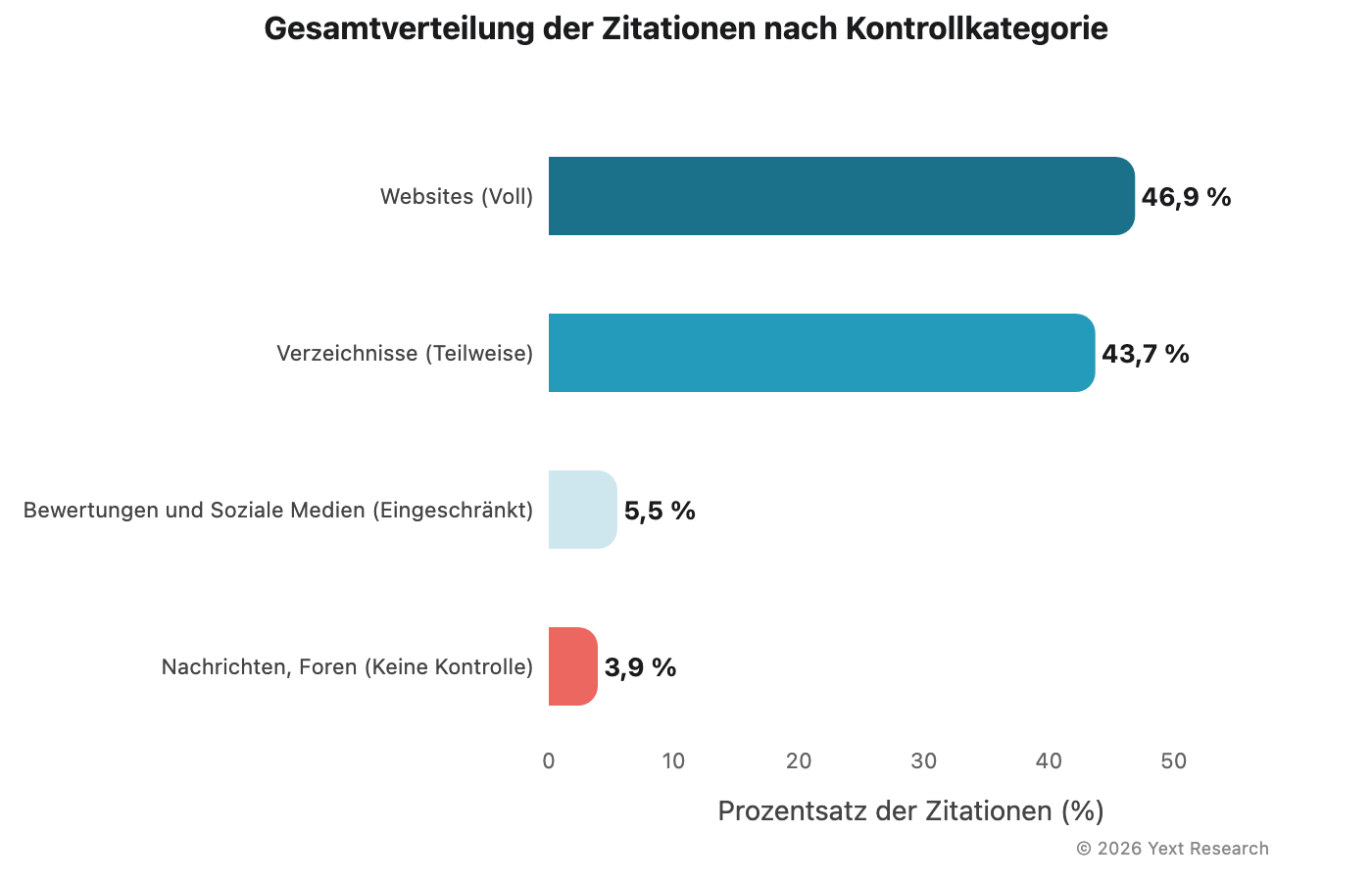
Eines fällt besonders auf: Listings machen den größten Anteil der eindeutigen URLs aus (54,53 %), aber Websites generieren weitaus mehr Zitierungen pro URL (4,31-mal gegenüber 2,46-mal). KI-Modelle greifen häufiger auf Inhalte von Erstanbietern zurück als auf einzelne Listings.
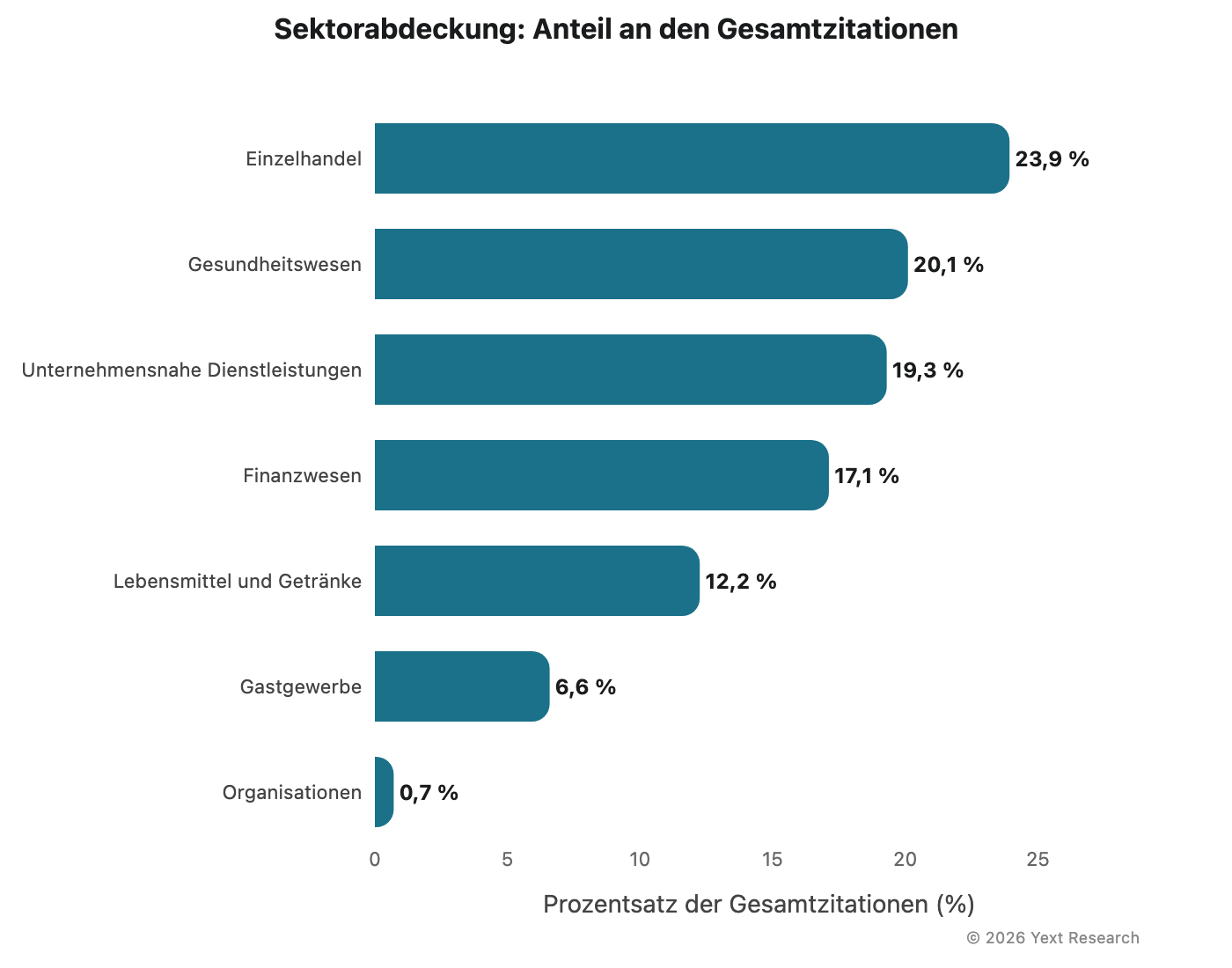
Sektorabdeckung
Die Analyse umfasst sieben Sektoren:
Ergebnisse
Abbildung 1: Zitierungsmuster auf Modell-Ebene
Jedes KI-Modell zeigt konsistente Zitierungspräferenzen, die über alle Branchen hinweg bestehen, wenn auch in unterschiedlichem Ausmaß.
