Comportement de citation des modèles d'IA : analyse de 17,2 millions de citations
Chaque modèle d'IA cite différemment : un enjeu stratégique sous-estimé.
Résumé
Lorsqu'un consommateur interroge un modèle d'IA à propos d'une entreprise, la réponse qu'il obtient dépend fortement du modèle utilisé. Non pas parce qu'ils disposent de connaissances distinctes, mais parce qu'ils mobilisent des types de sources variés, à des fréquences différentes, selon des schémas propres à chaque secteur.
Notre analyse de 17,2 millions de citations générées par l'IA au quatrième trimestre 2025 montre que le comportement de citation suit des schémas prévisibles et propres à chaque modèle. Cette recherche s'appuie sur des travaux précédents menés en 2025, au cours desquels nous avons évalué 6,9 millions de citations et développé notre cadre localisation-contexte.
Trois constats majeurs ressortent :
-
Les schémas de citation varient davantage au sein des secteurs qu'entre ces derniers. Les restaurants, cafés et commerces alimentaires spécialisés relèvent du même secteur (l'alimentation et les boissons) mais présentent des profils de citation significativement différents. Une analyse strictement sectorielle ne permet pas de rendre compte de ces écarts.
-
Claude s'appuie nettement plus que les autres modèles sur le contenu généré par les utilisateurs. Les citations relevant de la catégorie Contrôle limité (avis, réseaux sociaux) sont présentes à des niveaux deux à quatre fois supérieurs à ceux observés pour les autres modèles, dans l'ensemble des sept secteurs étudiés. Il ne s'agit pas d'une anomalie isolée dans une catégorie spécifique, mais d'un schéma récurrent.
-
SearchGPT traite les sites web d'hôtels très différemment. SearchGPT cite les sites officiels d'hôtels dans 38,1 % des cas, contre une fourchette comprise entre 16,7 % et 22,4 % pour les autres modèles. Il s'agit de la divergence la plus marquée observée pour un modèle donné au sein d'un secteur.
En pratique, il n'existe pas de stratégie unique d'« optimisation pour l'IA ». La combinaison de sources qui favorise la visibilité d'une marque dans Gemini diffère de celle qui prévaut dans Claude. Les entreprises qui traitent la recherche par IA comme un bloc homogène optimisent leur contenu pour une moyenne théorique qui n'existe pas.
Introduction
Notre récente étude « L'essor des archétypes de recherche IA », menée auprès de 2 237 consommateurs aux États-Unis, au Royaume-Uni, en France et en Allemagne, révèle que 75 % des consommateurs utilisent désormais les outils d'IA plus qu'il y a un an, et que près de la moitié utilisent la recherche par IA quotidiennement.
Ce changement est important, car la recherche par IA fonctionne différemment de la recherche traditionnelle. Dans la recherche traditionnelle, les marques sont en concurrence pour des positions de classement sur une page de résultats. Dans la recherche par IA, le modèle synthétise une réponse et en cite les sources. La visibilité dépend des citations, et non du classement. Comme le montre cette étude, différents modèles citent différentes sources.
Cette situation crée un enjeu stratégique que de nombreuses entreprises n'ont pas encore pleinement intégré. Une marque peut bénéficier d'une excellente visibilité dans Gemini (qui s'appuie fortement sur les sites officiels) et être presque invisible dans Claude (qui utilise davantage les avis et les contenus sociaux). La « stratégie de recherche IA » d'une marque peut fonctionner parfaitement pour un modèle et échouer pour un autre, sans que l'entreprise puisse le savoir à moins de disposer de données propres à chaque modèle.
Cette recherche examine comment les quatre principaux modèles d'IA sélectionnent leurs sources de citation, quels schémas émergent dans sept grands secteurs et de nombreux sous-secteurs, et où les écarts entre modèles sont suffisamment marqués pour entraîner des impacts mesurables.

Méthodologie
Collecte des données de citation
Cette analyse examine 17,2 millions de citations générées par l'IA collectées à l'échelle mondiale au quatrième trimestre 2025 sur quatre principaux modèles d'IA. Les données ont été recueillies à l'aide de la plateforme Yext Scout.
Les requêtes ont été structurées selon quatre types d'intention : objectif avec marque, subjectif avec marque, objectif sans marque, subjectif sans marque. Les données ont été collectées à l'échelle des établissements et non des marques, afin de capturer les variations géographiques et contextuelles que les études nationales à l'échelle des marques ne détectent pas.
Cadre des catégories de contrôle
Les sources citées ont été identifiées en soumettant à chaque modèle quatre types de questions, fondés sur notre cadre localisation-contexte.
| Niveau de contrôle | Définition | Exemples |
|---|---|---|
| Total | Contenu intégralement créé et hébergé par l'entreprise | Sites officiels, blogs de marque, espaces presse |
| Partiel | Plateformes tierces sur lesquelles la marque peut gérer son profil | Fiches d'établissement Google, MapQuest, TripAdvisor, Zocdoc |
| Contrôle limité | Plateformes de contenu généré par les utilisateurs, avec participation possible de la marque | Avis Google, Yelp, Facebook, réseaux sociaux |
| Aucun contrôle | Sources indépendantes sans intervention de l'entreprise | Articles de presse, Reddit, forums, publications indépendantes |
Répartition globale des citations :
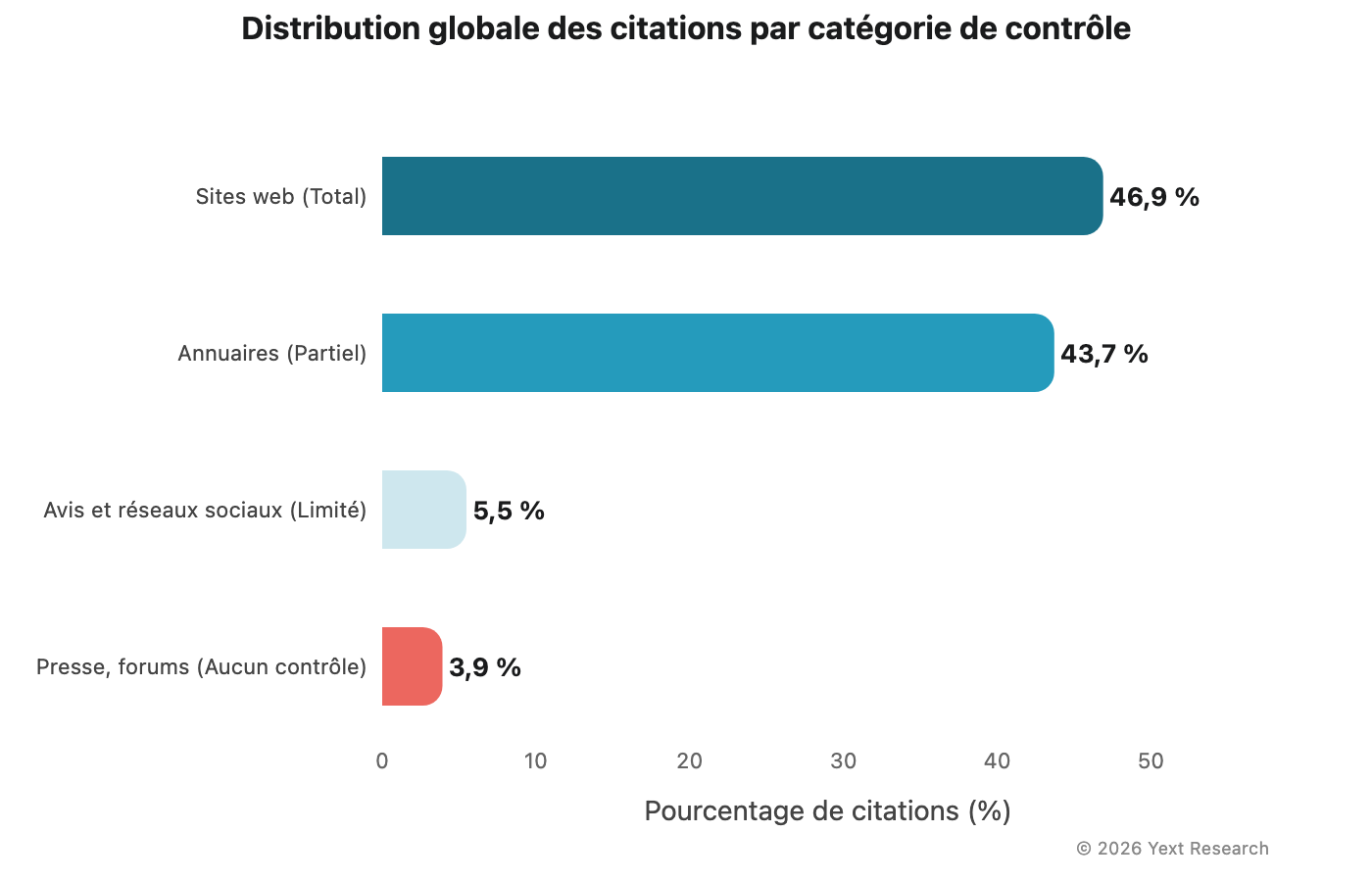
Un élément ressort clairement : les annuaires représentent la plus grande part des URL distinctes (54,53 %), mais les sites web génèrent nettement plus de citations par URL (4,31 fois contre 2,46 fois). Les modèles d'IA citent plus fréquemment les contenus propriétaires que les fiches individuelles.
