Citations IA, localisation des utilisateurs et contexte des requêtes
L'analyse de 6,8 millions de citations IA à l'échelle locale révèle pourquoi le contexte géographique doit être la base d'une stratégie de visibilité de marque
Christian Ward, Anthony Rinaldi, Adam Abernathy et Alan Ai, 2025
9 oct. 2025
Introduction
Cette étude analyse 6,8 millions de citations issues de 1,6 million de réponses générées par les trois principaux modèles d'IA. Elle met en lumière l'importance de l'intention de l'utilisateur, de sa localisation et du contexte conversationnel (mémoire) comme cadres essentiels pour comprendre la visibilité dans la recherche par IA.
La plupart des recherches actuelles sur les citations de l'IA adoptent une perspective centrée sur la marque, ignorant la localisation ou le contexte de l'utilisateur. Cette approche axée sur la marque explique pourquoi des sources comme Wikipédia ou Reddit apparaissent souvent parmi les principales citations. Si cette méthode fonctionne bien pour établir la voix de la marque, elle ne reflète pas fidèlement les schémas de citation typiques lorsque les utilisateurs interagissent individuellement avec l'IA.
Une fois l'emplacement de l'utilisateur et le contexte pris en compte, comme c'est souvent le cas pour les questions portant sur des entreprises, les tendances de citation évoluent de manière significative. Les modèles d'IA eux-mêmes déclarent adopter cette approche centrée sur la localisation. Lorsqu'on leur pose directement la question, les modèles de Google, OpenAI et Perplexity confirment qu'ils utilisent la position des consommateurs pour répondre aux questions sur des entreprises et des services.
Pour mesurer ce que cela implique, nous avons testé des requêtes axées sur la localisation dans quatre grands secteurs. À partir d'un modèle systématique à quatre quadrants (avec marque/sans marque et objectif/subjectif), nous en avons conclu qu'il existait des différences évidentes dans la manière dont les plateformes d'IA recherchent et citent les informations. En raison des variations selon le secteur, le type de requête et le contexte du consommateur, l'analyse localisée s'impose comme un pilier des stratégies de visibilité dans la recherche par IA.
Cette recherche propose une voie claire et stratégique permettant aux marques de renforcer leur visibilité locale dans la recherche par IA.
Résultats clés
L'analyse par localisation révèle des schémas de citation et de source indétectables dans les études actuelles centrées sur la marque. Ainsi, une chaîne de magasins peut afficher un taux national de citations internes de 47 %, mais l'analyse par localisation peut révéler 70 % dans les zones rurales et 20 % dans les marchés urbains compétitifs, où les agrégateurs sont plus présents. En raison de ces variations géographiques, les indicateurs nationaux sont moins utiles pour une stratégie de visibilité locale.
- Les avis de première main constituent une source clé pour les requêtes factuelles. Lorsque les consommateurs posent des questions objectives et sans marque (par exemple, « Quelles sont les boulangeries près de chez moi ? »), les sites web sont la principale source de citations pour les trois modèles (plus de 40 % des citations pour Gemini, OpenAI et Perplexity). Pour les marques, c'est le signe qu'elles doivent contrôler leur image en fournissant des informations claires et factuelles sur leurs sites web.
- La forte dépendance d'OpenAI aux annuaires pour les requêtes subjectives. Lorsqu'une requête devient subjective (par exemple : « Quel est le meilleur… ? »), le comportement de citation d'OpenAI change radicalement. Pour les requêtes subjectives, qu'elles soient liées ou non à une marque, les annuaires tiers deviennent une source principale, atteignant 46,3 % pour les questions subjectives liées à une marque. Autrement dit, sur OpenAI, la présence d'une marque dans les annuaires est déterminante pour les requêtes d'opinion.
- L'accent mis sur les annuaires sectoriels privilégiés par Perplexity. Perplexity accorde une préférence nette aux annuaires spécialisés par secteur, surtout pour les requêtes subjectives où l'expertise joue un rôle décisif. Pour les requêtes subjectives non liées à une marque, ces annuaires spécialisés représentent 24 % de ses citations, le taux le plus élevé parmi les modèles analysés. Cela indique que pour Perplexity, l'optimisation sur des plateformes de niche et pertinentes pour le secteur constitue un levier stratégique clé.
- L'importance stratégique sous-estimée des sites web locaux. Dans presque tous les modèles et types de requêtes, les sites locaux représentent une source de citation importante, allant de 8 % à près de 20 % dans certains cas (par exemple : requêtes objectives non liées à une marque sur Gemini). Cela souligne l'importance stratégique de maintenir, pour chaque établissement, des pages locales distinctes et riches en contenu.
La recherche par IA du point de vue du consommateur
Envisager les citations IA d’un point de vue global ne suffit pas. Une analyse localisée est nécessaire pour intégrer les comportements réels des utilisateurs. Une analyse au niveau de la marque doit tenir compte des comportements réalistes des utilisateurs en agrégeant des requêtes d'IA précises et basées sur la localisation dans leur contexte, un processus qui révèle des schémas de citation bien plus précis et exploitables.
La visibilité dans la recherche par IA n'est pas monolithique : le comportement de références varie selon la localisation du consommateur, le contexte de la question, le secteur, le modèle d'IA et les sources citées elles-mêmes.
La relation entre le niveau de contrôle d'une marque, l'effort requis et l'utilisation des citations IA qui en résulte permet de codifier efficacement la hiérarchisation des mesures.
Le cadre Localisation-contexte
La visibilité dans la recherche par IA doit être analysée à travers le prisme du consommateur. Pour étudier de manière systématique le comportement de l'IA sous l'angle du consommateur, nous avons développé le cadre Localisation-Contexte, un modèle qui part de la localisation de l'utilisateur, puis intègre les types de questions afin de comprendre les schémas de citation. Cette approche se différencie des analyses actuelles centrées sur la marque, qui reposent souvent sur une méthode dite de « fan-out » (déploiement de requêtes), où l'IA génère elle-même des questions dérivées. Si cette méthode est utile pour analyser la perception d'une marque, elle explique aussi pourquoi des sources générales comme Wikipédia ou les forums apparaissent souvent parmi les citations. Cela conduit l'IA à formuler des commentaires plutôt qu'à répondre aux besoins concrets des consommateurs.