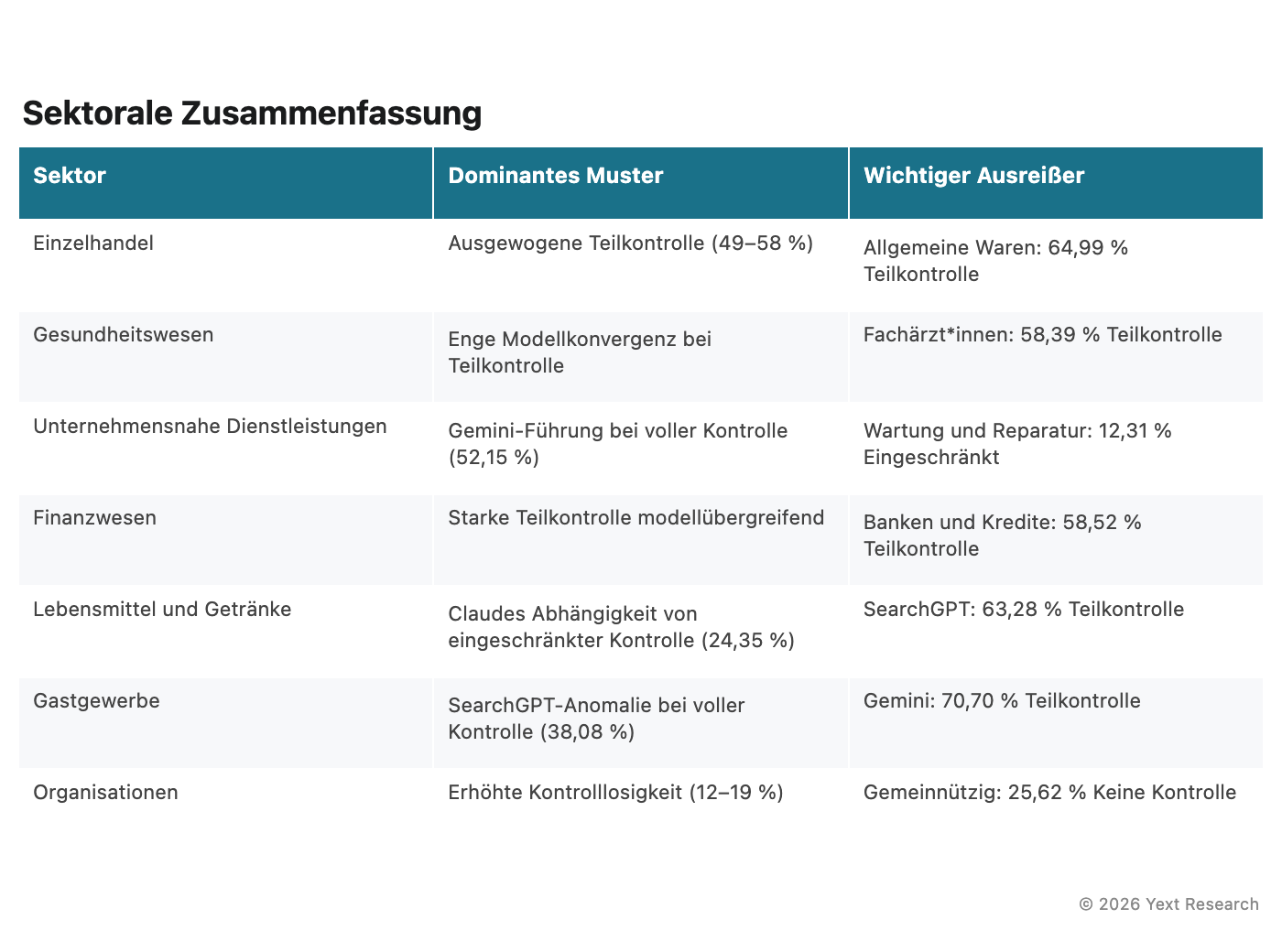
Gemini weist in den meisten Sektoren die stärkste Präferenz für die „Volle Kontrolle“ auf, die von 22,4 % (Gastgewerbe) bis 54,0 % (Organisationen) reicht. Dies spiegelt wahrscheinlich die Integration von E-E-A-T-Signalen durch Google in die Zitierungslogik von Gemini wider, die wir im Architekturabschnitt näher erläutern.
Bei Claude ist die Abhängigkeit von „Eingeschränkte Kontrolle“ durchweg hoch und reicht von 6,3 % (Organisationen) bis 24,4 % (Lebensmittel und Getränke). Das ist 2- bis 4-mal höher als bei anderen Modellen in den meisten Branchen.
Perplexity zeigt das konsistenteste Verhalten über alle Branchen hinweg, wobei die Präferenzen für „Volle Kontrolle“ in den meisten Branchen zwischen 37–50 % liegen. Die Stabilität scheint in die suchorientierte Architektur eingebettet zu sein.
SearchGPT weist die größte Varianz nach Branche auf, wobei „Volle Kontrolle“ zwischen 28,2 % (Lebensmittel und Getränke) und 43,7 % (Organisationen) liegt, mit einem bemerkenswerten Anstieg im Gastgewerbe auf 38,1 %.
Abbildung 2: Die Gastgewerbe-Anomalie von SearchGPT
Der Bereich „Gastgewerbe“ weist die dramatischste Modelldivergenz im Datensatz auf:
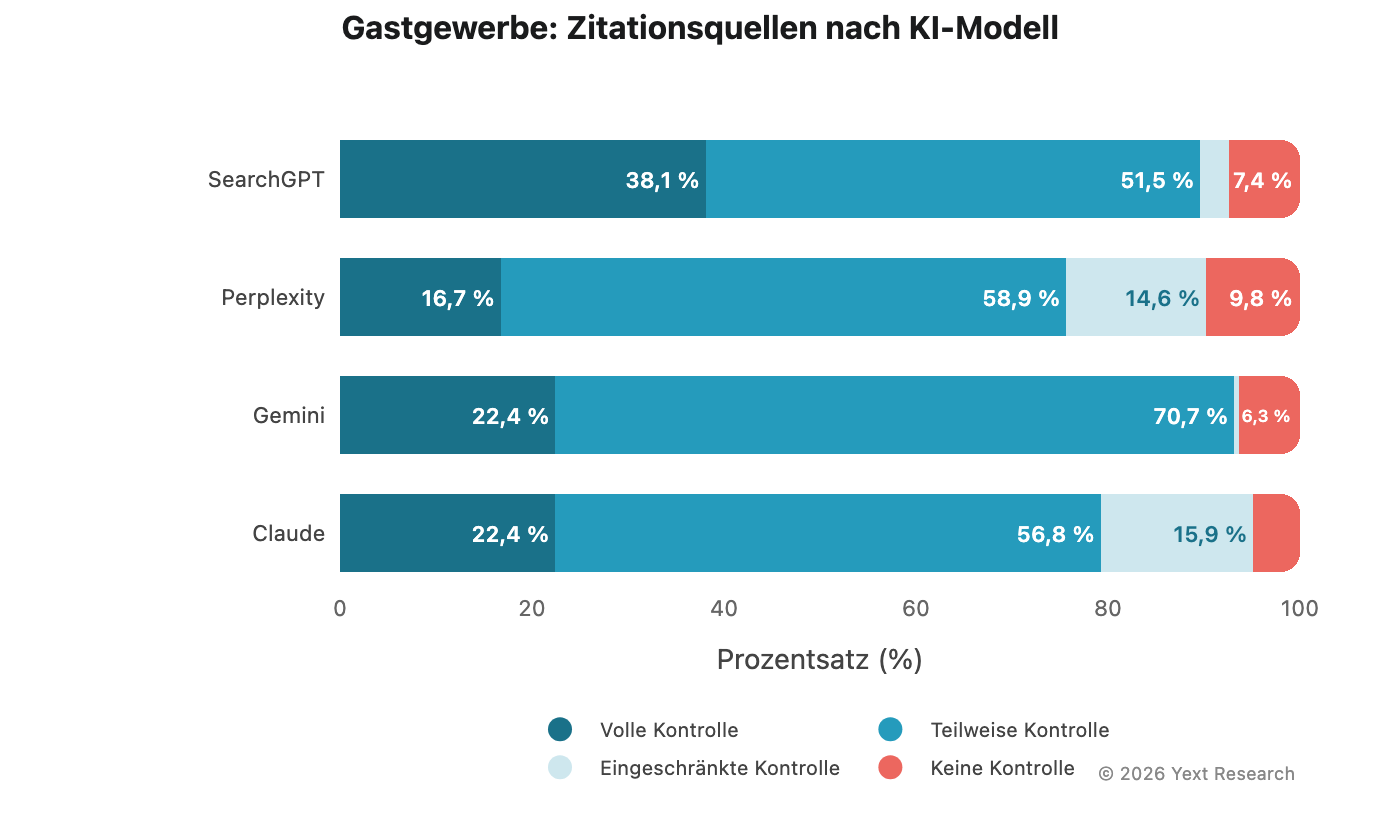
Der Marktanteil von SearchGPT bei „Volle Kontrolle“ liegt bei 38,1 % und ist damit etwa doppelt so hoch wie bei anderen Modellen in diesem Sektor. Dieses Muster lässt sich auch auf Branchenebene im Gastgewerbe beobachten.
Branchenaufschlüsselung:
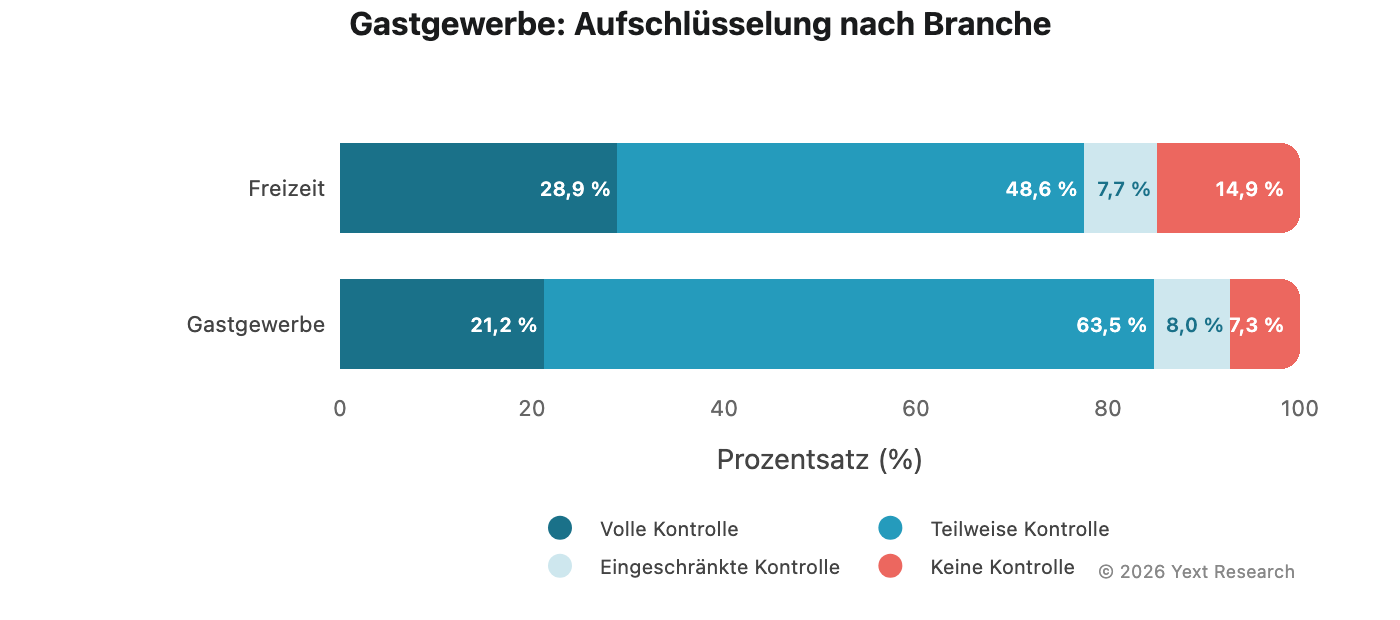
Der Bereich „Freizeit“ zeigt eine höhere Präferenz für „Volle Kontrolle“ (28,9 %) und eine erhöhte Präferenz für „Keine Kontrolle“ (14,9 %), was darauf hindeutet, dass Attraktionen und Aktivitäten stärker auf unabhängige Bewertungen und Reisepublikationen angewiesen sind.