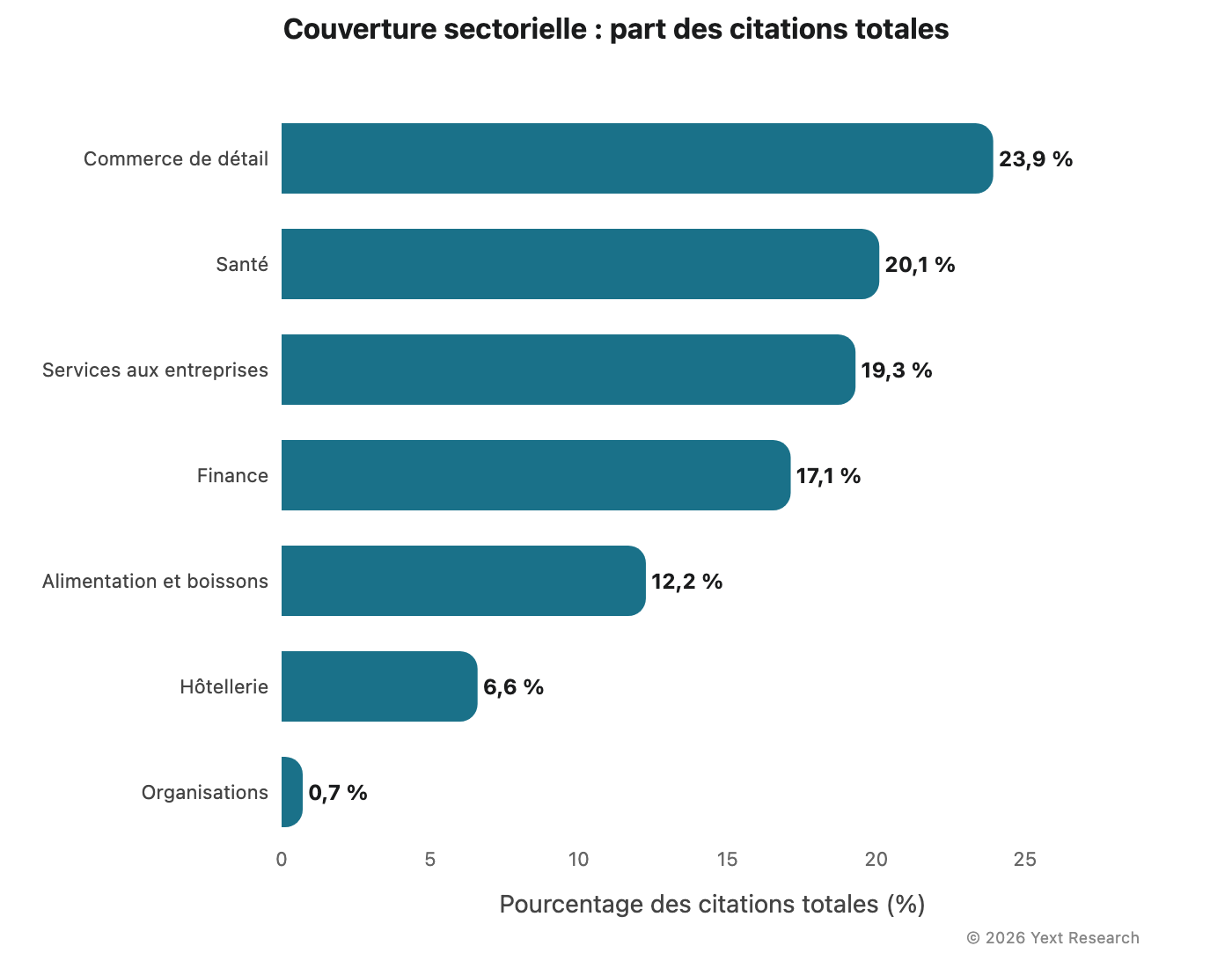
Couverture sectorielle
L'analyse porte sur sept secteurs :
Résultats
Figure 1 : Schémas de citation au niveau des modèles
Chaque modèle d'IA présente des schémas de citation cohérents qui persistent d'un secteur à l'autre, bien que leur ampleur varie.
Gemini affiche la plus forte proportion de citations relevant de la catégorie Total dans la plupart des secteurs, allant de 22,4 % (hôtellerie) à 54 % (organisations). Ce phénomène pourrait s'expliquer par l'intégration des signaux E-E-A-T dans la logique de citation de Gemini, analysée plus en détail dans la section consacrée à l'architecture.
Claude affiche systématiquement une part élevée de citations relevant de la catégorie Contrôle limité, allant de 6,3 % (organisations) à 24,4 % (alimentation et boissons). Ce taux est 2 à 4 fois supérieur à celui observé pour les autres modèles dans la plupart des secteurs.
Perplexity affiche le profil le plus stable d'un secteur à l'autre, avec une part élevée de la catégorie Total comprise entre 37 % et 50 % dans la plupart des cas. Cette stabilité semble cohérente avec son architecture centrée sur la recherche.
SearchGPT affiche la variabilité sectorielle la plus marquée, avec la catégorie Total allant de 28,2 % (alimentation et boissons) à 43,7 % (organisations), avec un pic notable dans l'hôtellerie (38,1 %).
Figure 2 : L'anomalie de SearchGPT dans l'hôtellerie
Le secteur de l'hôtellerie présente la divergence la plus marquée entre modèles dans l'ensemble des données :
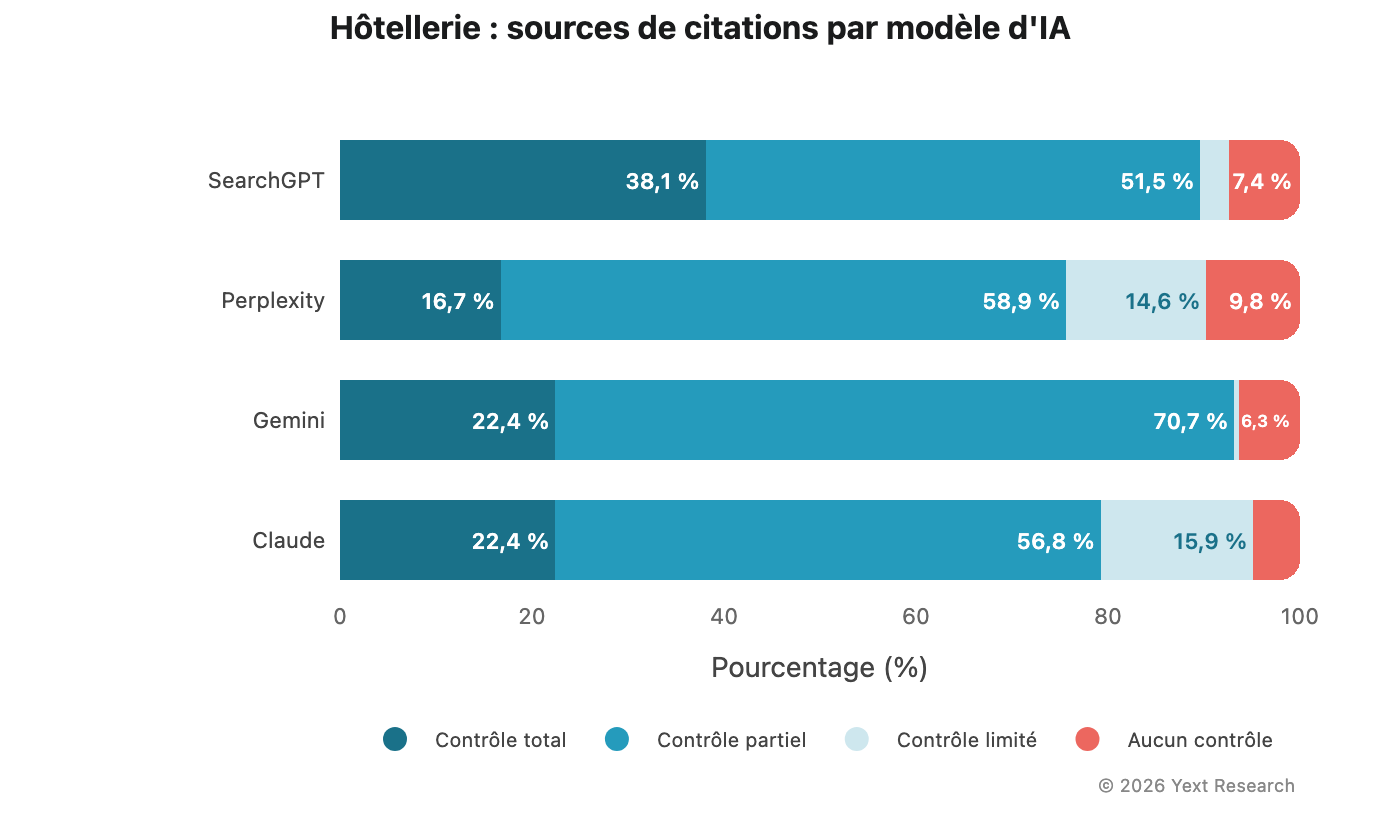
La part de la catégorie Total de SearchGPT (38,1 %) est près de deux fois supérieure à celle des autres modèles dans ce secteur. Ce schéma se retrouve également dans les sous-industries du secteur hôtelier.
Répartition par secteur :
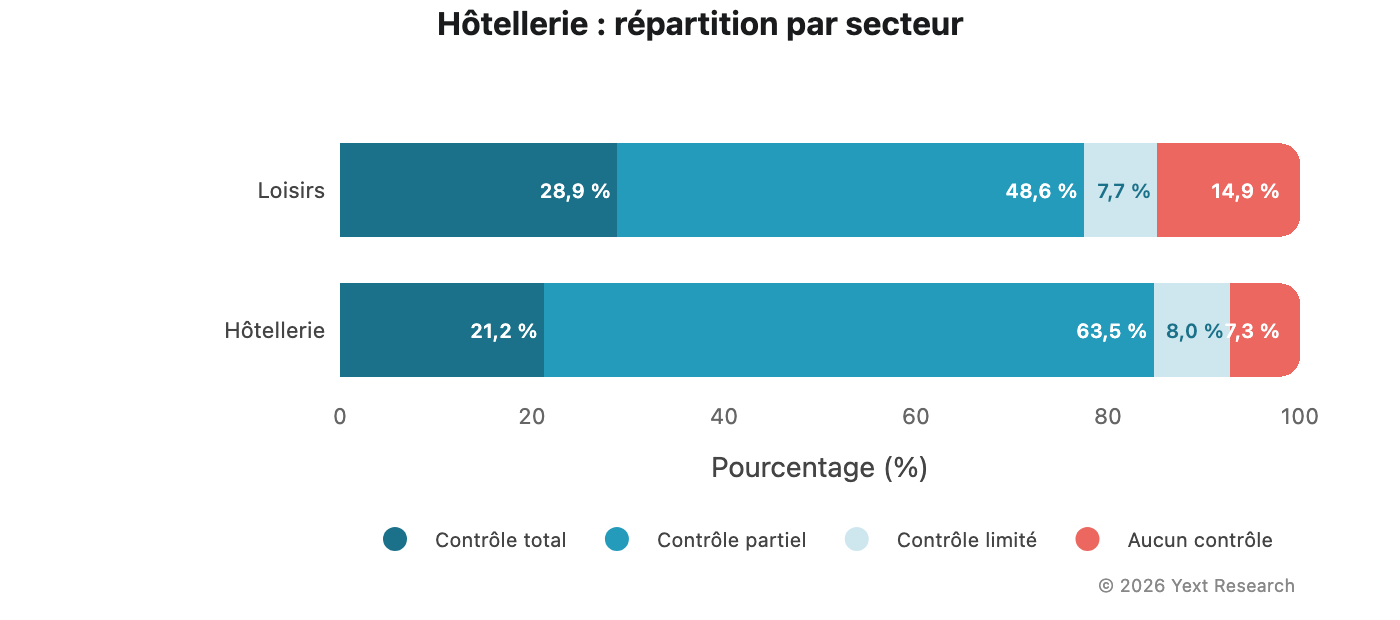
Le secteur des loisirs affiche une proportion plus élevée de Total (28,9 %) et un niveau important de Aucun contrôle (14,9 %), ce qui peut refléter une forte présence d'avis indépendants et de publications dans le voyage.