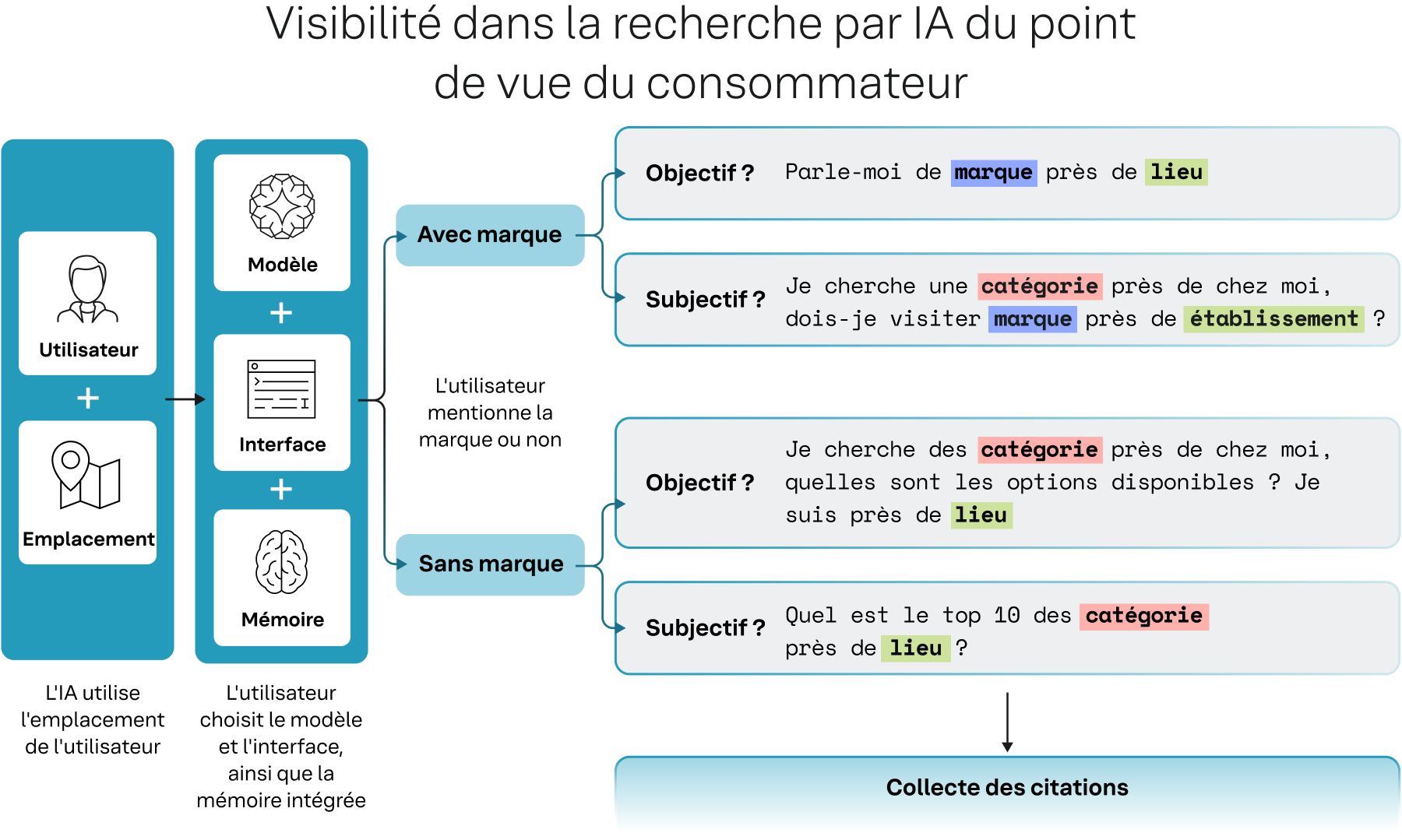 Figure 1 : Au lieu d'un fan-out, notre cadre Localisation-contexte suit un schéma clair et prévisible.
Figure 1 : Au lieu d'un fan-out, notre cadre Localisation-contexte suit un schéma clair et prévisible.
Le cadre Localisation-contexte définit un schéma clair et prévisible qui simule le comportement type d'un consommateur interagissant avec un modèle d'IA sur différents sujets de recherche.
- Un humain a un besoin et se trouve dans un lieu donné. L'IA utilise ce contexte géographique comme filtre fondamental, de la même manière que la recherche classique (Google).
- Le consommateur choisit un modèle (comme Gemini ou ChatGPT) ainsi qu'une interface. Il apporte également sa mémoire conversationnelle à la session, ce qui peut influencer les réponses suivantes.
- Le consommateur formule intrinsèquement sa requête selon deux axes : avec marque ou sans marque, et objectif ou subjectif.
Nos résultats montrent un compromis clair. À mesure qu'une marque augmente son contrôle sur une source, le potentiel d'être citée dans les réponses de l'IA augmente également. Cependant, cela demande souvent un investissement plus élevé. L'opportunité stratégique consiste à trouver le juste équilibre. Les sources dites « sous contrôle total », comme les sites web détenus par la marque, offrent la plus grande efficacité, mais les fiches « contrôlables » sur des plateformes tierces représentent un point d'équilibre clé, générant un volume élevé de citations pour un effort de gestion modéré. Le cadre que nous proposons permet à une marque de dépasser une approche réactive et de concentrer ses ressources de manière proactive sur les activités ayant le plus fort impact sur sa visibilité dans la recherche par IA.