Warum bevorzugt SearchGPT Hotel-Websites so stark? Das sagen uns die Daten nicht. Mögliche Erklärungen sind Unterschiede in der Zusammensetzung der Trainingsdaten, der Konfiguration des Abrufsystems oder der expliziten Gewichtung gegenüber markenspezifischen Quellen bei Reiseanfragen. Das ist eine offene Frage.
Abbildung 3: Unternehmensnahe Dienstleistungen
„Unternehmensnahe Dienstleistungen“ bzw. „Business Services“ weist eine klare Modelldifferenzierung auf, wobei Gemini bei „Volle Kontrolle“ an der Spitze steht:
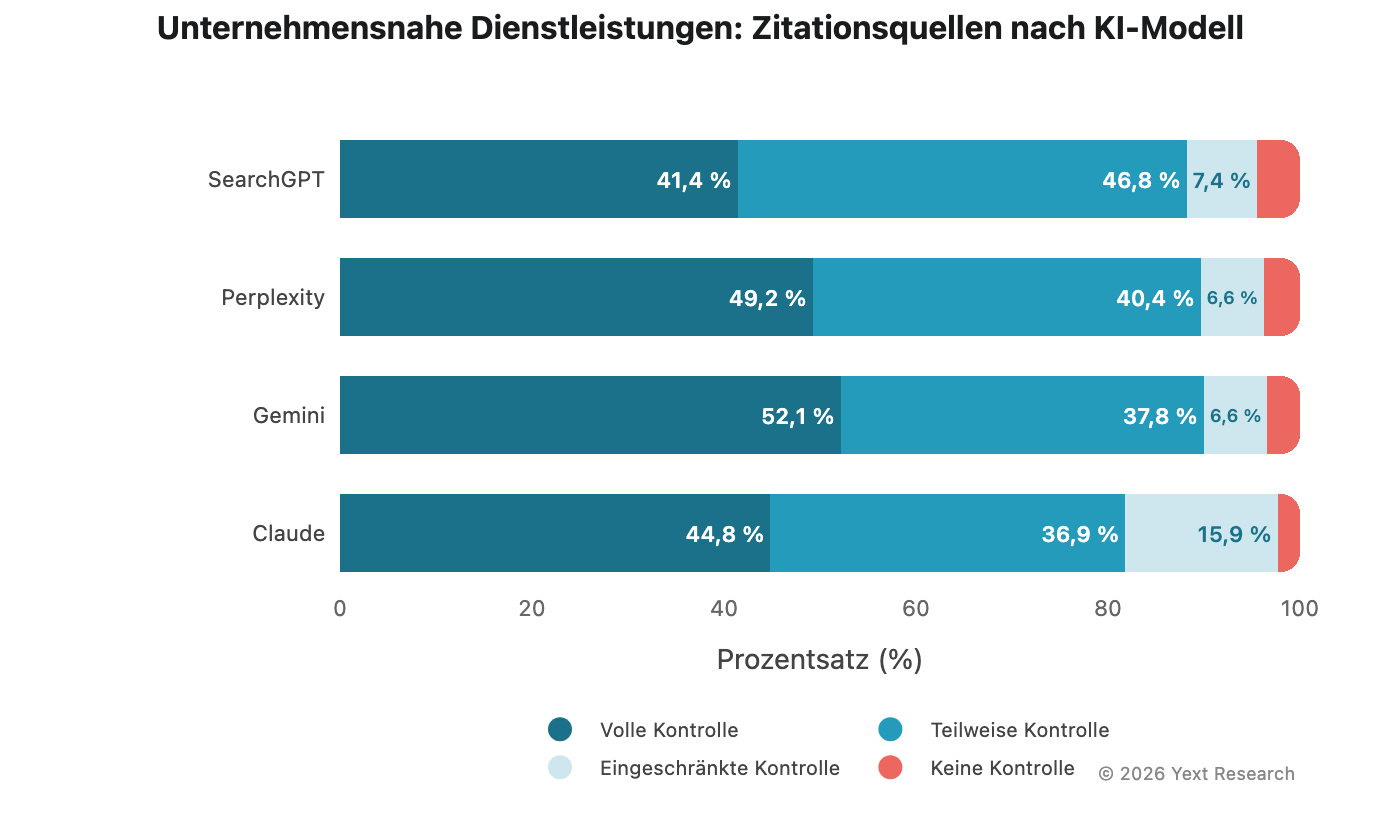
Claudes Abhängigkeit von „Eingeschränkte Kontrolle“ (15,89 %) ist mehr als doppelt so hoch wie bei jedem anderen Modell hier.
Aufschlüsselung der Branche:
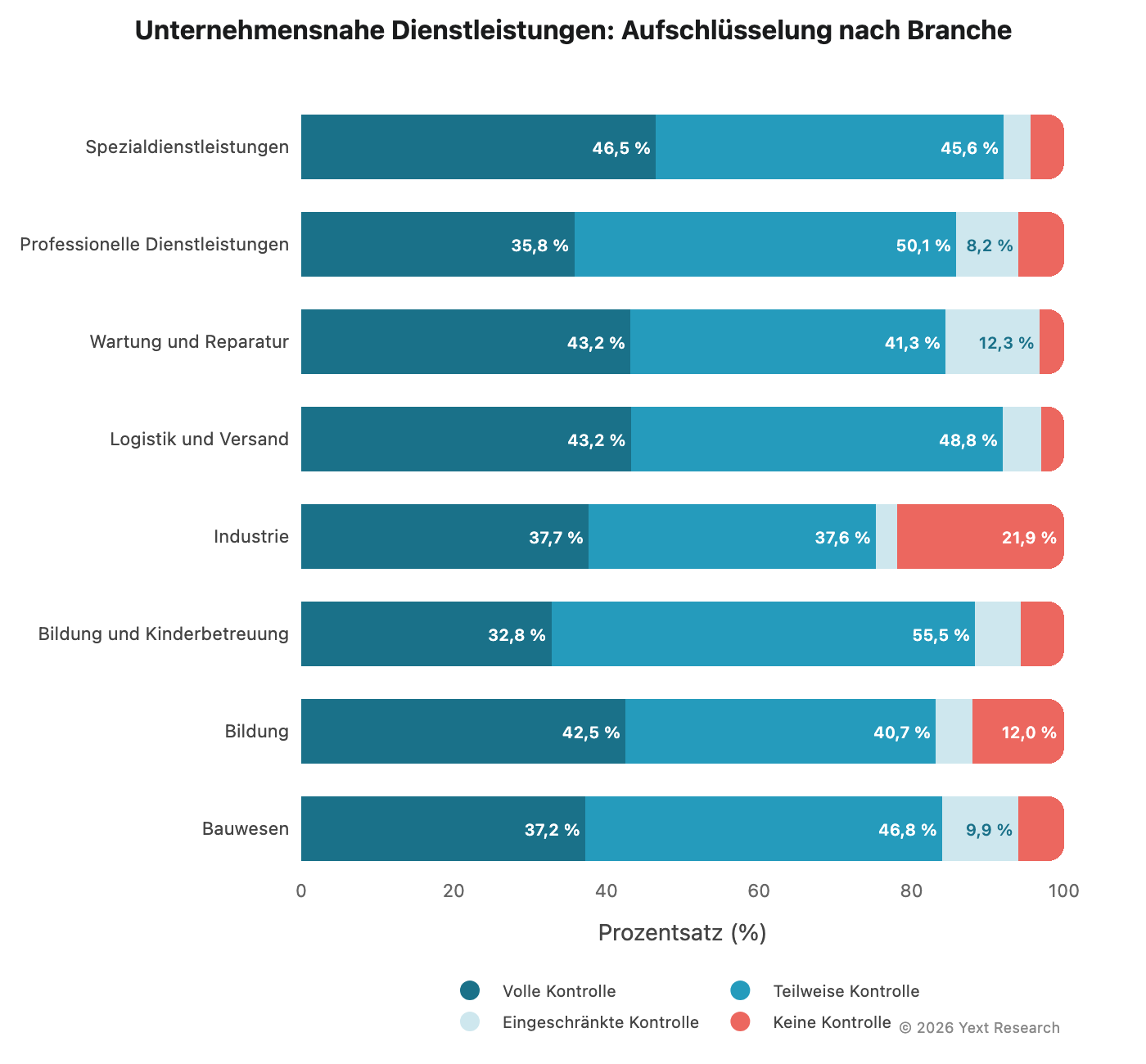
Bei Wartung und Reparatur sticht die Kategorie „Eingeschränkte Kontrolle“ (12,31 %) besonders hervor, was Sinn ergibt: Bewertungsplattformen wie Yelp, Angi und HomeAdvisor spielen eine zentrale Rolle dabei, wie Kund*innen Klempner- und Elektriker-Dienstleistungen finden.