Pourquoi SearchGPT accorde-t-il une telle place aux sites officiels d'hôtels ? Les données disponibles ne permettent pas d'en identifier la cause. Plusieurs hypothèses peuvent être avancées, notamment des différences dans la composition des données d'entraînement, dans les mécanismes de récupération de l'information, ou un poids plus important accordé aux sources officielles pour les requêtes liées au voyage. Cette question demeure ouverte.
Figure 3 : Services aux entreprises
Le secteur des services aux entreprises présente une différenciation nette entre modèles, avec une prédominance de la catégorie Total pour Gemini :
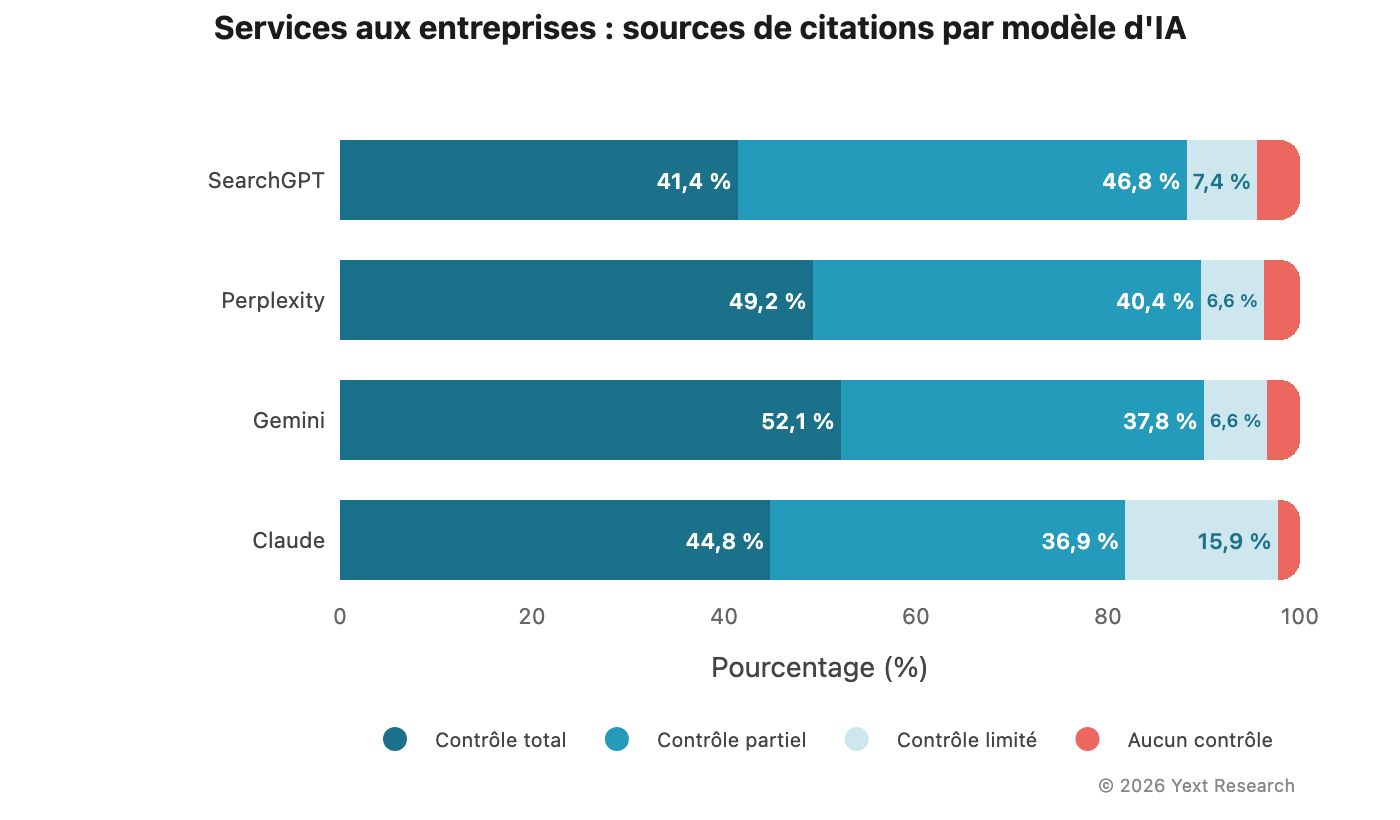
La part de Contrôle limité pour Claude (15,89 %) est plus de deux fois supérieure à celle observée pour tout autre modèle dans ce secteur.
Analyse par secteur :
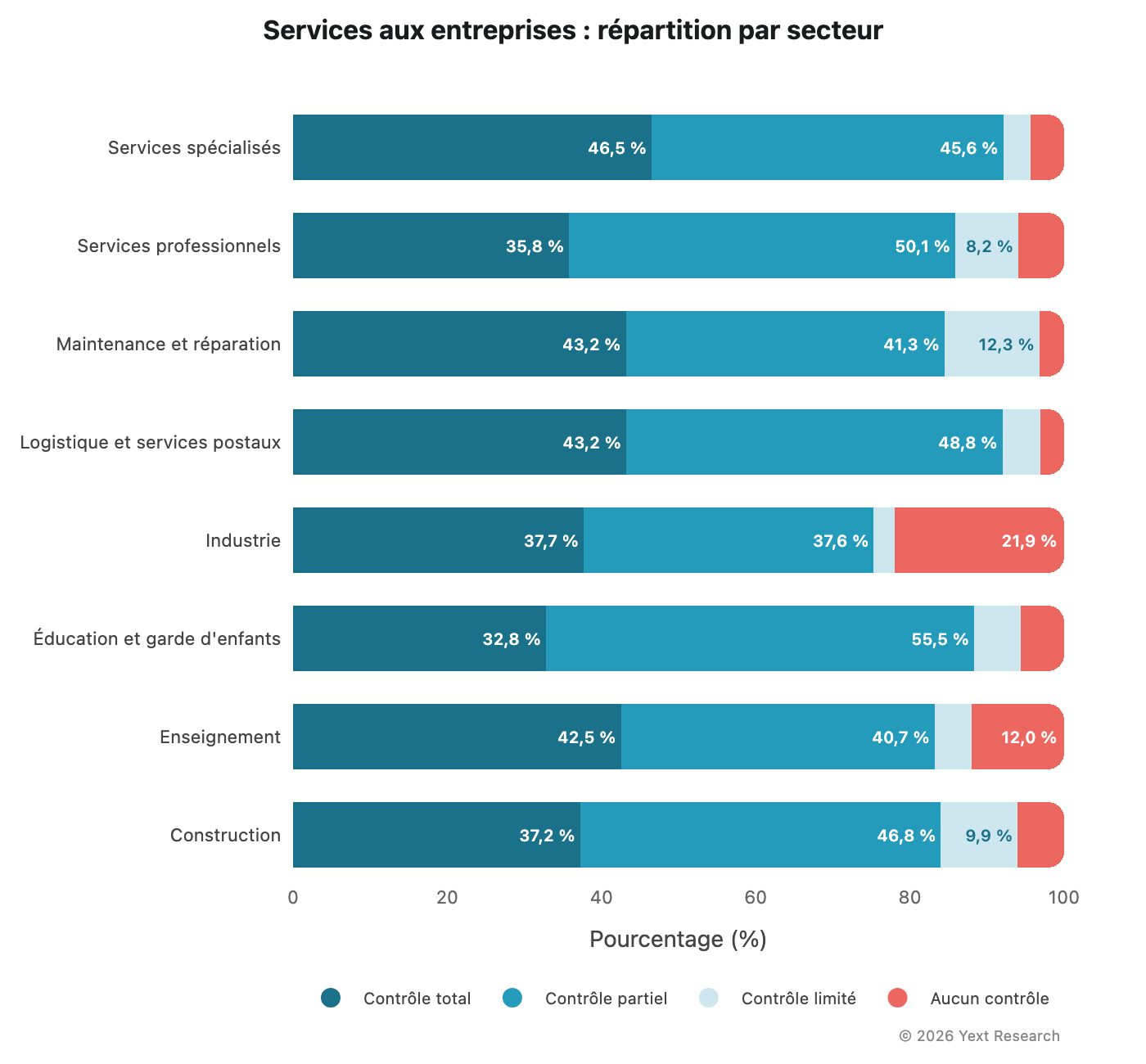
Le segment maintenance et réparation affiche un niveau élevé de Contrôle limité (12,31 %), car les plateformes d'avis et de mise en relation pour les services à domicile jouent un rôle clé pour trouver un plombier ou un électricien.
Figure 4 : Finance
Dans le secteur financier, la catégorie Partiel domine dans l'ensemble des modèles, principalement en raison du poids des annuaires financiers et des plateformes de comparaison :
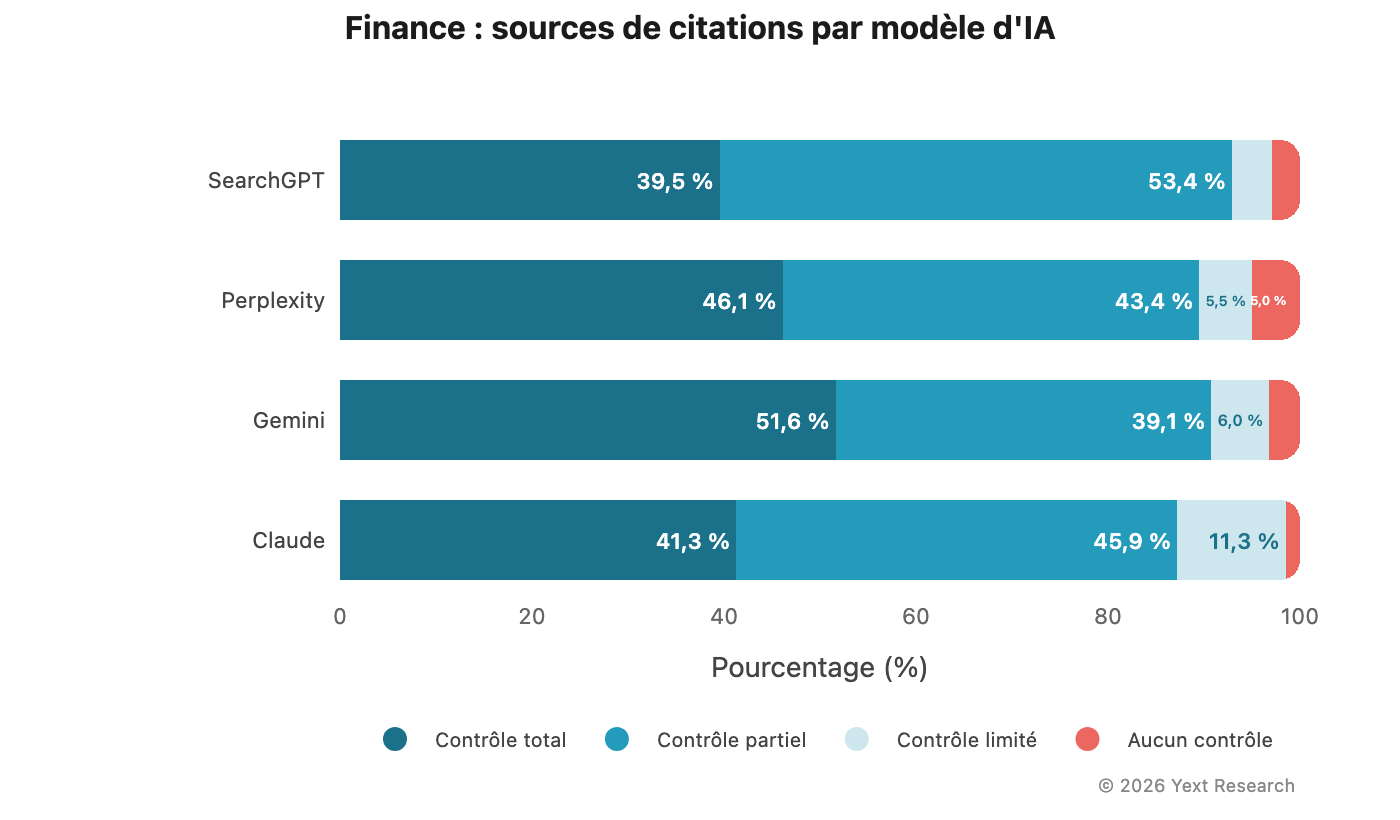
La part de la catégorie Total de Gemini (51,62 %) est la plus élevée dans ce secteur, cohérent avec sa proportion élevée de citations issues de sources officielles et autorisées.