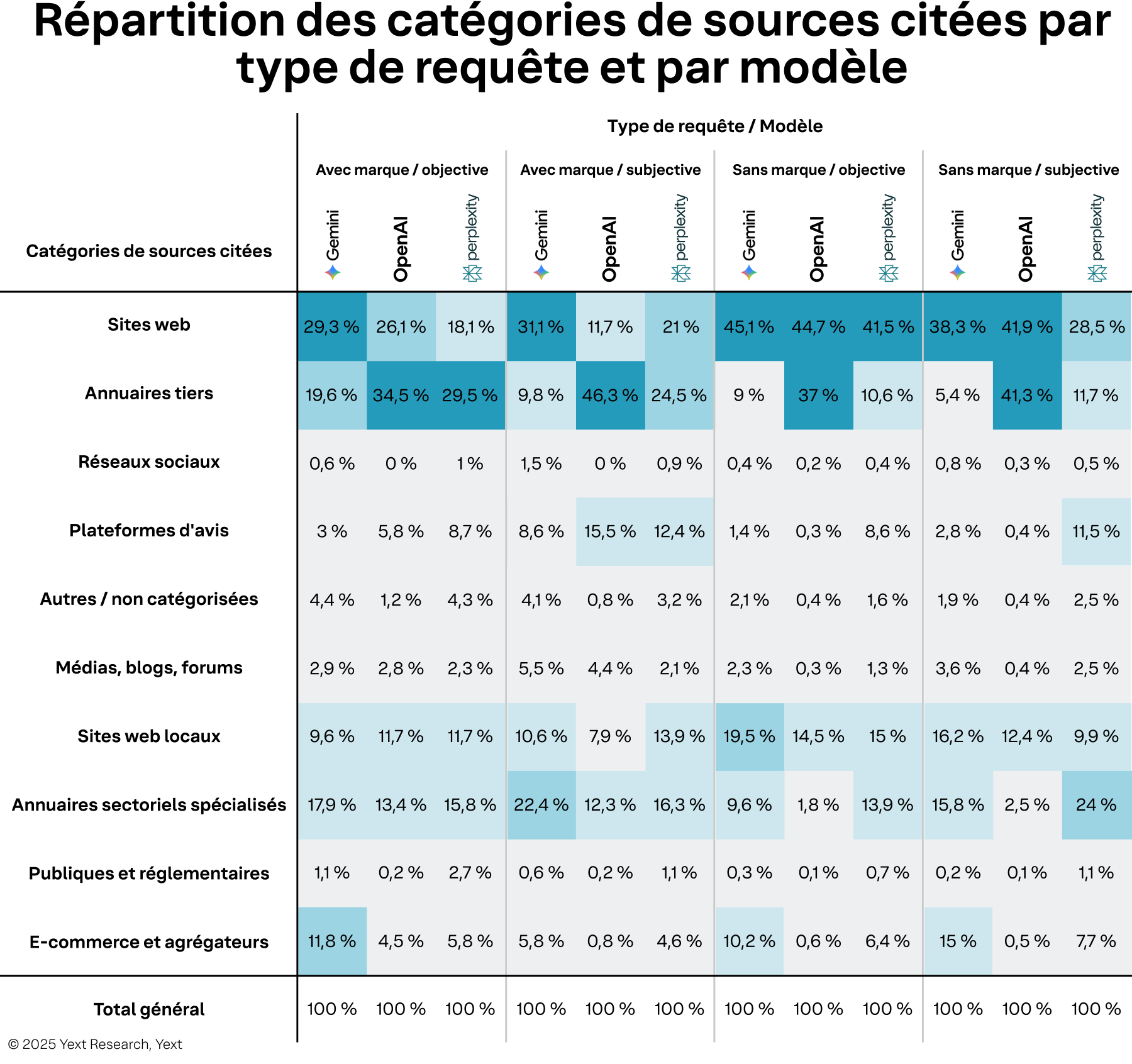 Tableau 1
Tableau 1
Alors que de nombreuses études menées au niveau des marques indiquent que les forums comme Reddit constituent la principale source de citations, l'application d'une perspective géospatiale aux consommateurs révèle que ces sources apparaissent beaucoup moins fréquemment et représentent à peine plus de 2 % (154 000) des citations. Loin de minimiser leur importance pour les commentaires de marque, cette tendance montre que pour les requêtes locales des consommateurs, le rôle des forums change.
Définir les sources de citation de l'IA selon le niveau de contrôle de la marque
Il est nécessaire de catégoriser les sources de citation en fonction de la capacité d'une marque à contrôler les informations qu'elles contiennent. Le cadre de contrôle classe ces sources en quatre catégories distinctes, allant des sources totalement détenues par la marque à celles où elle n'a aucune influence directe. Cette classification stratégique permet à la marque de hiérarchiser ses efforts et de concentrer ses ressources là où elles auront le plus d'impact.
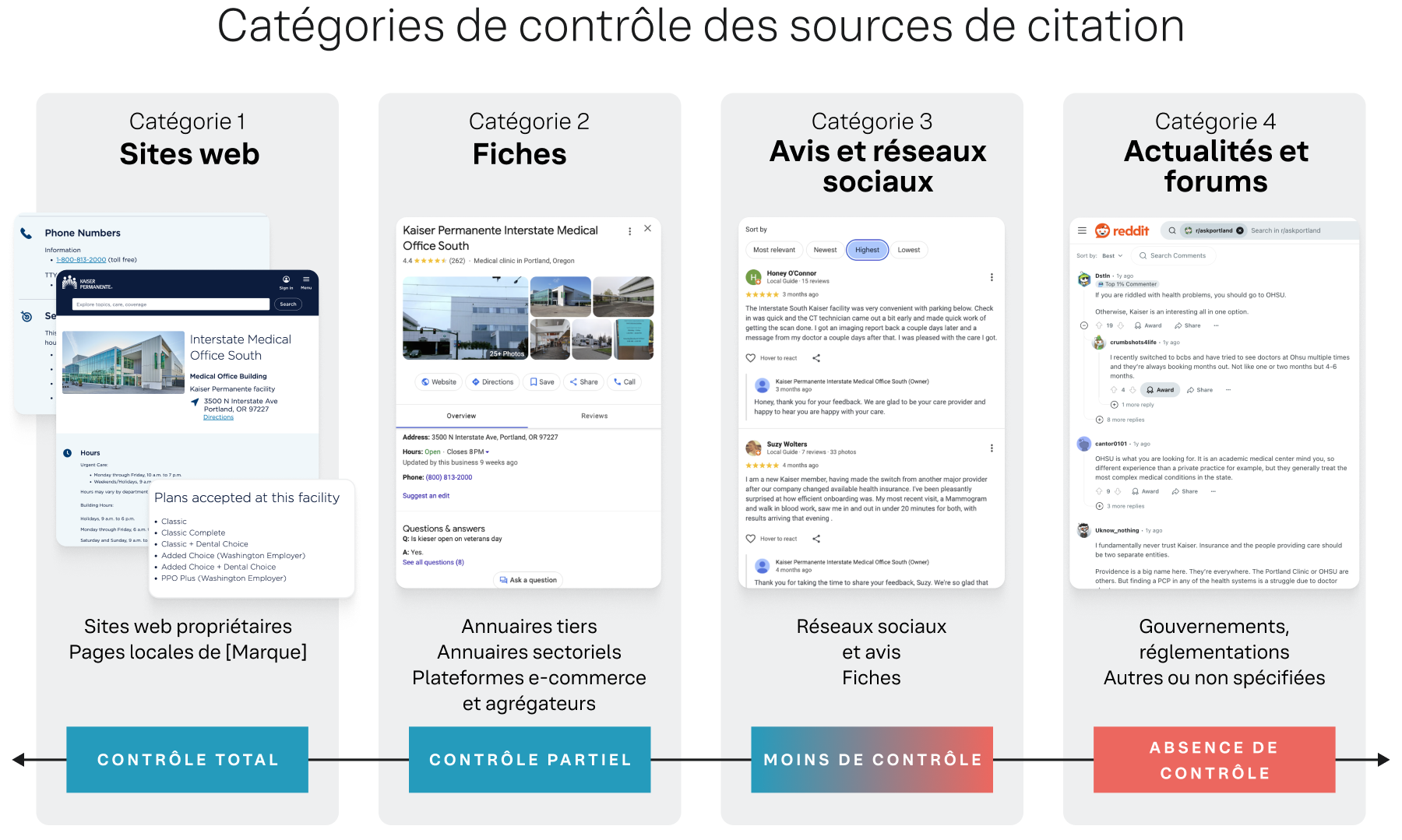 Figure 2
Figure 2
La catégorie 1 : propriétés de marque (sites web) inclut les propriétés numériques de première main d'une marque. Les marques ont un contrôle complet et direct sur tout le contenu. C'est la catégorie la plus citée de l'étude, avec plus de 2,9 millions de citations provenant de domaines d'entreprise (par exemple : briochedoree.fr), de pages locales (par exemple : agences.sg.fr), et d'autres propriétés numériques de marque.