Abbildung 4: Finanzsektor
Der Finanzsektor zeigt eine starke Präferenz für „Teilweise Kontrolle“ über Modelle hinweg, angetrieben durch Finanzverzeichnisse und Vergleichsplattformen:
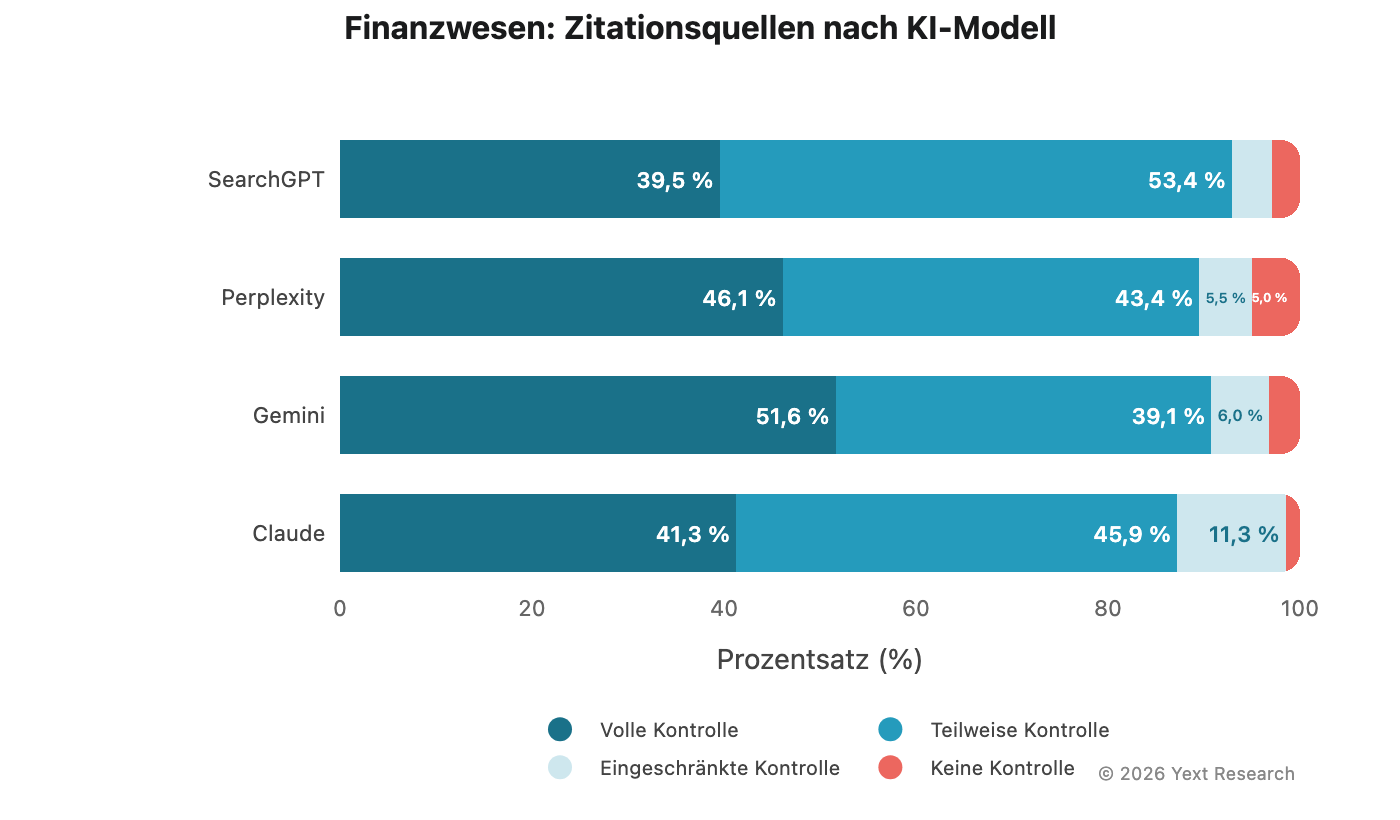
Der Anteil an „Volle Kontrolle“ von Gemini liegt bei 51,62 % und ist damit der höchste in diesem Sektor, was der allgemeinen Vorliebe des Unternehmens für autoritative Quellen aus erster Hand entspricht.
Aufschlüsselung der Branche:
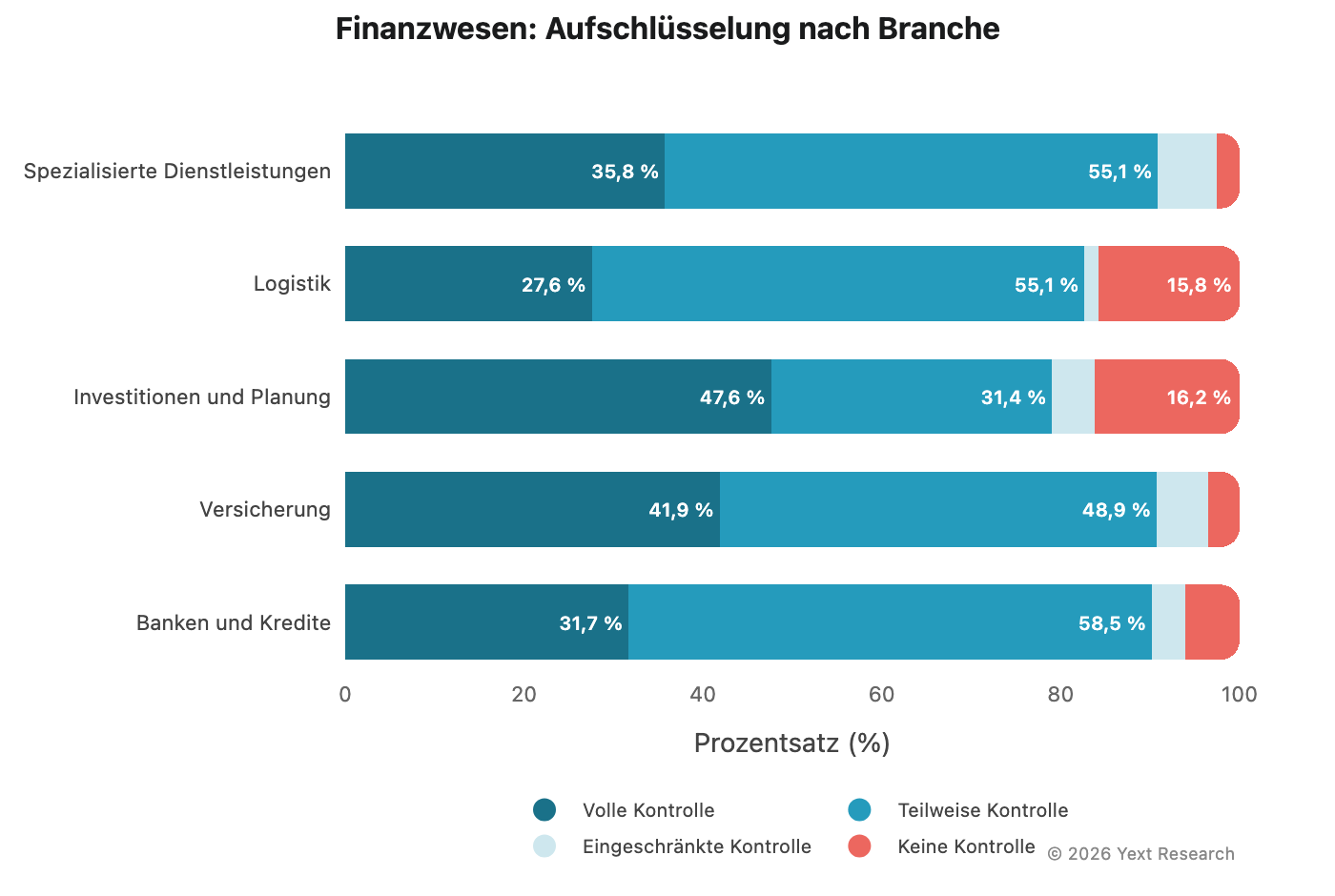
Der Bereich „Bankwesen und Kreditvergabe“ weist die stärkste Präferenz für „Teilweise Kontrolle“ auf (58,52 %), was auf eine starke Abhängigkeit von Finanzverzeichnissen und Vergleichs-Websites hindeutet. „Investition und Planung“ sowie „Logistik“ weisen einen erhöhten Wert von „Keine Kontrolle“ auf (16,19 % und 15,78 %), was auf eine stärkere Abhängigkeit von Nachrichten und unabhängigen Finanzpublikationen hindeutet. (Hinweis: „Investment und Planung“ hat nur 315 URLs, daher ist Vorsicht geboten.)