Analyse par secteur :
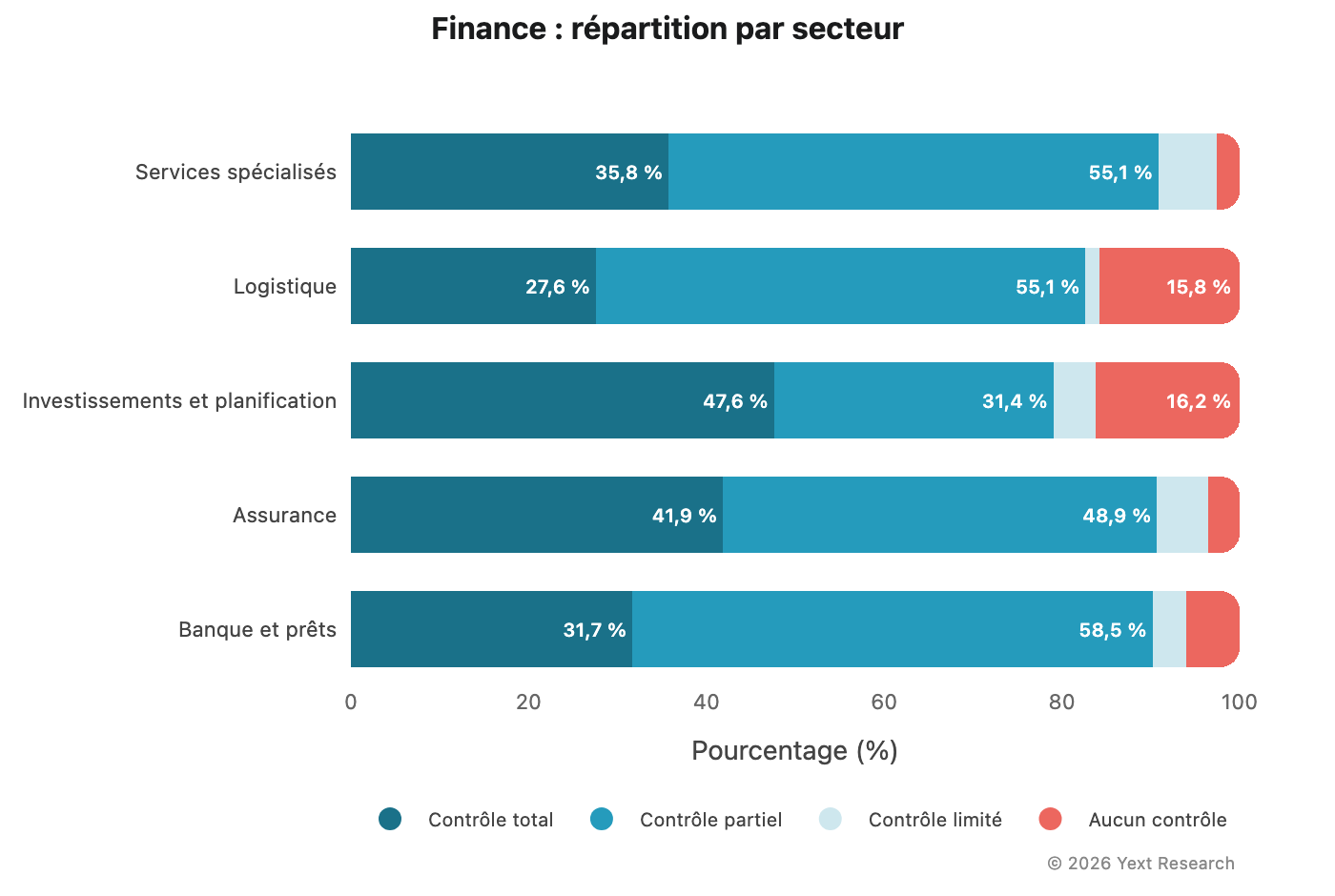
Les services bancaires et de prêt montrent la plus forte préférence pour la catégorie Partiel (58,52 %), suggérant un recours important aux annuaires financiers et aux sites de comparaison. Les segments Investissements et planification, ainsi que Logistique, affichent des niveaux élevés de Aucun contrôle (16,19 % et 15,78 %), ce qui suggère une dépendance accrue aux articles de presse et aux publications financières indépendantes. (Remarque : le secteur des investissements et de la planification ne comprend que 315 URL, ce qui invite à une interprétation prudente.)
Figure 5 : Santé
Le secteur de la santé affiche la plus faible divergence entre modèles :
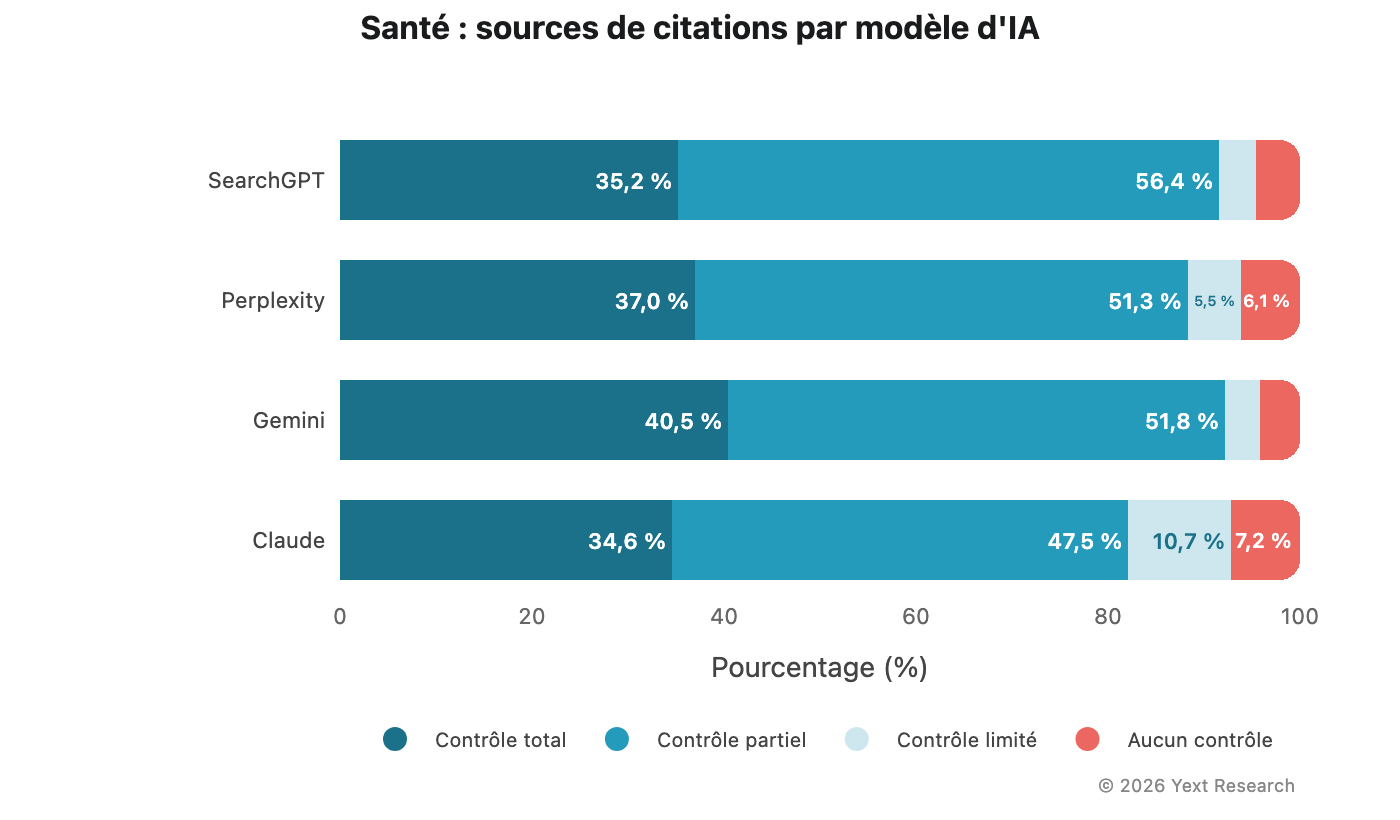
La catégorie Total varie de 34,60 % (Claude) à 40,45 % (Gemini), soit un écart de moins de 6 points de pourcentage. Dans la plupart des autres secteurs, l'écart atteint 10 à 15 points, voire davantage. Les quatre modèles convergent vers un comportement de citation dominé par des sources officielles et des annuaires lorsque le thème est médical.
Cette convergence est notable précisément parce qu'elle contraste avec les autres secteurs. Elle peut refléter une sensibilité partagée à la précision des informations médicales entre différentes architectures de modèles, ou la structure même des sources médicales disponibles, souvent dominées par de grandes plateformes d'annuaires médicaux (comme Zocdoc et Healthgrades aux États-Unis). Ces deux facteurs contribuent sans doute à ce phénomène.