La catégorie 2 : contrôlable (fiches) regroupe un large éventail d'annuaires et de plateformes tiers où une marque peut revendiquer et gérer son profil. Bien que la marque ne soit pas propriétaire de la plateforme, elle peut contrôler directement l'exactitude des informations. Cette catégorie représente plus de 2,9 millions de citations et inclut des plateformes généralistes (fiches d'établissement Google, MapQuest) ainsi que des annuaires spécialisés comme TripAdvisor (Restauration/Hôtellerie) ou Zocdoc (Santé).
La catégorie 3 : influencée (avis et réseaux sociaux) regroupe les plateformes où le contenu est principalement généré par les utilisateurs, mais où les marques peuvent participer activement. Cette catégorie, axée sur la réputation, représente plus de 545 000 citations, issues de sources comme les avis Google, Yelp et Facebook.
La catégorie 4 : non contrôlée (médias, forums, autres) inclut toutes les sources sur lesquelles la marque n'a aucun contrôle direct. Un constat intéressant de cette recherche est le faible nombre de citations pour cette catégorie.
La conclusion la plus significative est encourageante : les marques peuvent influencer ou gérer directement les sources représentant environ 86 % de toutes les citations visibles par les consommateurs. Ce haut degré de contrôle n'apparaît que lorsqu'on passe d'une perspective centrée sur la marque à une analyse par localisation.
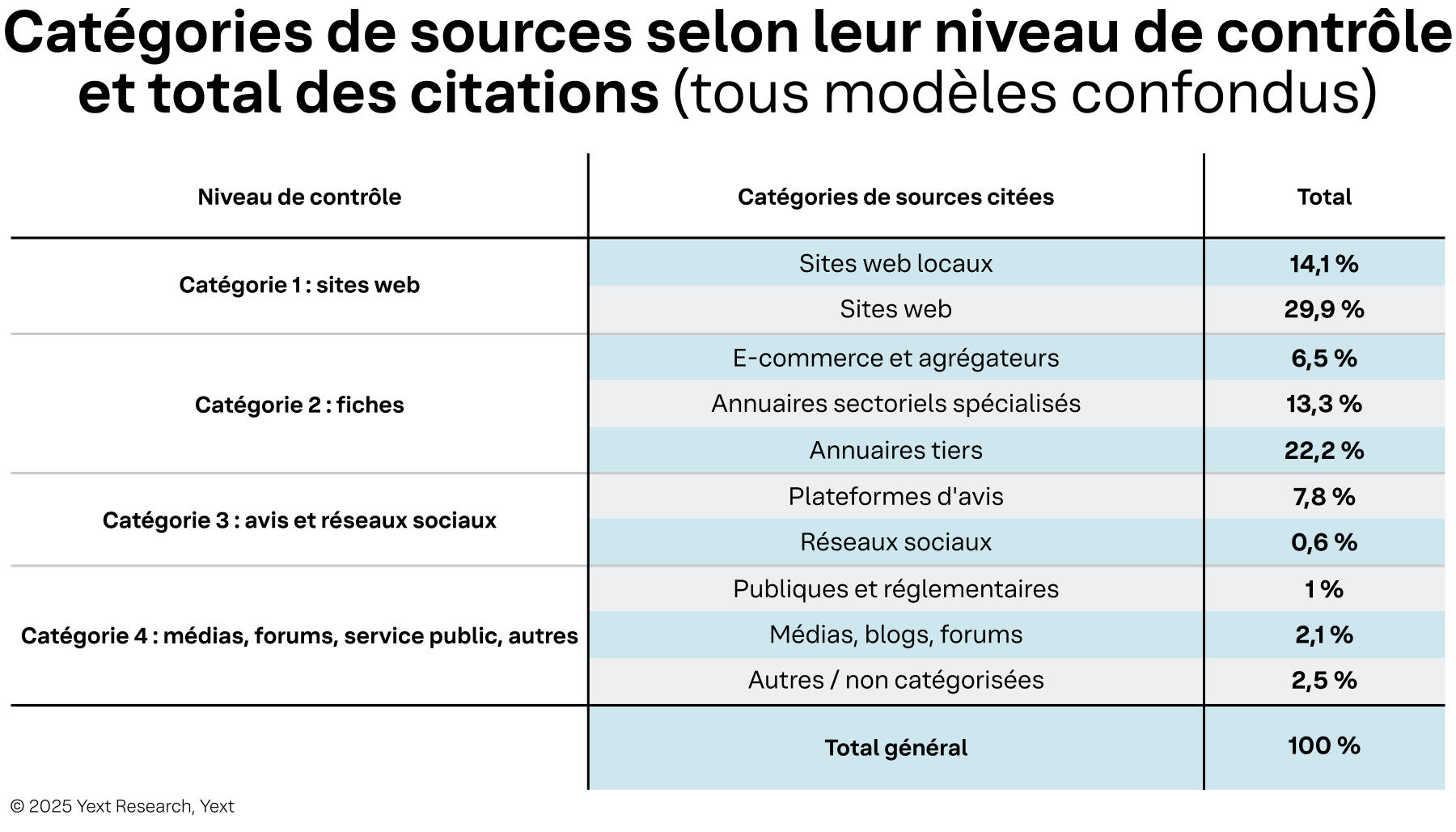 Tableau 2
Tableau 2
En analysant les schémas de citation à un niveau local, pour chaque consommateur, une marque peut agréger ces données pour construire une stratégie précise et opérationnelle visant à améliorer sa visibilité dans la recherche par IA. Sans cette compréhension granulaire, il est presque impossible de définir un chemin clair pour atteindre le consommateur là où il se trouve réellement.