Abbildung 5: Gesundheitswesen
Das Gesundheitswesen weist die geringste Modelldivergenz aller Sektoren auf:
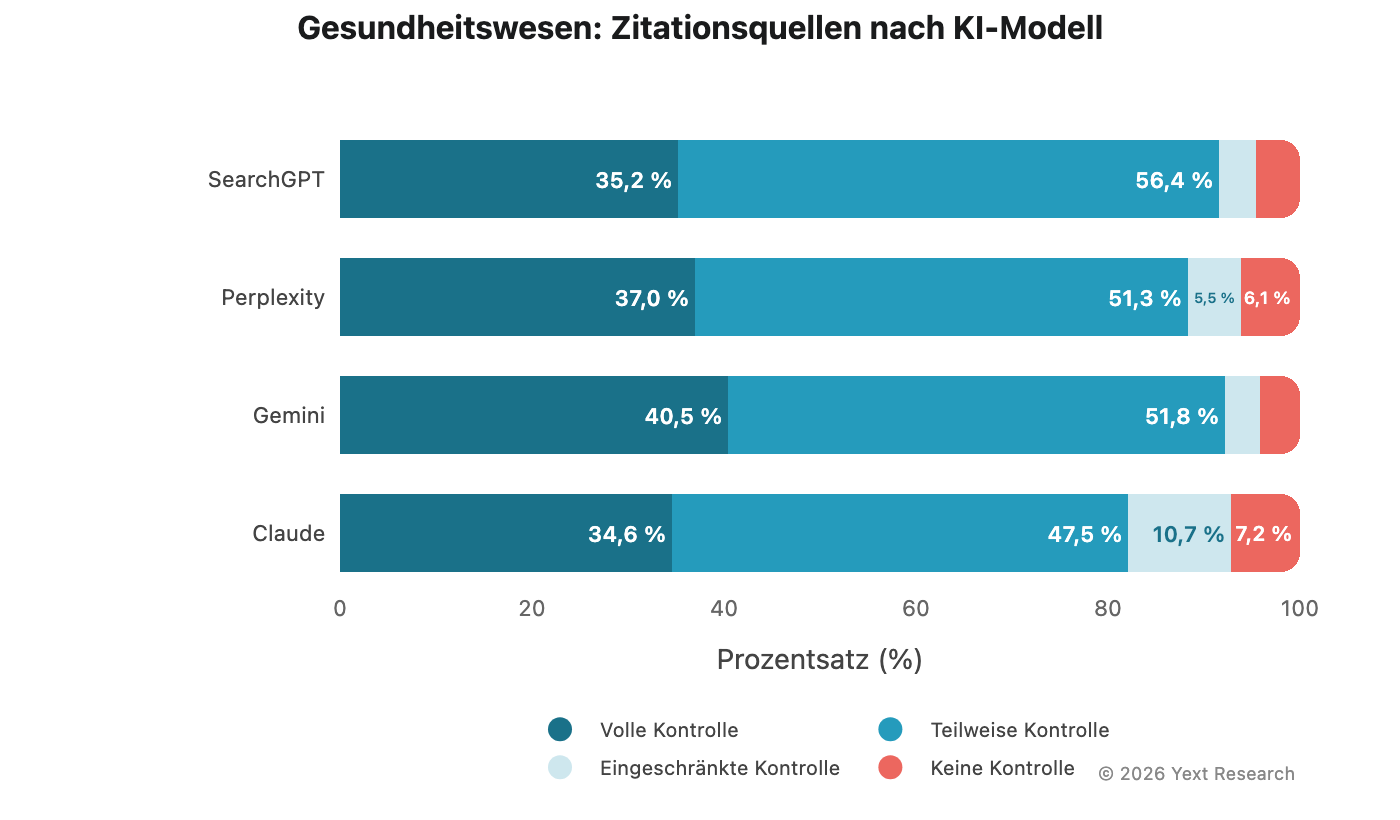
Die Werte für „Volle Kontrolle“ reichen von 34,60 % (Claude) bis 40,45 % (Gemini), eine Spanne von weniger als 6 Prozentpunkten. Das ist knapp. In den meisten anderen Sektoren beträgt die Spanne 10–15+ Punkte. Alle vier Modelle scheinen zu einem autoritativen und verzeichnislastigen Zitierungsverhalten zu tendieren, wenn das Thema medizinisch ist.
Diese Konvergenz ist gerade deshalb bemerkenswert, weil sie ungewöhnlich ist. Dies kann entweder auf eine gemeinsame Sensibilität für die Genauigkeit medizinischer Informationen über verschiedene Modellarchitekturen hinweg zurückzuführen sein oder aber die Struktur der verfügbaren medizinischen Quellen widerspiegeln (die von großen Verzeichnisplattformen wie Zocdoc und Healthgrades dominiert wird). Wahrscheinlich trifft beides zu.
Aufschlüsselung der Branche:
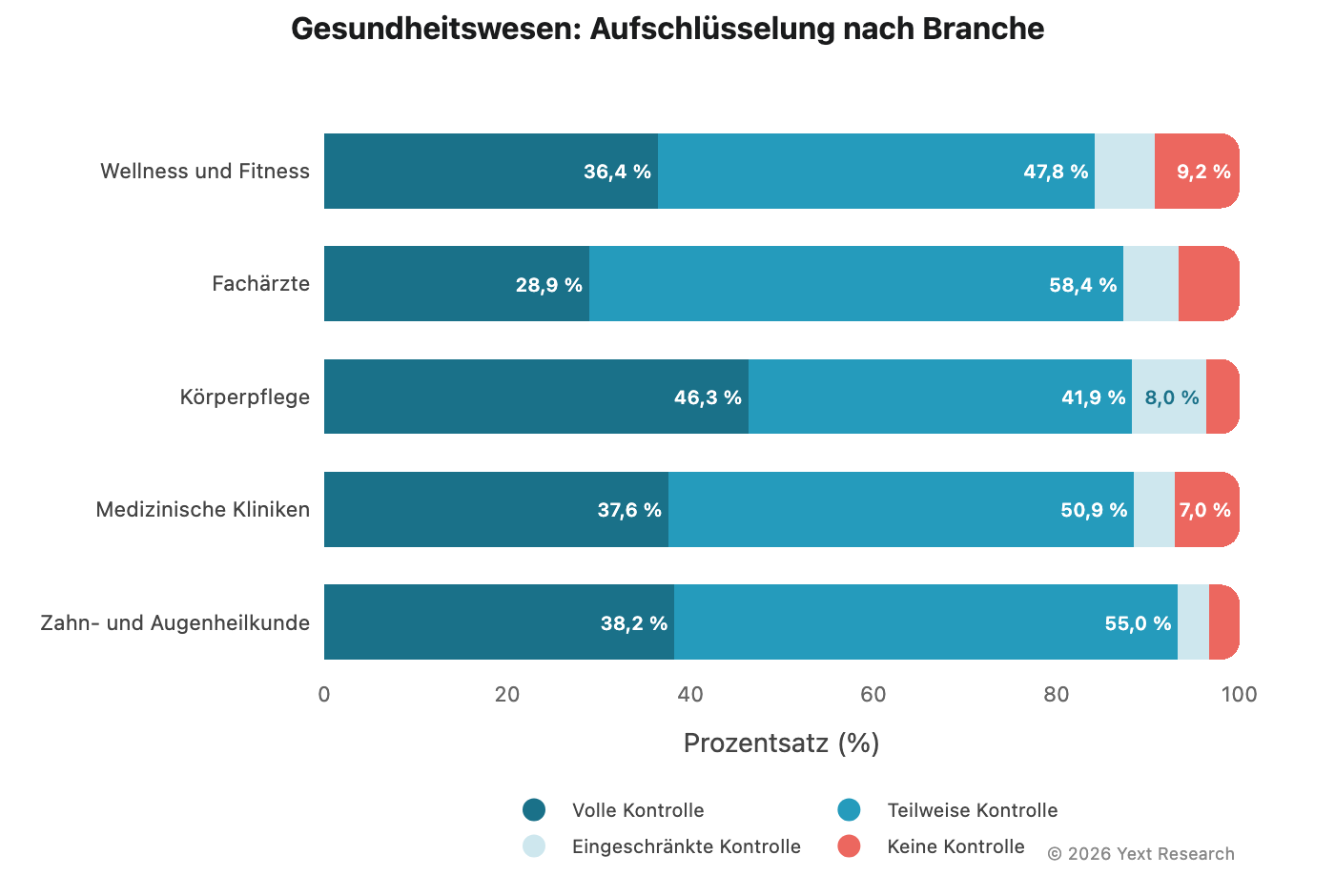
„Fachärzt*innen“ weisen den höchsten Wert bei „Teilweise Kontrolle“ (58,39 %) auf, was die zentrale Bedeutung von Gesundheitsverzeichnissen für die Entdeckung von Fachärzt*innen unterstreicht.
Abbildung 6: Lebensmittel und Getränke
„Lebensmittel und Getränke“ ist der Bereich, in dem die Abhängigkeit von Claudes „Eingeschränkte Kontrolle“ am stärksten ausgeprägt ist:
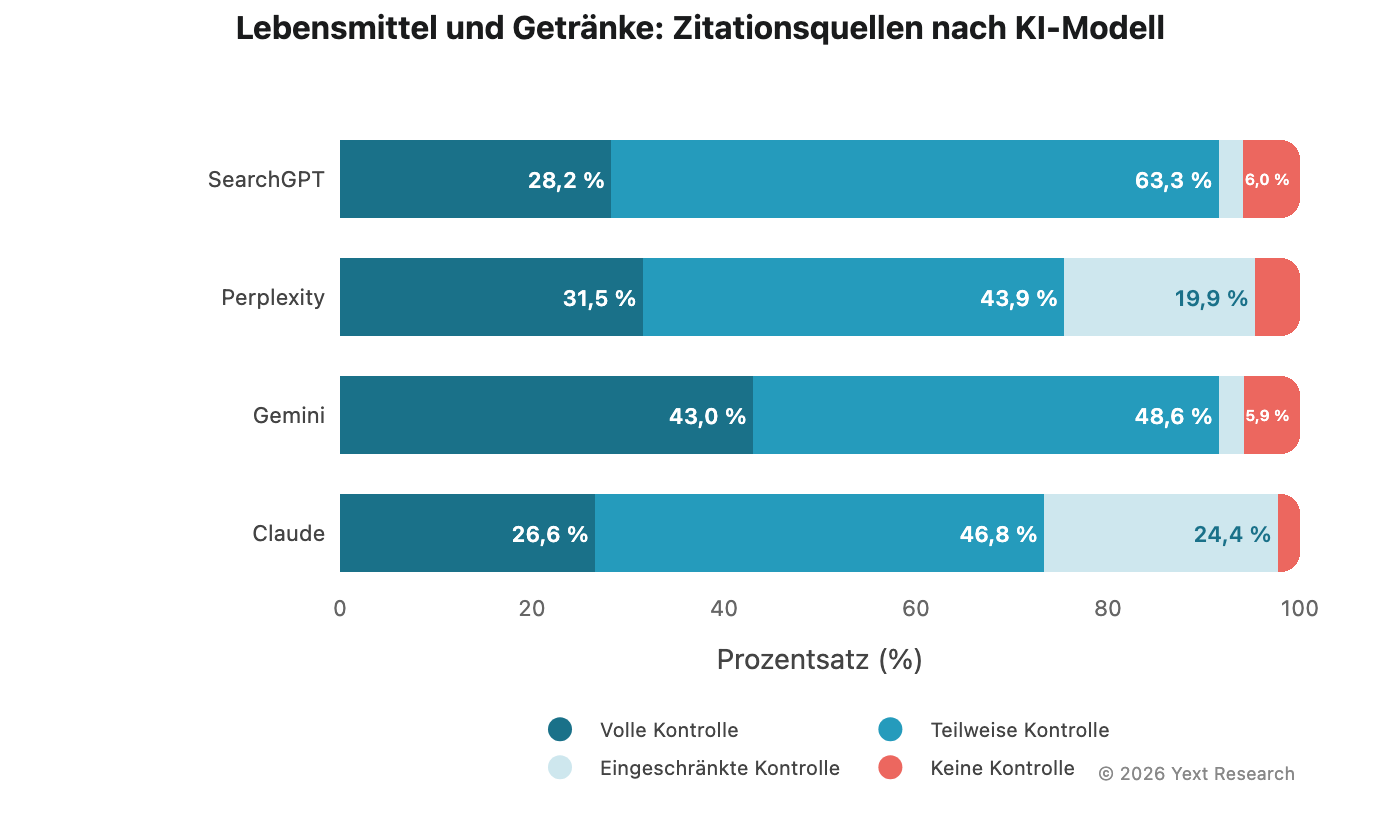
Claudes Anteil an „Eingeschränkte Kontrolle“ von 24,35 % ist fast zehnmal höher als die von Gemini mit 2,57 %. Fragen Sie Claude nach einem Restaurant und etwa jede vierte der genannten Quellen ist eine Bewertung oder ein Beitrag in den sozialen Medien. Wenn Sie Gemini die gleiche Frage stellen, sinkt das Verhältnis auf eins zu vierzig.