Analyse par secteur :
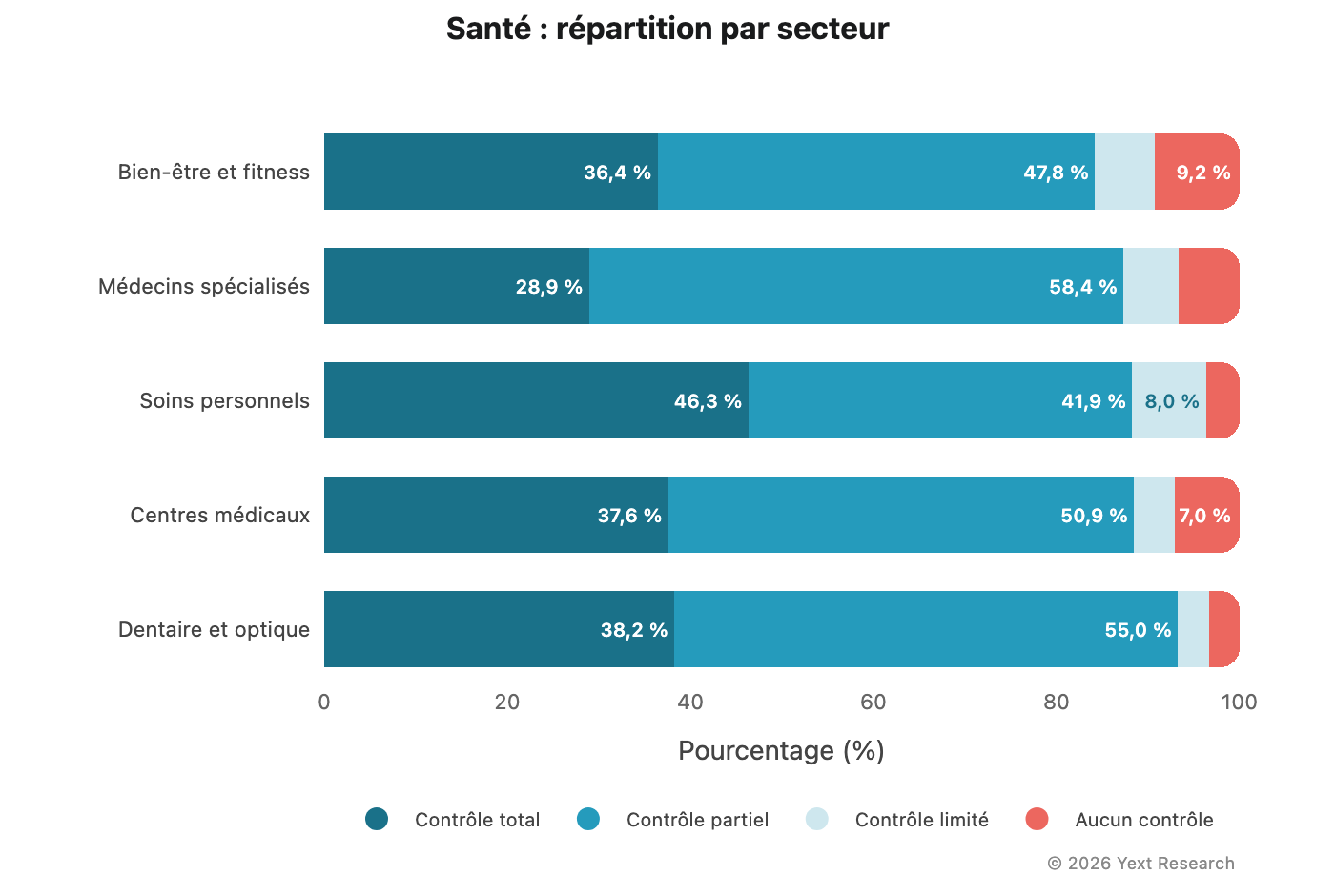
Les médecins spécialisés présentent le taux le plus élevé de Partiel (58,39 %), indiquant le rôle central des annuaires médicaux dans la visibilité en ligne des spécialistes.
Figure 6 : Alimentation et boissons
Le secteur de l'alimentation et des boissons est celui où la part de la catégorie Contrôle limité est la plus élevée pour Claude :
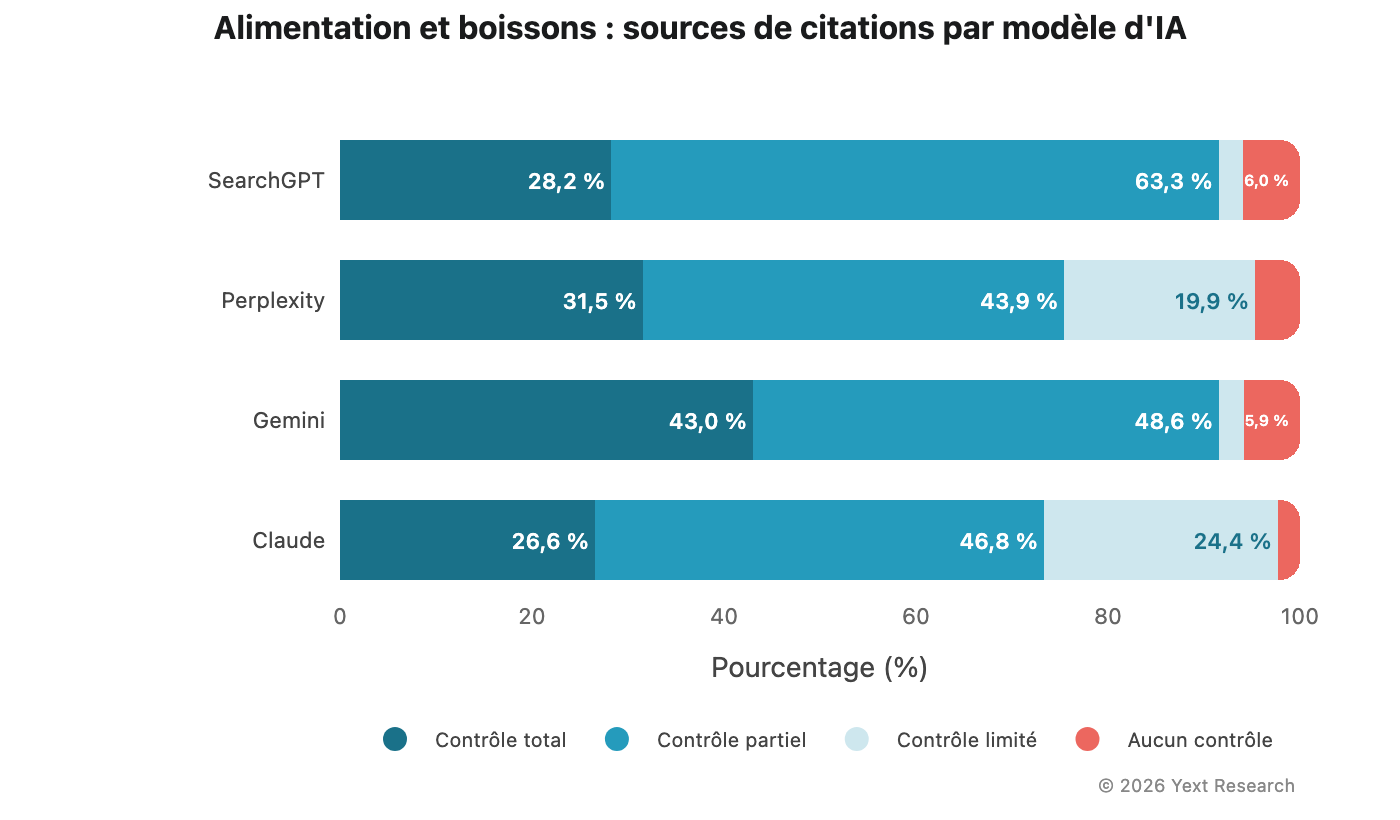
La part de Contrôle limité de Claude (24,35 %) est presque dix fois supérieure à celle de Gemini (2,57 %). Si vous demandez à Claude des informations sur un restaurant, environ une citation sur quatre correspond à un avis ou à une publication sur les réseaux sociaux. Si vous posez la même question à Gemini, ce ratio descend à une sur quarante.
Analyse par secteur :
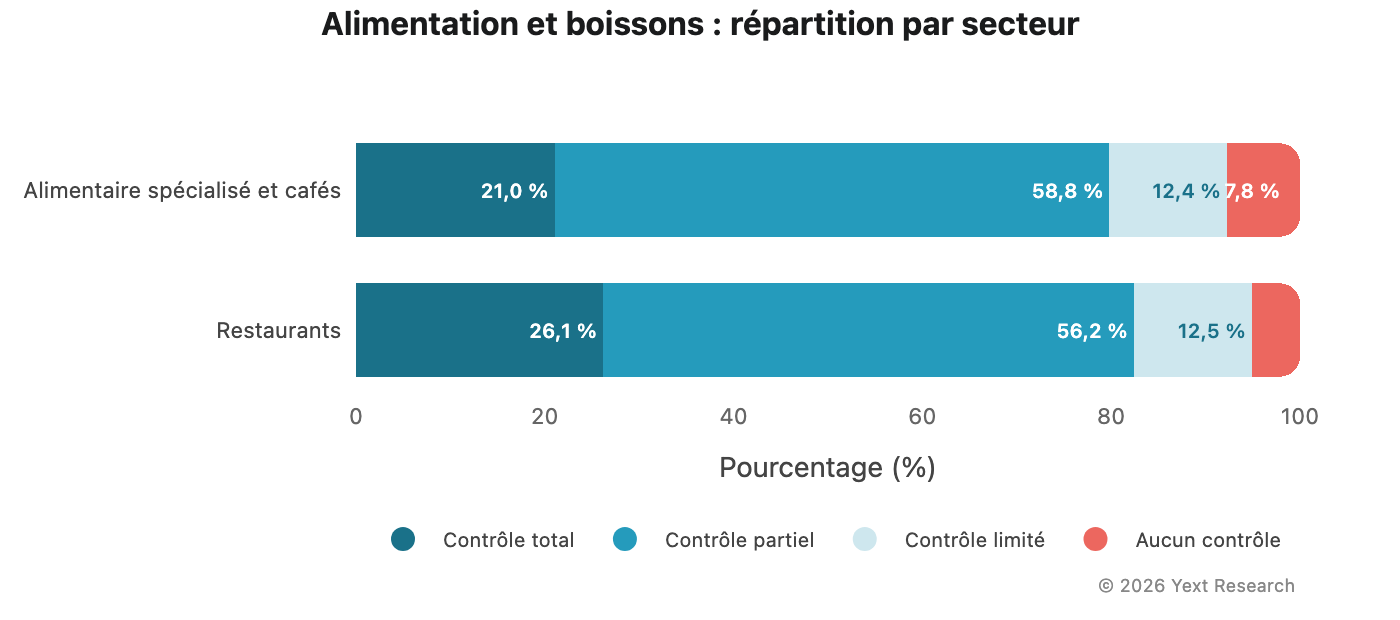
Les deux secteurs présentent des niveaux similaires de Contrôle limité (~12,5 %), mais les commerces alimentaires spécialisés et cafés ont un niveau plus faible de Total (21,03 % contre 26,15 %) et un niveau plus élevé de Aucun contrôle (7,75 % contre 5,12 %), ce qui reflète un recours plus important aux blogs culinaires et aux avis indépendants.