Différences entre les modèles
Le comportement des citations est loin d'être uniforme d'un modèle d'IA à l'autre. Nous constatons en effet que la stratégie de visibilité d'une marque doit tenir compte des préférences de chaque plateforme en matière de source d'information.
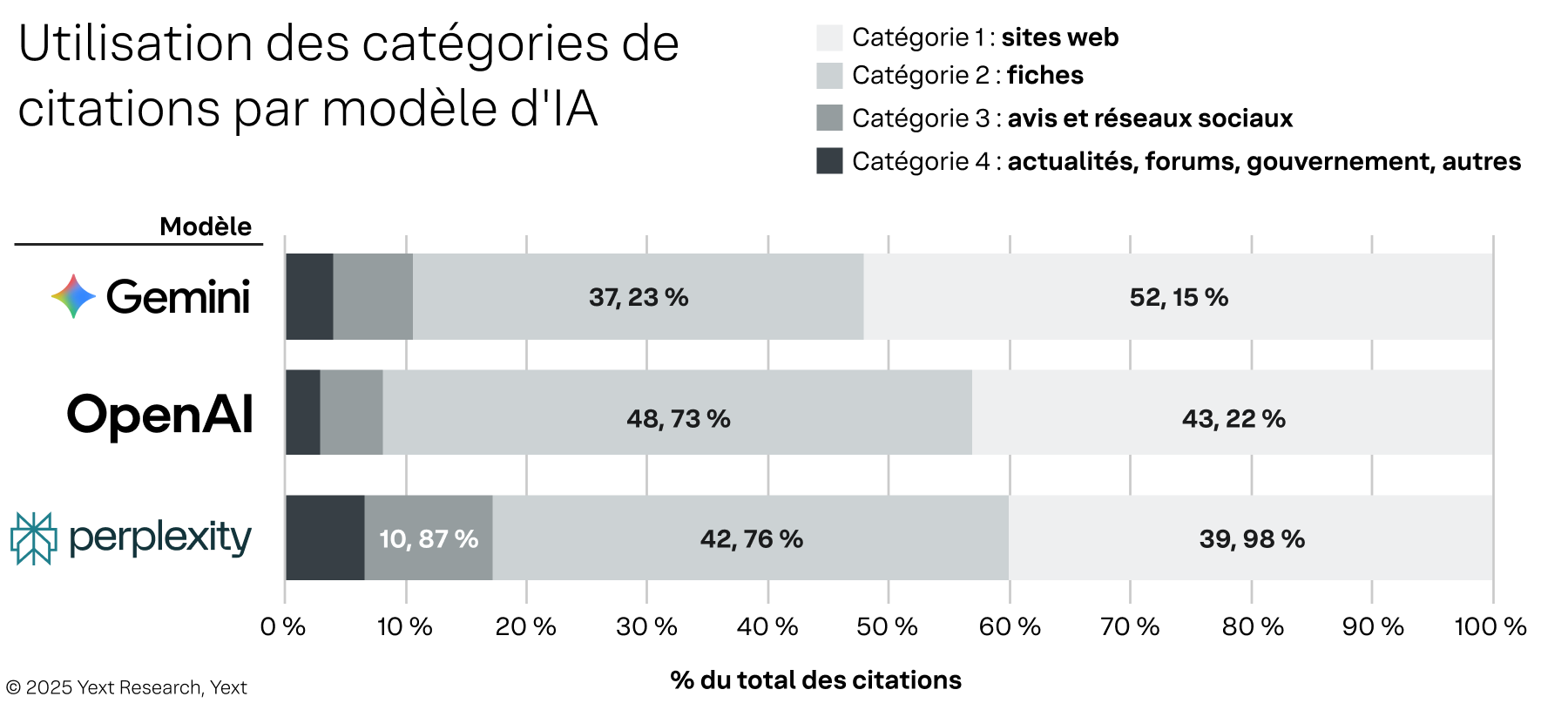 Figure 3
Figure 3
Les préférences de chaque modèle varient sensiblement selon les sources d'information. Gemini montre une forte préférence pour les sites web de première main, tirant 52,15 % de ses citations de ces sources totalement contrôlées. OpenAI, à l'inverse, s'appuie fortement sur les fiches, avec 48,73 % de ses citations issues de ces plateformes tierces contrôlables. Ces préférences deviennent encore plus marquées lorsqu'on examine les domaines individuels. La dépendance d'OpenAI aux fiches se concentre presque exclusivement sur Google, qui représente plus de 465 000 citations. Perplexity, en revanche, diversifie ses sources, privilégiant MapQuest pour les fiches (plus de 364 000 citations) et TripAdvisor pour les avis (plus de 239 000 citations).
Notons également ce qui n'est pas considéré comme une citation. Gemini, par exemple, utilise les informations de la fiche d'établissement Google dans ses réponses, mais ne les cite pas comme source, car il s'agit de données propriétaires.
Ces nuances comportementales montrent qu'une marque visible dans un modèle ne le sera pas nécessairement dans un autre : un sujet qui sera exploré plus en détail dans les analyses suivantes.
Différences par secteur d'activité
Comme dans nos précédentes conclusions concernant les fiches d'établissement Google, les citations par secteur d'activité révèlent des comportements distincts.
Il serait erroné de présumer que les modèles d'IA se comportent de manière homogène d'un secteur à l'autre. Nous avons constaté une combinaison caractéristique de sources de citation pour chaque secteur. La combinaison de sites détenus par la marque (catégorie 1) et de sources tierces (catégories 3 et 4) détermine finalement le degré de contrôle d'une entreprise sur son récit dans les résultats générés par l'IA.
(Remarque : des rapports détaillés pour les secteurs de la finance, de la restauration, de la santé et de retail seront publiés séparément.)