Aufschlüsselung der Branche:
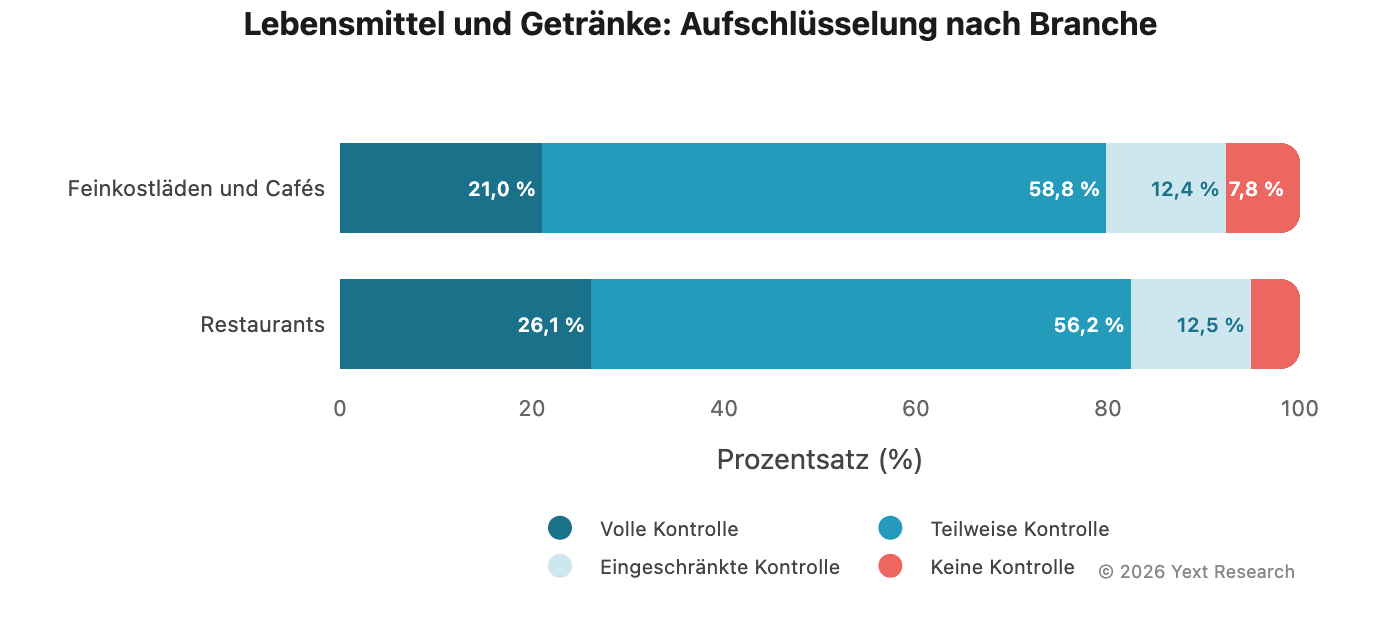
Beide Branchen weisen ein ähnliches Maß an eingeschränkter Kontrolle auf (~12,5 %), aber „Feinkostläden und Cafés“ hat eine niedrigere „Volle Kontrolle“ (21,03 % vs 26,15 %) und eine höhere „Keine Kontrolle“ (7,75 % vs 5,12 %), was auf ein größeres Vertrauen in Food-Blogs und unabhängige Bewertungen hinweist.
Abbildung 7: Einzelhandel
Der Einzelhandel zeigt moderate Variationen zwischen den Modellen mit einer relativ ausgewogenen Verteilung der Zitierungen:
Aufschlüsselung der Branche:
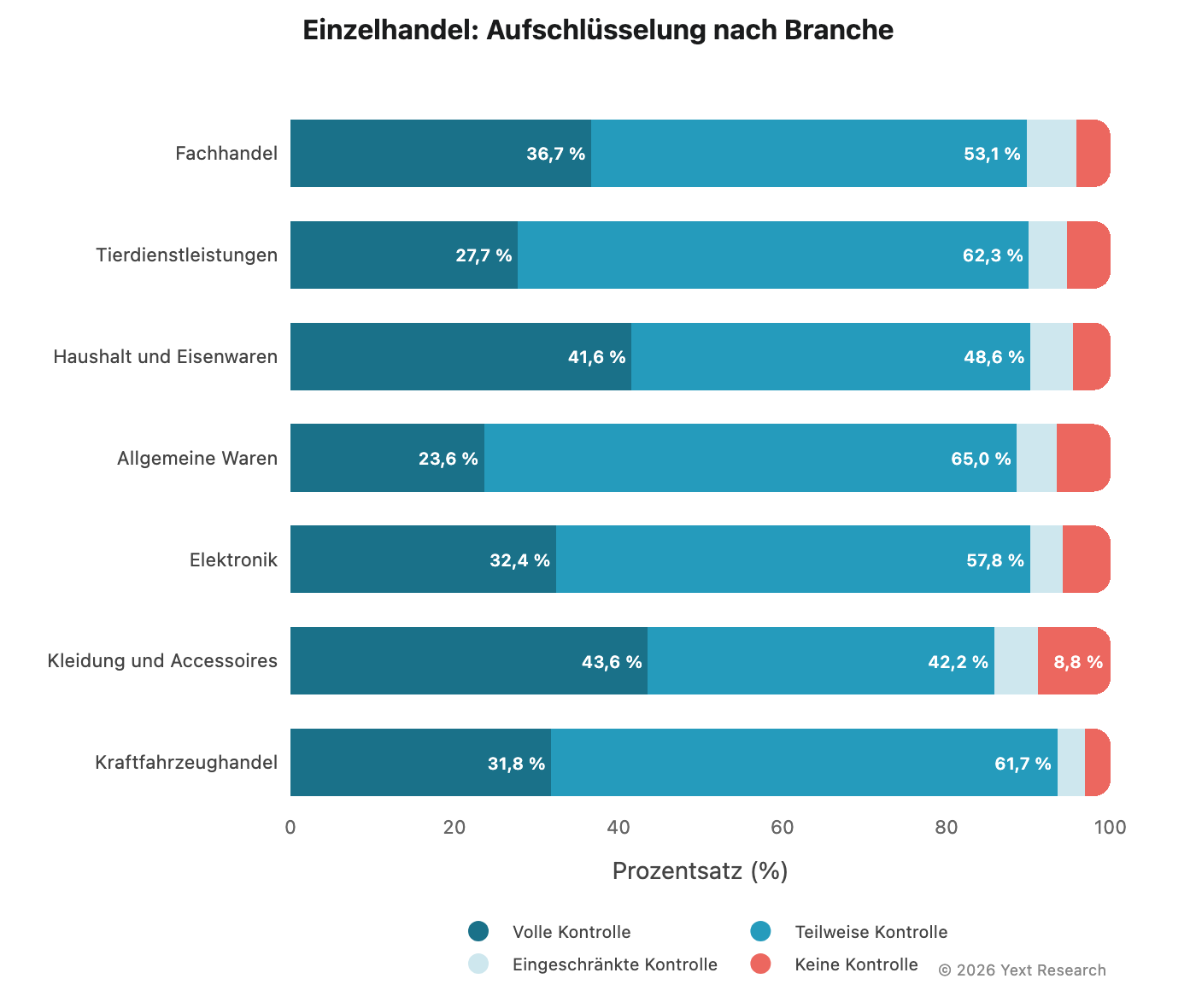
„Allgemeine Waren“ zeigt den höchsten Grad an „Begrenzter Kontrolle“ (64,99 %) und den niedrigsten Wert an „Volle Kontrolle“ (23,60 %), was auf eine starke Abhängigkeit von Aggregatoren und Vergleichs-Websites hindeutet. „Kleidung und Accessories“ hat den höchsten Wert an „Keine Kontrolle“ (8,82 %), was wahrscheinlich den Einfluss von Modepublikationen und Style-Blogs widerspiegelt.