Figure 7 : Commerce de détail
Le commerce de détail présente des variations modérées entre modèles, avec une distribution des citations relativement équilibrée :
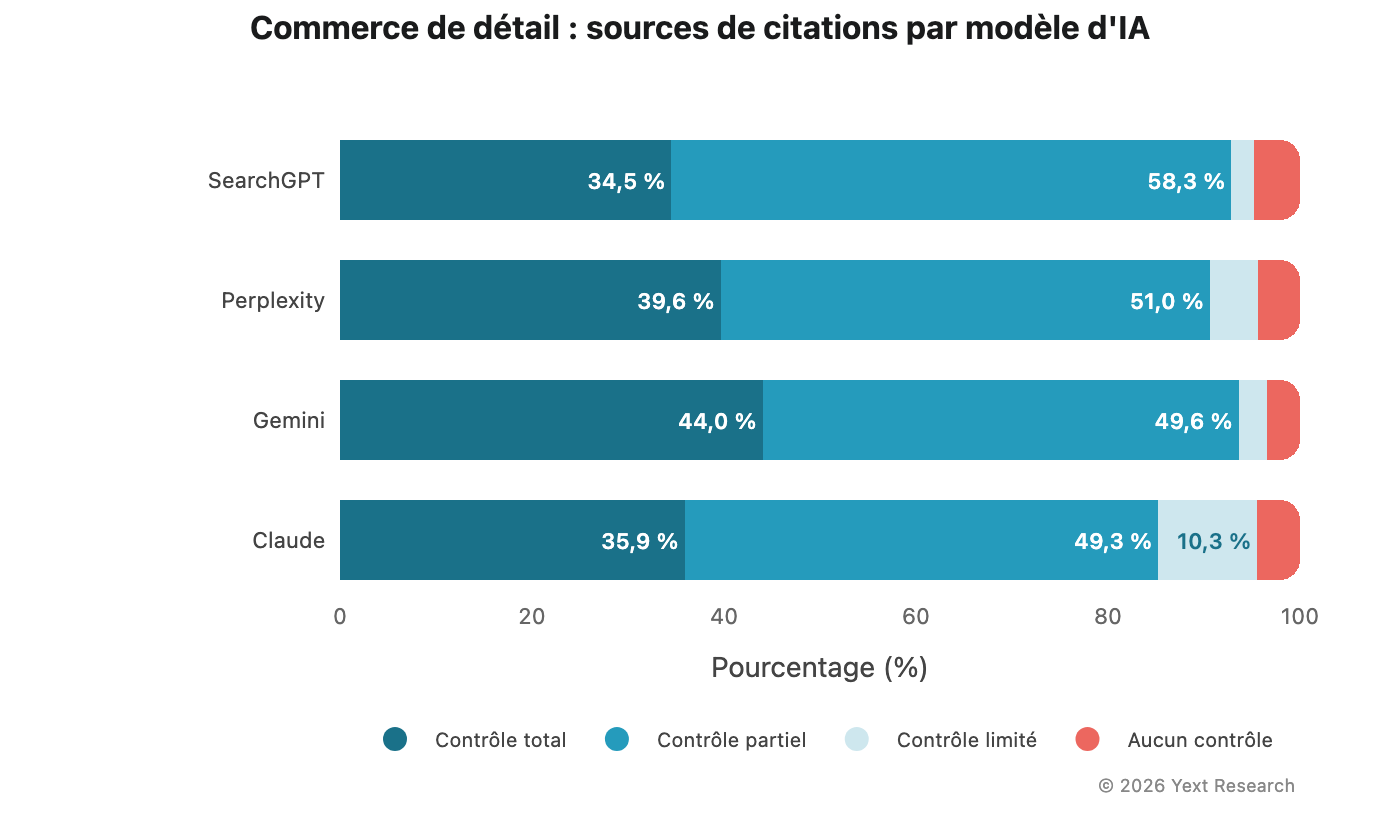
Analyse par secteur :
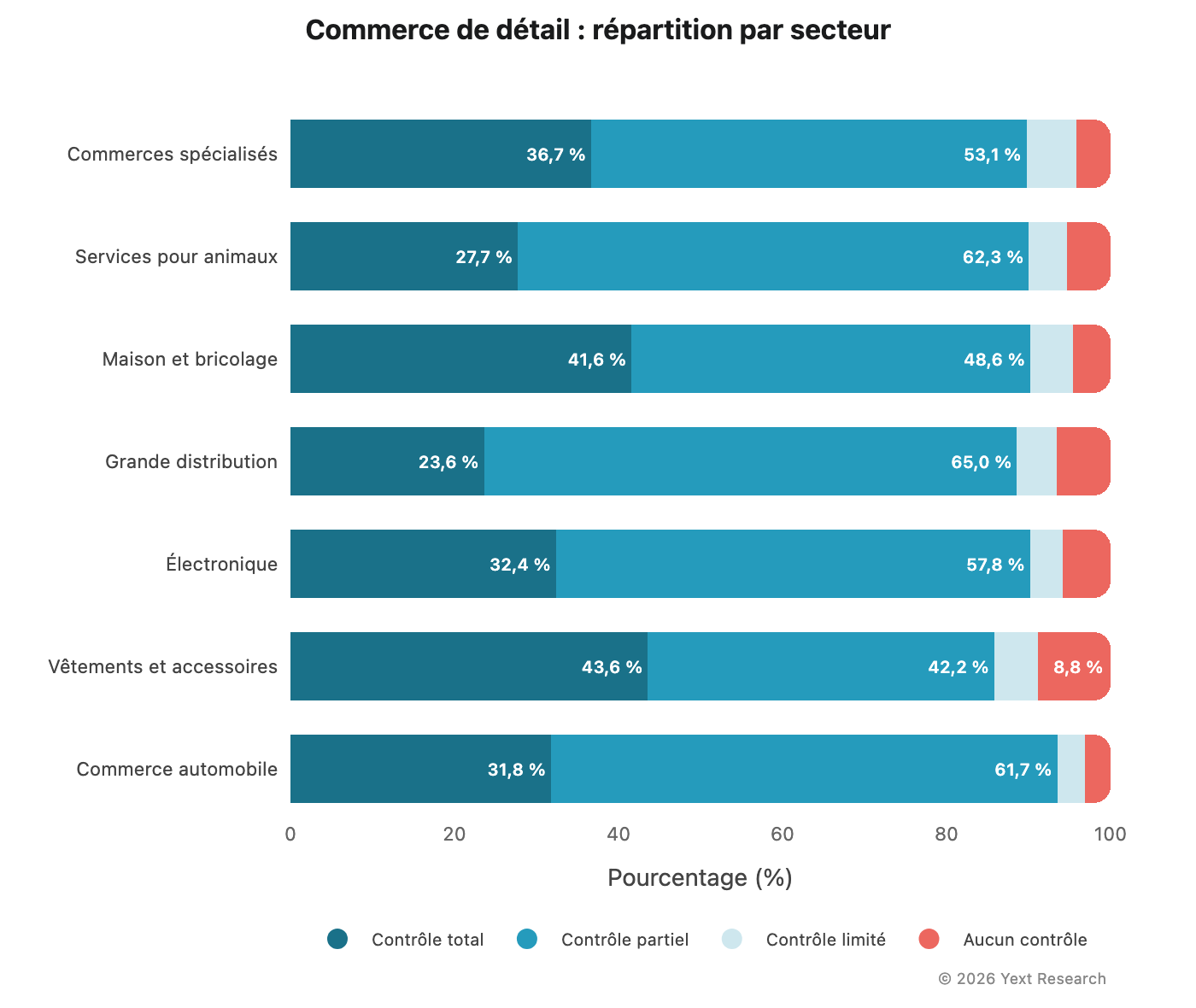
Les marchandises générales présentent le taux le plus élevé de Partiel (64,99 %) et le taux le plus faible de Total (23,60 %), ce qui suggère un recours important aux agrégateurs et aux sites de comparaison. Les vêtements et accessoires présentent le taux le plus élevé de Aucun contrôle (8,82 %), ce qui peut être lié à l'influence des publications de mode et des blogs spécialisés.