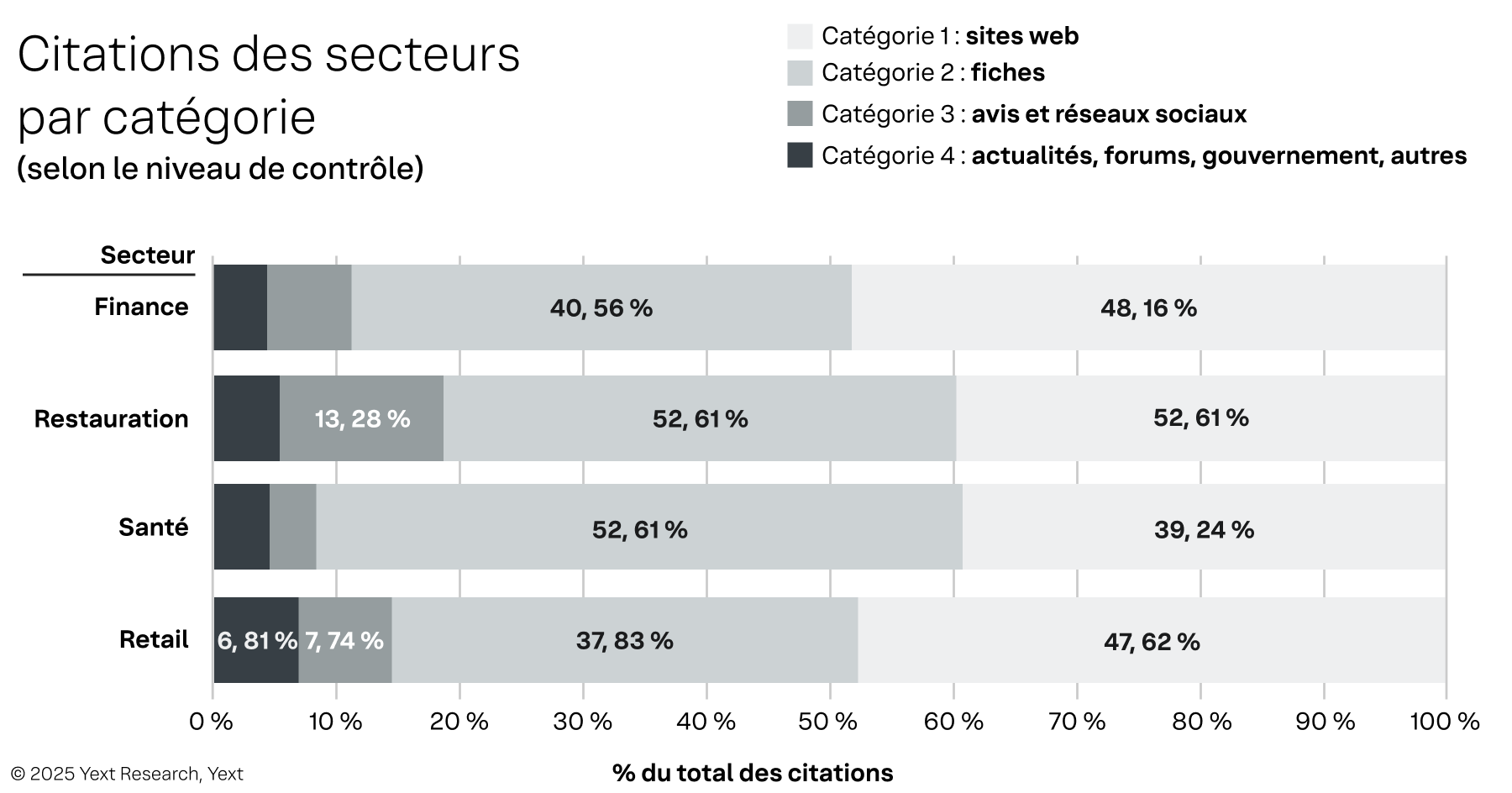 Figure 4
Figure 4
Différences notables selon le secteur d'activité :
- Les services financiers et le retail affichent le plus fort potentiel de contrôle de première main. Pour ces domaines, les sites web (catégorie 1) représentent respectivement 48,16 % et 47,62 % de leurs citations. La nature réglementée de la finance et l'infrastructure e-commerce du retail orientent les modèles d'IA vers des sources faisant autorité détenues par la marque.
- Le secteur de la santé est celui qui fait le plus appel à la validation par les tiers : les fiches (catégorie 2) représentent ainsi 52,61 % de l'ensemble des citations. Cela témoigne de l'importance des annuaires médicaux, des bases de données d'habilitations et des plateformes d'assurance dans l'établissement de la confiance.
- Le secteur de la restauration se distingue par une forte dépendance aux fiches (41,63 %) et aux avis (13,28 %). Le pourcentage de citations provenant de sources de catégorie 3 (13,28 %) est le plus élevé de tous les secteurs, preuve que pour les marques de restauration, la réputation et le contenu généré par les utilisateurs sont des facteurs essentiels à la visibilité dans la recherche par IA.
Méthodologie
Cette recherche repose sur l'analyse de 6,8 millions de citations issues des réponses de recherche par IA, collectées entre le 1er juillet et le 31 août 2025. Les données proviennent d'une étude mondiale menée auprès de clients et prospects de Yext, utilisant la plateforme Yext Scout. Bien que les données proviennent d'un échantillon spécifique, la diversité des sources citées est considérable, couvrant une longue traîne de 20 820 domaines uniques.
À l'aide d'un système automatisé, environ 1,6 million de questions individuelles ont été posées à chacun des trois principaux modèles d'IA : Gemini, OpenAI et Perplexity. Les requêtes ont été conçues pour représenter quatre quadrants distincts d'intention du consommateur (objective avec marque, subjective avec marque, objective sans marque et subjective sans marque) et ont été testées dans chaque emplacement de client et de prospect dans quatre secteurs clés : Finance, Alimentation, Santé et Retail. Ces données ont été recueillies à l'aide des API fournies par chaque modèle.