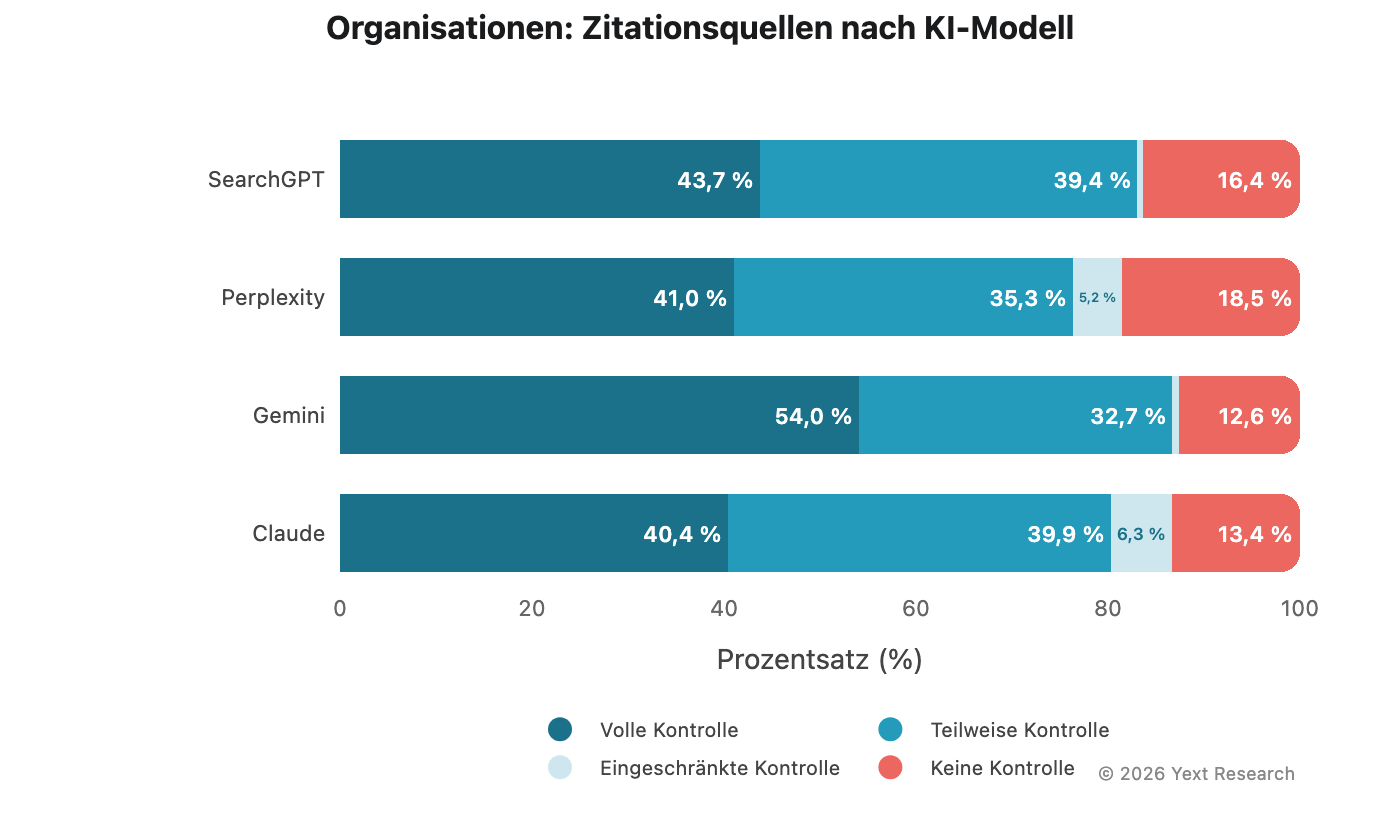
Abbildung 8: Organisationen
Organisationen (Non-Profit-Organisationen und religiöse Einrichtungen) weisen besonders hohe „Keine Kontrolle“-Raten auf:
„Keine Kontrolle“ reicht von 12,58 % (Gemini) bis 18,53 % (Perplexity), deutlich höher als in anderen Sektoren. Das macht intuitiv Sinn: Über gemeinnützige und religiöse Organisationen wird in der Berichterstattung und in Gemeinschaftsveröffentlichungen mehr geschrieben, als dass sie ihre eigenen auffindbaren Inhalte produzieren.
Aufschlüsselung der Branche:
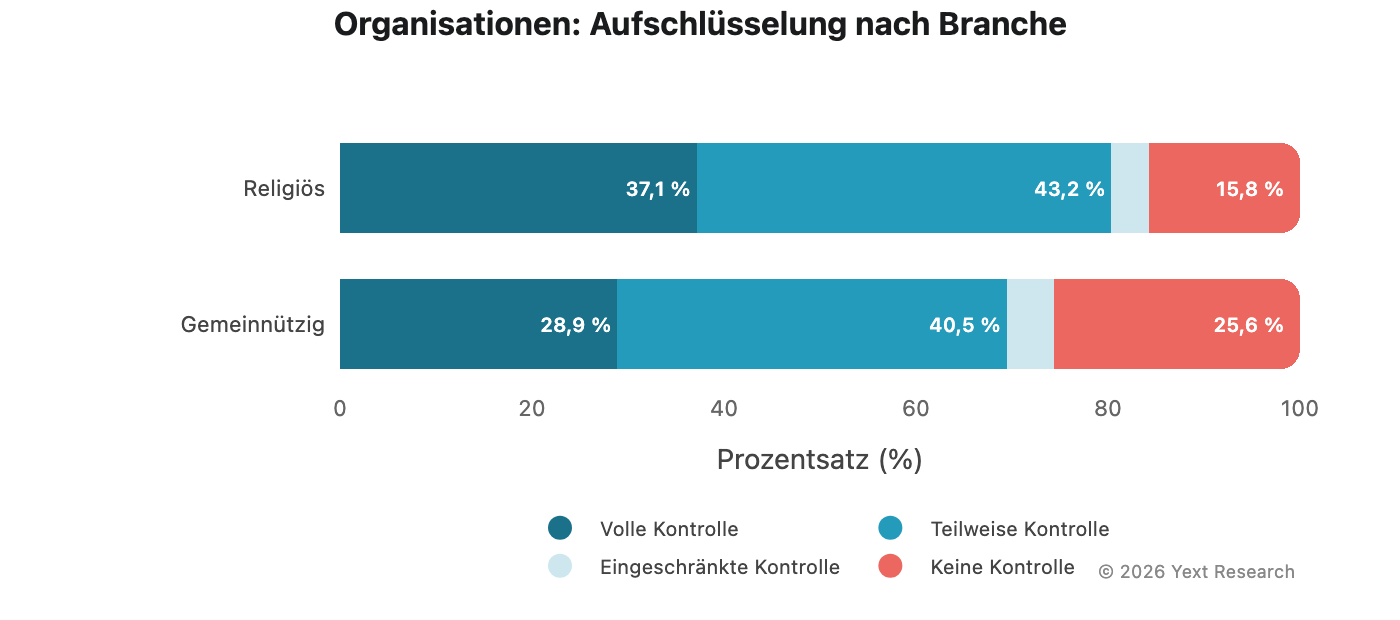
Bei gemeinnützigen Organisationen liegt der Wert für „Keine Kontrolle“ bei bemerkenswerten 25,62 %. Für diese Organisationen wird die Sichtbarkeit in der KI-Suche maßgeblich dadurch bestimmt, was andere über sie schreiben.
Abbildung 9: Claudes Abhängigkeit von „Eingeschränkte Kontrolle“
Claudes erhöhte Abhängigkeit von „Eingeschränkte Kontrolle“ ist das konsistenteste sektorübergreifende Muster in den Daten:
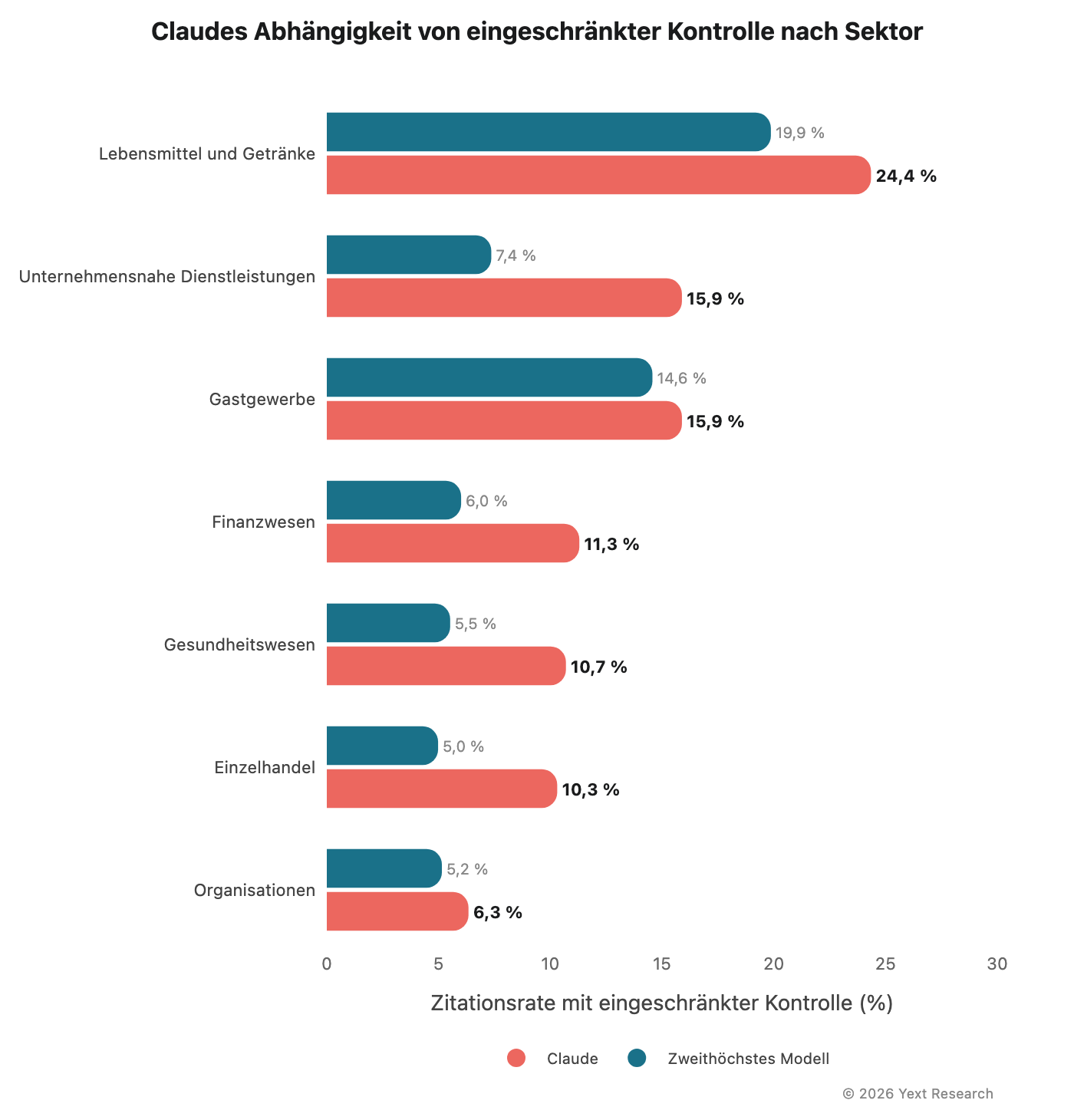
In allen sieben Sektoren führt Claude bei der Zitierungsanzahl für „Eingeschränkte Kontrolle“. Kein anderes Modell zeigt diese Art von richtungsweisender Konsistenz bei einer einzelnen Metrik.