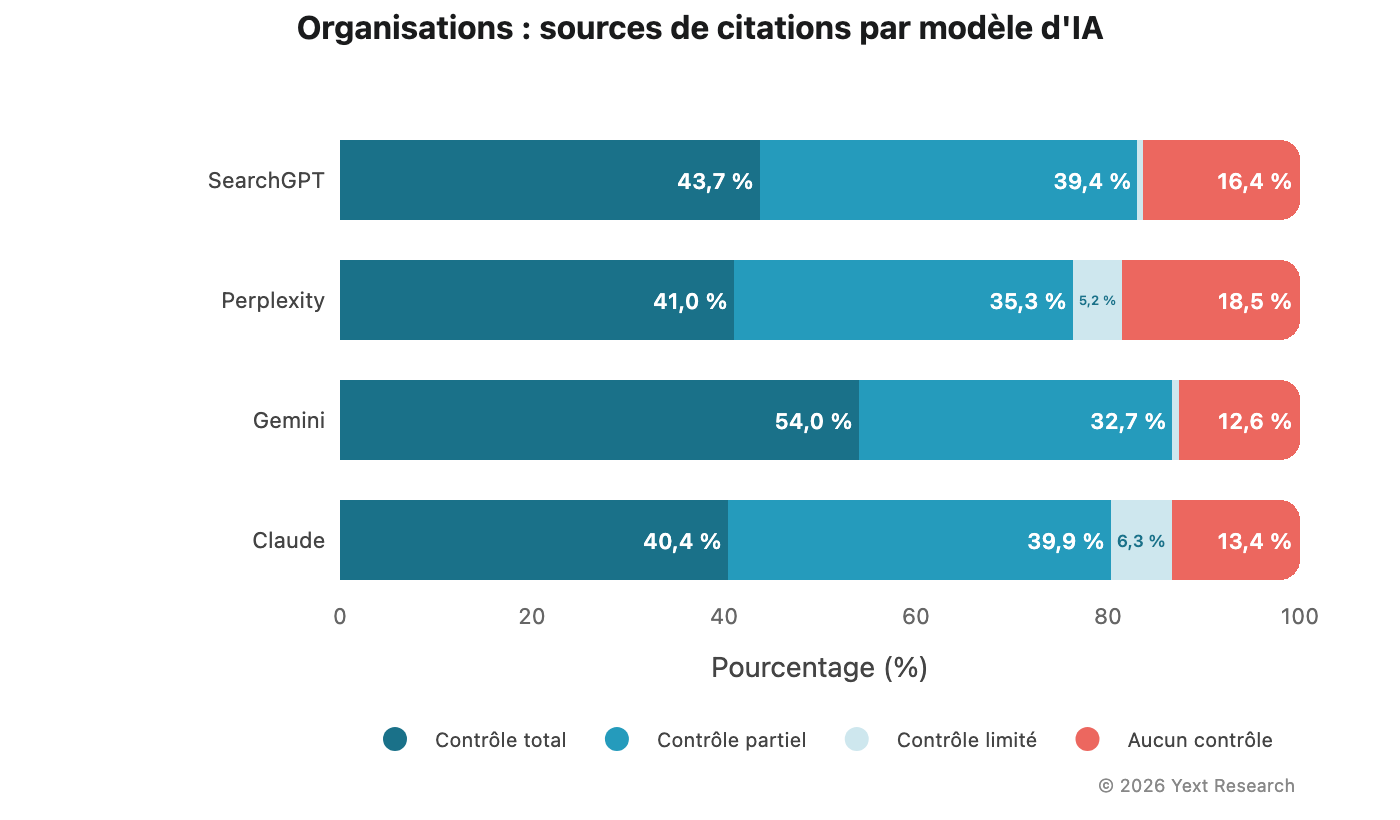
Figure 8 : Organisations
Les organisations (associations à but non lucratif et institutions religieuses) affichent une proportion exceptionnellement élevée de citations relevant de la catégorie Aucun contrôle :
Le taux de Aucun contrôle varie de 12,58 % (Gemini) à 18,53 % (Perplexity), nettement supérieur aux niveaux observés dans les autres secteurs. Ce constat est cohérent : les associations et les organisations religieuses sont plus fréquemment mentionnées dans la presse et les publications communautaires qu'elles ne publient elles-mêmes de contenu facilement découvrable.
Analyse par secteur :
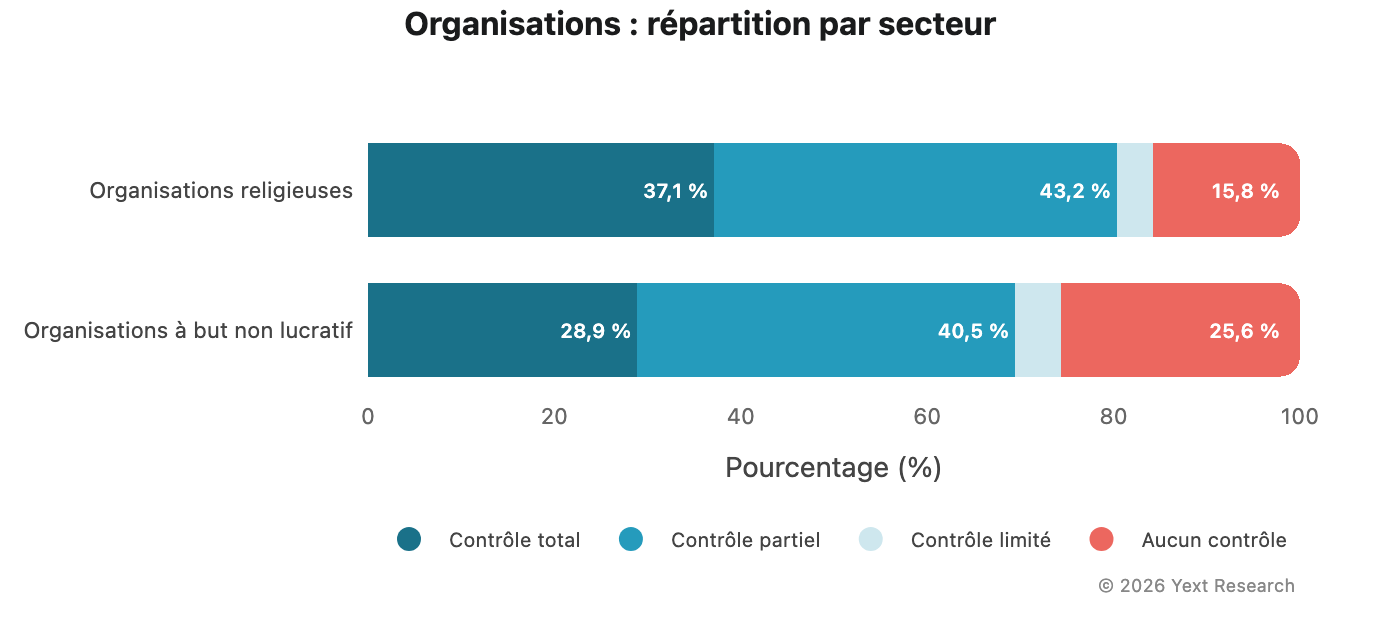
Les organisations à but non lucratif affichent une proportion élevée de citations relevant de la catégorie Aucun contrôle (25,62 %). Pour ces organisations, la visibilité dans la recherche IA repose en grande partie sur des sources externes.
Figure 9 : La dépendance de Claude à la catégorie Contrôle limité
La surreprésentation de la catégorie Contrôle limité dans les réponses de Claude constitue le schéma transversal le plus constant observé dans les données :
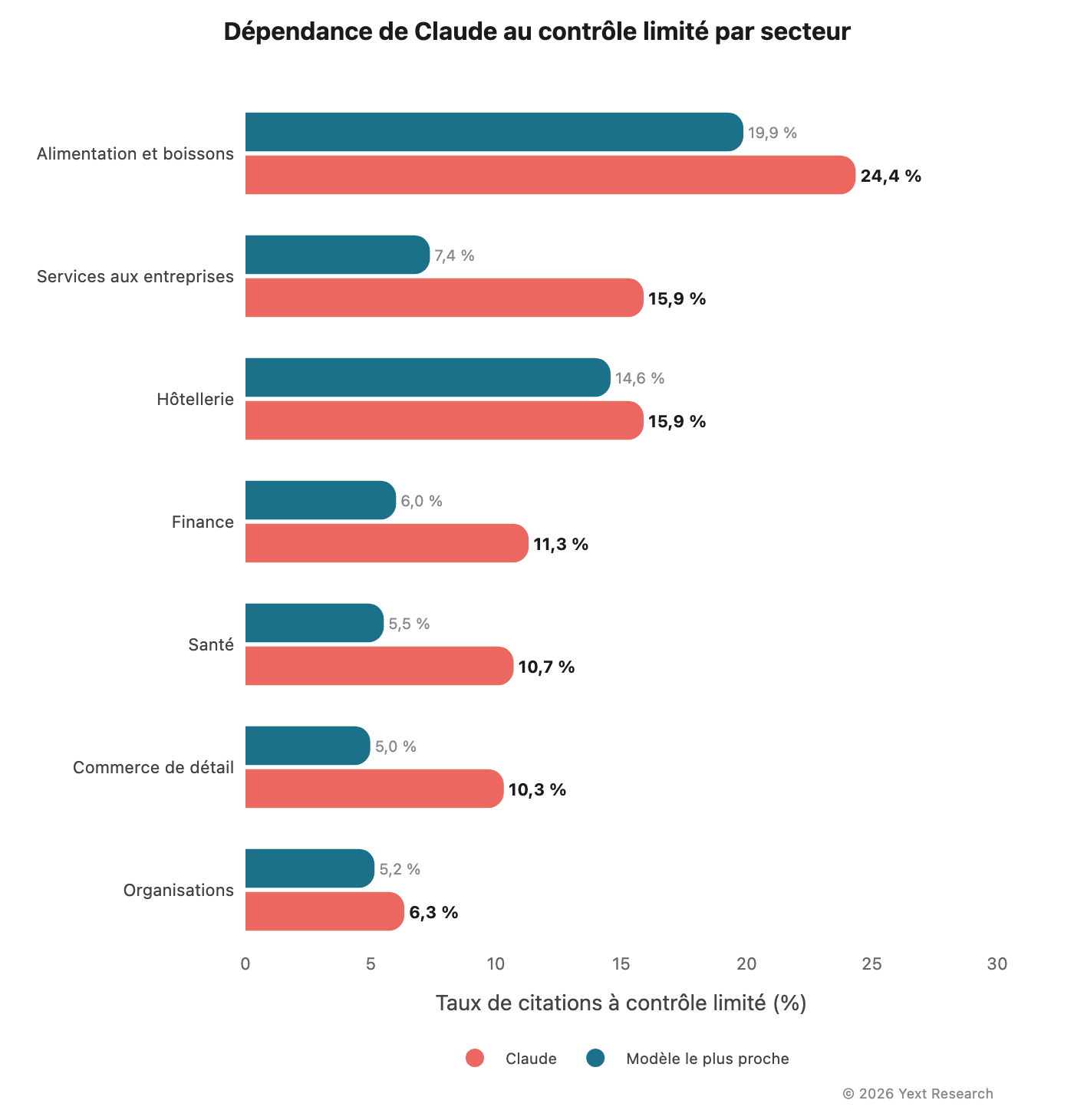
Dans les sept secteurs, Claude affiche la part la plus élevée de citations relevant de la catégorie Contrôle limité. Aucun autre modèle ne présente un schéma aussi constant sur un indicateur unique.