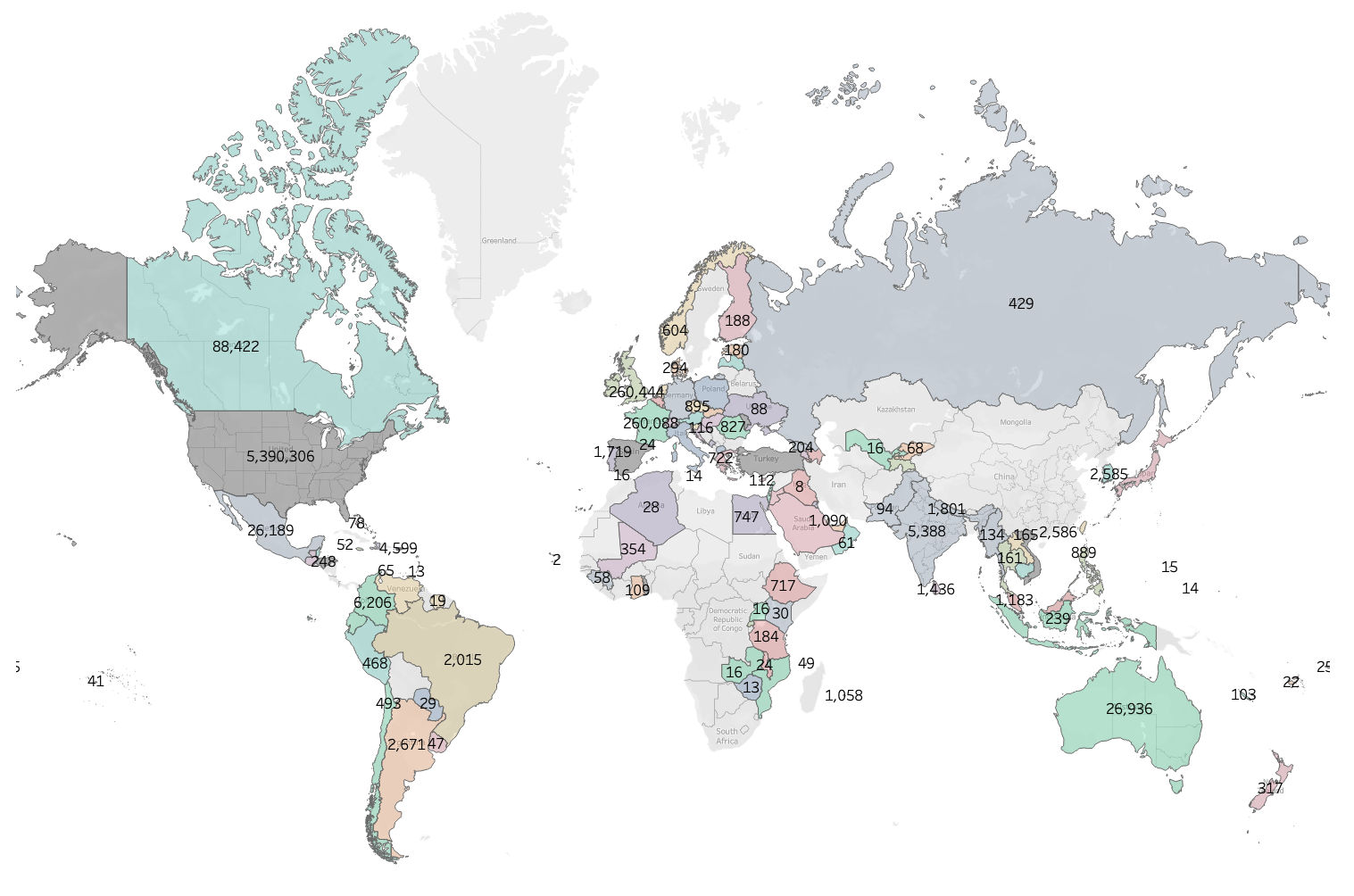
Figure 5 : Cette étude a recueilli 6,8 millions de citations à l'échelle mondiale.
L'impact de la géolocalisation sur la recherche par IA
Les trois modèles analysés confirment qu'ils prennent en compte la localisation du consommateur dans leurs réponses sur les entreprises et services. Cela ne semble toutefois pas constituer le cœur de leur logique de pertinence. Tout comme un moteur de recherche classique affiche par défaut les restaurants à proximité lorsque vous tapez « pizza », les modèles d'IA actuels utilisent les signaux de géolocalisation pour ancrer leurs réponses dans l'espace physique. Que ces signaux proviennent de l'adresse IP, des paramètres de l'appareil ou d'une requête explicite, la localisation semble constituer un facteur de pondération dans le calcul du modèle pour déterminer ce qui constitue une réponse utile.
L'effet est subtil, mais significatif. Deux personnes posant la même question dans des lieux différents peuvent recevoir des réponses différentes, façonnées par les données locales des entreprises, la couverture des services, voire les particularités linguistiques régionales. La recherche à l'ère de l’IA n'est plus un processus abstrait, mais un dialogue contextualisé entre l'utilisateur et son environnement local. La recherche alimentée par l'IA est désormais indissociable de la localisation de l'utilisateur et du graphe de connaissances locales qui l'entoure.
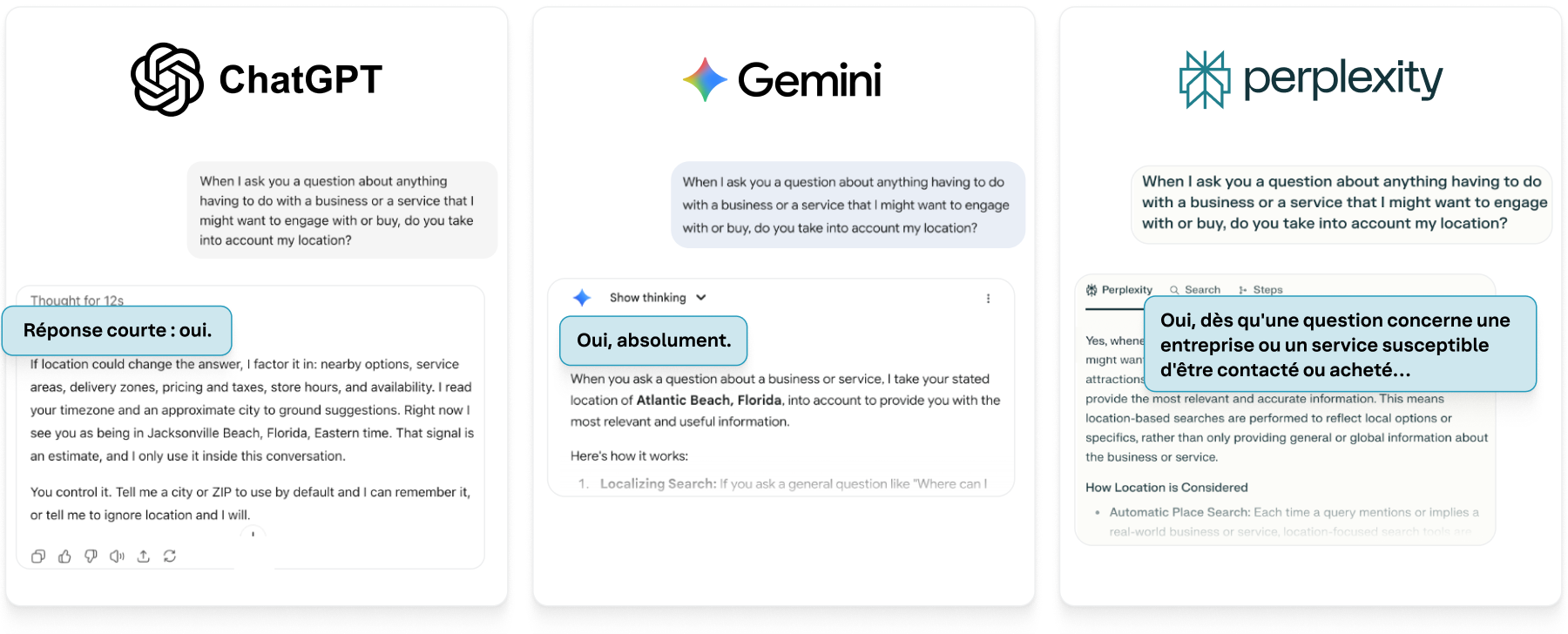 Figure 6 : Les trois principaux modèles d'IA prennent tous en compte la localisation dans leur processus de RAG.
