At the bottom of some of our search queries we have a thumbs up/thumbs down option. We collect all of the bad results and make sure we include those data points in our next retrain so the model doesn't make the same mistake again.
We also sample data from newer Answers experiences as well as existing experiences since queries change over seasons and years. For example, in the summer months people are less likely to search for Christmas trees than in the winter, so we want to make sure our training set captures seasonality as well as old and new!
2. Human annotators label entities in each query with the appropriate NER labels.
We have a team of dedicated human annotators that go through and label each query in our dataset. Our annotators label thousands of data points across all of our models every single week, and are a crucial part of our retraining process.
3. Clean & filter labeled data.
After our queries are labeled, we have to make sure we clean the data up. This involves 3 steps. First, we remove all queries where annotators have labeled anything as "unsure". We want only confidently labeled data in our training dataset. We then remove all queries that were labeled "corrupt". This includes queries with profanity and incomprehensible or irrelevant queries. Lastly, we assign each query to at least two annotators. If there are conflicting labels for a particular query, we make sure to remove it from the dataset.
4. Format data for BERT with Wordpiece Tokenization.
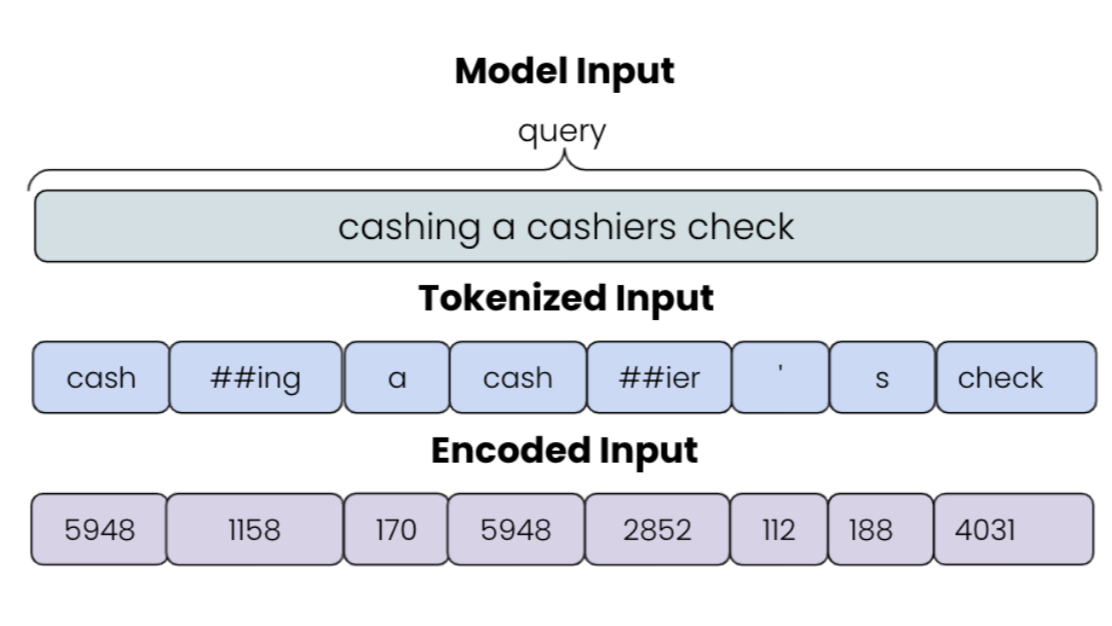
Now that we have our cleaned data, we need to format it in a way that our BERT model for NER understands it. BERT is a powerful neural network based model developed by Google used for a variety of natural language processing tasks. To use BERT for NER, we need to format our input using wordpiece tokenization. Wordpiece tokenization helps the model process unknown words by breaking them down into subword units.
In this example you can see how tokenization splits aparts words like cashing and cashier into the subword "cash" and then -ing and -ier. This is efficient because it allows us to keep the model inputs smaller but still allow the model to learn new content. After a query goes through tokenization, we also have to make sure it is encoded, since ML models only understand numbers not text. These numbers come from an extensive vocabulary file that maps each token to an id. A similar mapping process occurs for all the corresponding entity labels for each query and that serves as our encoded output, which is also passed into the model.