Figure 10 : Résumé par secteur
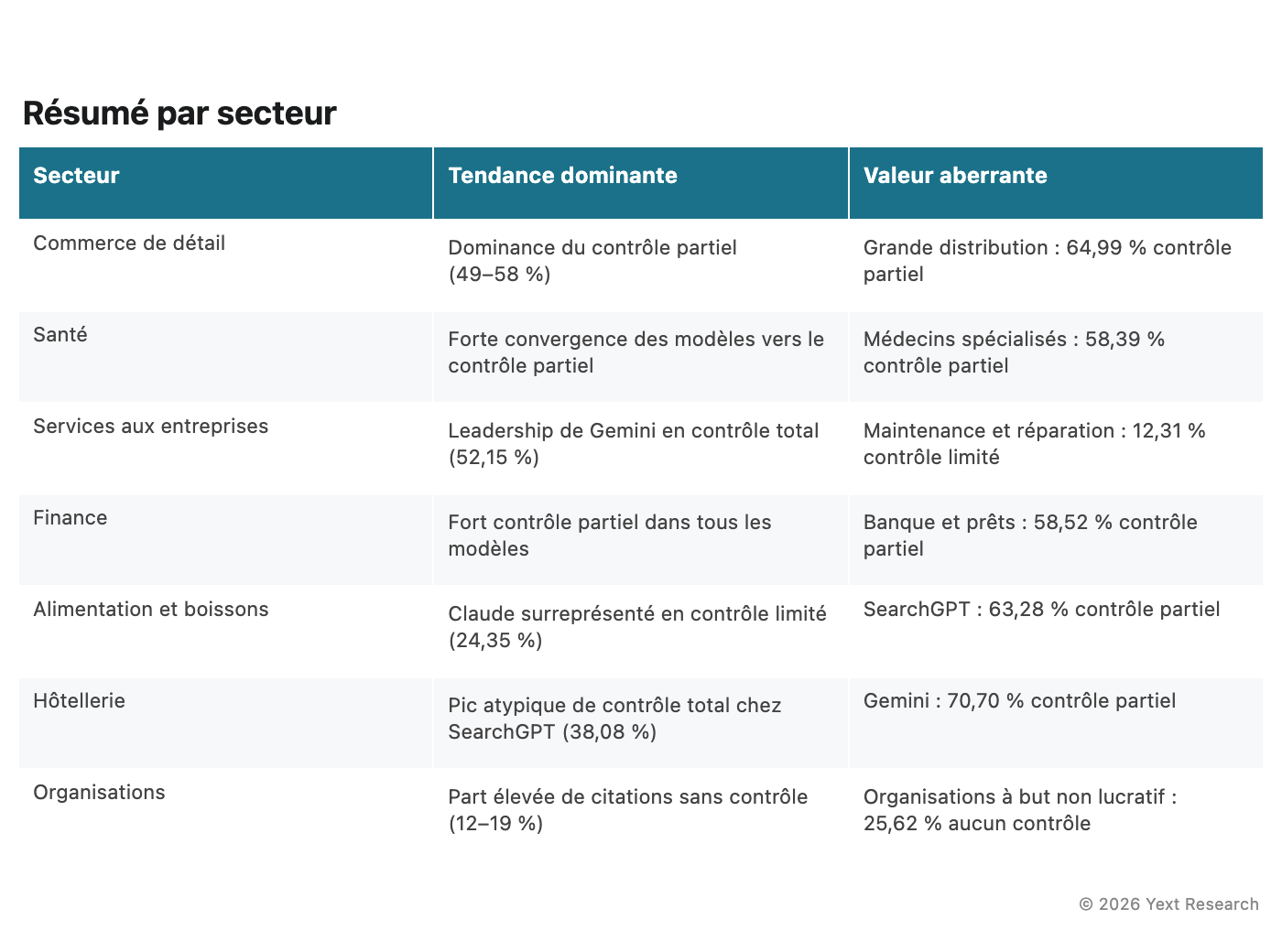
Discussion
Architecture des modèles et comportement de citation
Les schémas de citation observés ne sont ni aléatoires ni uniquement le fruit de paramètres éditoriaux. Ils reflètent les mécanismes par lesquels chaque architecture sélectionne et évalue les sources. Comprendre ces différences aide à expliquer les résultats observés.
Perplexity (RAG centrée sur la recherche) : Perplexity fonctionne comme un moteur de recherche, en déclenchant une recherche web dans son propre index pour chaque requête. La plupart du temps, les résultats s'appuient fortement sur des « passages directement exploitables pour la réponse » pouvant être directement cités. Cette architecture explique la cohérence de Perplexity entre les secteurs. Le système de récupération privilégie la stabilité plutôt qu'une adaptation fortement contextuelle.
SearchGPT (RAG avec récupération externe) : Le modèle de base de SearchGPT ne peut pas accéder directement au web, il s'appuie donc sur une couche de récupération pour obtenir des résultats, puis synthétise les réponses. À ce jour, aucune preuve publiée n'indique que ChatGPT évalue en interne les domaines selon leur fiabilité, leur autorité ou des critères de type E-E-A-T. Un tel comportement refléterait davantage la couche de récupération en amont que le modèle lui-même. Cela peut expliquer la forte variabilité sectorielle observée. Les schémas de citation dépendent fortement de la manière dont la couche de récupération est configurée selon les différents types de requêtes.
Gemini (ancré dans la recherche) : Gemini est ancré dans la recherche, avec des citations provenant de l'étape initiale d'ancrage plutôt que des paramètres de base du modèle. La source d'ancrage est la Recherche Google. Il est donc naturel que les citations tendent à refléter le système de classement de Google. Gemini est une synthèse LLM de la Recherche Google. Améliorer sa visibilité dans Gemini suppose donc de maintenir une forte performance en référencement traditionnel.
Claude (IA constitutionnelle) : Claude utilise une architecture RAG comme les autres modèles, mais se distingue par la manière dont il évalue la qualité des citations. Ce qui distingue Claude, c'est l'IA constitutionnelle, une méthode dans laquelle un ensemble écrit de principes guide l'entraînement et l'évaluation. Le modèle critique et révise ses propres réponses en se référant à une « constitution » plutôt que de s'appuyer uniquement sur des préférences humaines. Ce mécanisme influence l'évaluation de la qualité, de la sécurité et de l'exhaustivité des réponses, sans pour autant constituer un algorithme distinct de classement des citations. La préférence élevée de Claude pour les sources à Contrôle limité pourrait s'expliquer par des principes issus de son approche constitutionnelle, susceptibles d'accorder davantage de poids à des sources diverses validées par les utilisateurs comme signaux de pertinence réelle. Il peut également s'agir d'un artefact lié à la composition des données d'entraînement. Les données disponibles ne permettent pas de déterminer laquelle de ces hypothèses est la plus probable.
Limites
Cette analyse comporte plusieurs limites qu'il est important de préciser :
-
Corrélation et non causalité. Les données décrivent les schémas de citation, mais n'en expliquent pas les causes. La discussion sur l'architecture avance des hypothèses plausibles, mais non confirmées.
-
Instantané dans le temps. Ces données concernent le quatrième trimestre 2025. Les modèles sont mis à jour fréquemment et ces mises à jour peuvent modifier les schémas de citation. La stabilité de ces schémas dans le temps reste incertaine.
-
Biais géographique. Bien que les données aient été collectées à l'échelle mondiale, la majorité des requêtes provenaient des États-Unis. Les marchés internationaux sont susceptibles de présenter des schémas distincts.
-
Décisions de classification. La classification des sources repose sur des choix méthodologiques et interprétatifs. Certains cas limites (sites web de franchise, avis agrégés) pourraient faire l'objet d'une classification différente selon les chercheurs.
-
Petites tailles d'échantillon dans certaines industries. Les investissements et la planification (315 URL), les services spécialisés (114 URL) et l'industrie (2 677 URL) présentent des volumes trop limités pour permettre des conclusions fiables lorsqu'ils sont analysés isolément.
Pistes de recherche futures
-
Stabilité dans le temps. Ces schémas persistent-ils après les mises à jour des modèles ou reflètent-ils des effets temporaires ? Une analyse longitudinale serait nécessaire pour répondre à cette question.
-
Impact sur les consommateurs. Comment les types de sources citées influencent-ils réellement les décisions d'achat ? Le lien entre visibilité dans les citations et comportement des consommateurs reste à établir.
-
Variation internationale. Ces schémas se vérifient-ils en dehors des États-Unis ? Les environnements réglementaires et la disponibilité des sources varient selon les régions.
-
Effets de sélection de modèles. Les consommateurs ayant différentes préférences en matière de recherche d'information se tournent-ils vers les modèles dont le comportement de citation correspond le mieux à leurs besoins ? Il s'agit d'une hypothèse testable qui n'a pas encore fait l'objet d'une validation empirique.
Conclusion
Version simplifiée : les modèles d'IA ne citent pas de la même manière, et ces écarts sont suffisamment marqués pour influencer la visibilité des marques.
Gemini privilégie les sites officiels, ce qui est cohérent avec son ancrage dans la Recherche Google. Claude présente des niveaux de citations issues de contenu généré par les utilisateurs deux à quatre fois supérieurs à ceux observés pour les autres modèles. SearchGPT présente de fortes variations selon les secteurs, avec une préférence particulièrement marquée pour les sites officiels d'hôtels. Perplexity affiche le profil le plus cohérent d'un secteur à l'autre.
Ces schémas varient davantage à l'intérieur d'un même secteur qu'entre secteurs différents. Une marque active dans les services bancaires et de prêt évolue dans un environnement de citation différent de celui d'une entreprise d'assurance, même si les deux relèvent du même secteur global.
Il n'est pas encore possible de déterminer la durabilité de ces schémas et leur influence directe sur les décisions des consommateurs. Les architectures des modèles évoluent et les systèmes de récupération sont régulièrement mis à jour. Les schémas observés au quatrième trimestre 2025 pourraient différer d'ici mi-2026.
En revanche, la dynamique fondamentale est moins susceptible d'évoluer : des modèles différents, des préférences de sources distinctes et des résultats de visibilité divergents. Les entreprises qui considèrent la recherche par IA comme un canal unique à optimiser reposent sur une hypothèse que les données actuelles ne corroborent pas.
Annexe
Définitions des catégories de contrôle
| Catégorie | Définition complète |
|---|---|
| Total | Contenu entièrement créé et hébergé par l'entreprise. Inclut les sites web officiels, blogs de marque, salles de presse d'entreprise et pages de destination propriétaires. Les marques ont un contrôle éditorial complet sur le message, l'exactitude et la présentation. |
| Partiel | Annuaires et plateformes tierces sur lesquels une marque peut revendiquer et gérer son profil. Bien que la marque ne soit pas propriétaire de la plateforme, elle peut contrôler directement l'exactitude des informations. Inclut les fiches d'établissement Google, MapQuest et les annuaires sectoriels spécialisés. |
| Contrôle limité | Plateformes où le contenu est principalement généré par les utilisateurs, mais où les marques peuvent participer activement via des réponses, de l'engagement et la gestion de leur réputation. Inclut les avis Google, Yelp, Facebook et les plateformes de réseaux sociaux. |
| Aucun contrôle | Sources sur lesquelles la marque n'exerce pas de contrôle direct. Inclut les articles de presse, les discussions Reddit, les forums, le contenu généré par les utilisateurs et les publications indépendantes. |
Travaux précédents
Cette analyse s'appuie sur des travaux précédents de Yext Research sur les citations IA et les archétypes de recherche IA :
- Citations IA, localisation des utilisateurs et contexte des requêtes
- Best Practices Will Only Take You So Far (Les bonnes pratiques ont leurs limites)
- L'essor des archétypes de recherche IA
À propos de Yext Research
Yext Research mène des analyses indépendantes du comportement de citation des IA à l'aide de la plateforme Yext Scout. Les données sur le comportement des consommateurs sont collectées en partenariat avec Researchscape International.