Abbildung 10: Zusammenfassung auf Sektorebene
Diskussion
Modellarchitektur und Zitierungsverhalten
Die Zitierungsmuster in dieser Studie sind nicht zufällig und keine rein redaktionellen Entscheidungen der Modelle. Sie spiegeln wider, wie die Architektur jedes Modells Quellen abruft und bewertet. Das Verständnis dieser Unterschiede hilft zu erklären, was wir beobachten.
Perplexity (Search-First-RAG): Perplexity fungiert als Suchmaschine, die für jede Anfrage eine Websuche anhand eines eigenen Index auslöst. Die meisten Antworten stützen sich stark auf „antwortwürdige Passagen“, die direkt zitiert werden können. Diese Architektur erklärt die branchenübergreifende Konsistenz von Perplexity. Das Abrufsystem ist auf Stabilität optimiert, anstatt auf kontextabhängige Anpassung.
SearchGPT (RAG mit externer Abrufebene): Das Basismodell von SearchGPT kann nicht auf das Web zugreifen, daher verlässt es sich auf eine Abrufebene, um Ergebnisse abzurufen, und synthetisiert dann die Antworten. Es gibt keine veröffentlichten Belege dafür, dass ChatGPT Domains intern nach Vertrauen, Autorität oder E-E-A-T bewertet. Ein solches Verhalten spiegelt das vorgelagerte Abfragesystem wider und nicht das Modell selbst. Dies könnte die hohe branchenweite Varianz erklären, die wir beobachten. Die Zitierungsmuster hängen stark davon ab, wie die Abrufebene für verschiedene Abfragetypen konfiguriert ist.
Gemini (suchbasiert): Gemini ist suchbasiert, wobei die Zitierung aus der anfänglichen Fundierung und nicht aus den Basis-Parametern des Modells stammen. Die Quelle der Information ist Google Suche. Daraus folgt natürlich, dass Zitierungen das Google-Ranking-System übernehmen würden. Gemini ist eine LLM-Synthese von Google Suche, was bedeutet, dass der Wettbewerb um Sichtbarkeit in Gemini immer noch eine hervorragende traditionelle Suchoptimierung erfordert.
Claude (konstitutionelle KI): Claude verwendet RAG wie andere Modelle, unterscheidet sich jedoch darin, wie es die Zitierungsqualität bewertet. Was Claude auszeichnet, ist die konstitutionelle KI, eine Methode, bei der eine Reihe schriftlich festgelegter Grundsätze als Leitfaden für das Training und die Bewertung dienen. Das Modell kritisiert und überarbeitet seine eigenen Ergebnisse anhand einer Verfassung, anstatt sich ausschließlich auf Ranglisten menschlicher Präferenzen zu orientieren. Dies beeinflusst, wie Claude die Qualität, Sicherheit und Vollständigkeit von Antworten bewertet, führt aber keinen eigenen Zitierungs-Ranking-Algorithmus ein. Claudes erhöhte Präferenz für „Eingeschränkte Kontrolle“ könnte auf verfassungsrechtliche Grundsätze zurückzuführen sein, die vielfältige, von Nutzer*innen geprüfte Quellen als Signale für die Relevanz in der realen Welt gewichten. Oder es kann einfach ein Artefakt der Zusammensetzung der Trainingsdaten sein. Die Daten können diese Erklärungen nicht unterscheiden.
Einschränkungen
Diese Analyse hat einige Einschränkungen, die man klar benennen sollte:
-
Korrelation, nicht Kausalität. Die Daten beschreiben das Zitierungsverhalten, erklären aber nicht, warum Modelle unterschiedlich zitieren. Die obige Architekturdiskussion bietet plausible, aber keine bestätigten Erklärungen.
-
Zeitliche Momentaufnahme. Diese Daten beziehen sich auf das vierte Quartal 2025. Modellaktualisierungen erfolgen häufig und können die Zitierungsmuster verändern. Wir wissen nicht, wie stabil diese Muster über die Zeit sind.
-
Geografische Verzerrung. Obwohl die Daten weltweit erhoben wurden, waren die meisten Anfragen US-basiert. Internationale Märkte können unterschiedliche Muster aufweisen.
-
Beurteilungsfragen im Zusammenhang mit der Klassifizierung. Die Kategorisierung der Quellen erfordert Urteilsvermögen. Randfälle (Franchise-Websites, Aggregator-Bewertungen) könnten von anderen Forschenden unterschiedlich klassifiziert werden.
-
In manchen Branchen sind die Stichproben klein. Investment und Planung (315 URLs), Fachdienstleistungen (114 URLs), und Industrie (2.677 URLs) sind zu klein, um daraus individuelle, verlässliche Schlussfolgerungen zu ziehen.
Bereiche für weitere Forschung
-
Zeitliche Stabilität. Bleiben diese Muster bei Modellaktualisierungen bestehen oder sind sie nur vorübergehend? Eine Längsschnittstudie würde diese Frage beantworten.
-
Verbraucherauswirkungen. Wie beeinflussen die Arten von Zitierungsquellen die tatsächlichen Kaufentscheidungen? Der Zusammenhang zwischen Zitierungssichtbarkeit und Verbraucherverhalten bleibt ungeklärt.
-
Internationale Variation. Gelten diese Muster auch außerhalb der USA? Regulatorische Umgebungen und die Verfügbarkeit von Quellen unterscheiden sich je nach Region.
-
Effekte der Modellauswahl. Bevorzugen Verbraucher*innen mit unterschiedlichen Informationssuchpräferenzen Modelle, deren Zitierverhalten ihren Bedürfnissen entspricht? Das ist eine testbare Hypothese, die wir noch nicht getestet haben.
Fazit
Die einfache Version der Geschichte: KI-Modelle zitieren nicht alle auf die gleiche Weise und die Unterschiede sind groß genug, um für die Sichtbarkeit der Marke von Bedeutung zu sein.
Gemini bevorzugt Websites von Erstanbietern, was im Einklang mit seiner Ausrichtung auf die Google-Suche steht. Claude schöpft aus nutzergeneriertem Inhalt mit Raten, die 2–4 mal höher sind als bei Wettbewerbern. SearchGPT variiert stark je nach Branche, mit einer überproportionalen Präferenz für offizielle Hotel-Websites. Perplexity ist in allen Sektoren am beständigsten.
Diese Muster variieren auch stärker innerhalb der Sektoren als zwischen ihnen. Eine Marke im Bank- und Kreditwesen steht vor einem anderen Zitierungsumfeld als eine im Versicherungswesen, obwohl beide im Finanzsektor angesiedelt sind.
Was wir noch nicht sagen können, ist, wie langlebig diese Muster sind oder wie direkt sie sich in Verbraucherentscheidungen übersetzen. Modellarchitekturen verändern sich. Abfragesysteme werden aktualisiert. Die Muster, die wir in Q4 2025 gemessen haben, könnten Mitte 2026 anders aussehen.
Was sich voraussichtlich weniger ändern wird, ist die zugrunde liegende Dynamik: unterschiedliche Modelle, unterschiedliche Quellenpräferenzen, unterschiedliche Sichtbarkeitsergebnisse. Unternehmen, die die KI-Suche als einen einzigen zu optimierenden Kanal betrachten, gehen von einer Annahme aus, die von den Daten nicht gestützt wird.
Anhang
Definitionen von Kontrollkategorien
| Kategorie | Vollständige Definition |
|---|---|
| Volle Kontrolle | Der Content wird vollständig vom Unternehmen erstellt und gehostet. Enthält offizielle Websites, eigene Blogs, Unternehmensredaktionen und First-Party-Landingpages. Marken haben die volle redaktionelle Kontrolle über Botschaft, Genauigkeit und Präsentation. |
| Teilweise Kontrolle | Verzeichnisse und Plattformen von Drittanbietern, auf denen eine Marke ihr Profil beanspruchen und verwalten kann. Obwohl die Marke nicht Eigentümer der Plattform ist, kann sie die Genauigkeit ihrer Informationen direkt kontrollieren. Dazu gehören Google Unternehmensprofil, MapQuest und branchenspezifische Verzeichnisse. |
| Eingeschränkte Kontrolle | Plattformen, auf denen Inhalte hauptsächlich nutzergeneriert sind, aber Marken aktiv durch Antworten, Engagement und Reputationsmanagement teilnehmen können. Dazu gehören Google Rezensionen, Yelp, Facebook und Social Media-Plattformen. |
| Keine Kontrolle | Quellen, bei denen eine Marke keine direkte Kontrolle über Inhalte hat. Dazu gehören Nachrichtenartikel, Reddit-Diskussionen, Forenbeiträge, nutzergenerierte Inhalte und unabhängige Publikationen. |
Frühere Arbeiten
Diese Analyse baut auf Forschungsergebnissen der Yext-Studien zu KI-Zitaten und KI-Sucharchetypen auf:
- KI-Zitierung, Benutzerstandorte und Abfragekontext
- Best Practices helfen nur bedingt weiter
- Der Aufstieg von KI-Sucharchetypen
Über Yext Research
Yext Research führt unabhängige Analysen des KI-Zitierungsverhaltens mithilfe der Yext Scout-Plattform durch. Daten zum Verbraucherverhalten werden durch eine Partnerschaft mit Researchscape International erhoben.