Figure 6 : Les trois principaux modèles d'IA prennent tous en compte la localisation dans leur processus de RAG.
Classification des requêtes par intention
Nous avons créé une approche structurée pour déterminer les types de requêtes en fonction de l'intention de la requête. Le cadre de classification des requêtes (QCF) regroupe quatre quadrants correspondant aux principaux comportements des consommateurs et donnent lieu à des modèles de citation différents. Les requêtes objectives impliquent la recherche d'informations factuelles, comme « [Restaurant thaï] près de chez moi ». Les requêtes subjectives impliquent la recherche d'avis, comme « Quels sont les 10 meilleurs [restaurants thaï] près de [localisation] ? » Ce cadre permet une analyse plus précise de la manière dont les modèles d'IA répondent aux besoins réels des consommateurs.
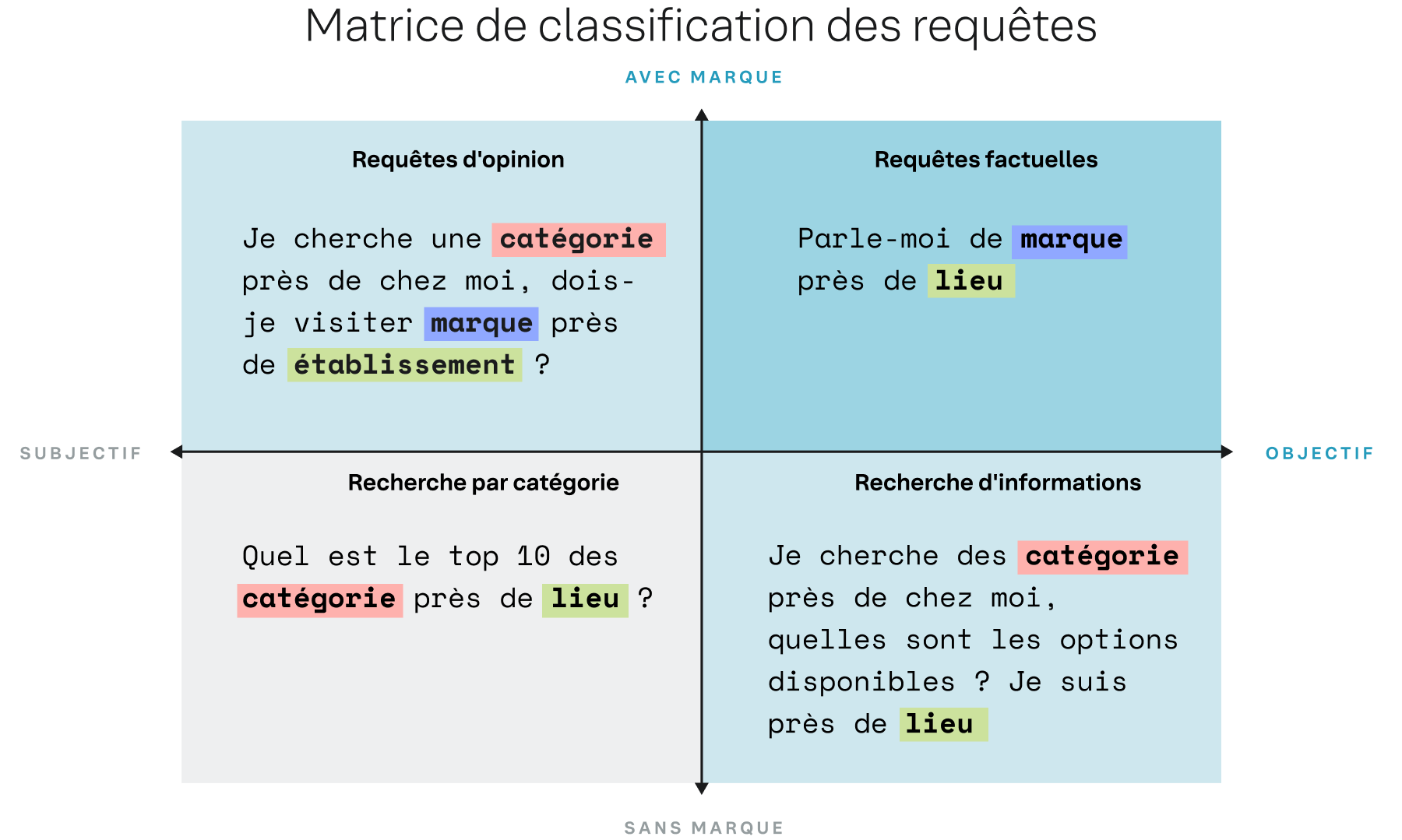 Figure 7
Figure 7
Comme le montre la figure, les citations suivies selon les types de requêtes sont globalement réparties de manière équilibrée, bien qu'il existe d'importantes variations sectorielles. La conception de ce cadre permet à l'analyse de dépasser la simple vision agrégée. En suivant les résultats de chaque type de question, modèle par modèle, cette recherche identifie avec précision les sources de citation privilégiées par chaque modèle d'IA, en fonction de la localisation du consommateur, de sa requête spécifique et du contexte sectoriel.
En appliquant le cadre de contrôle des requêtes à notre ensemble de requêtes/citations, nous obtenons une distribution globalement équilibrée, avec toutefois des différences notables entre industries pour les questions « objectives ».
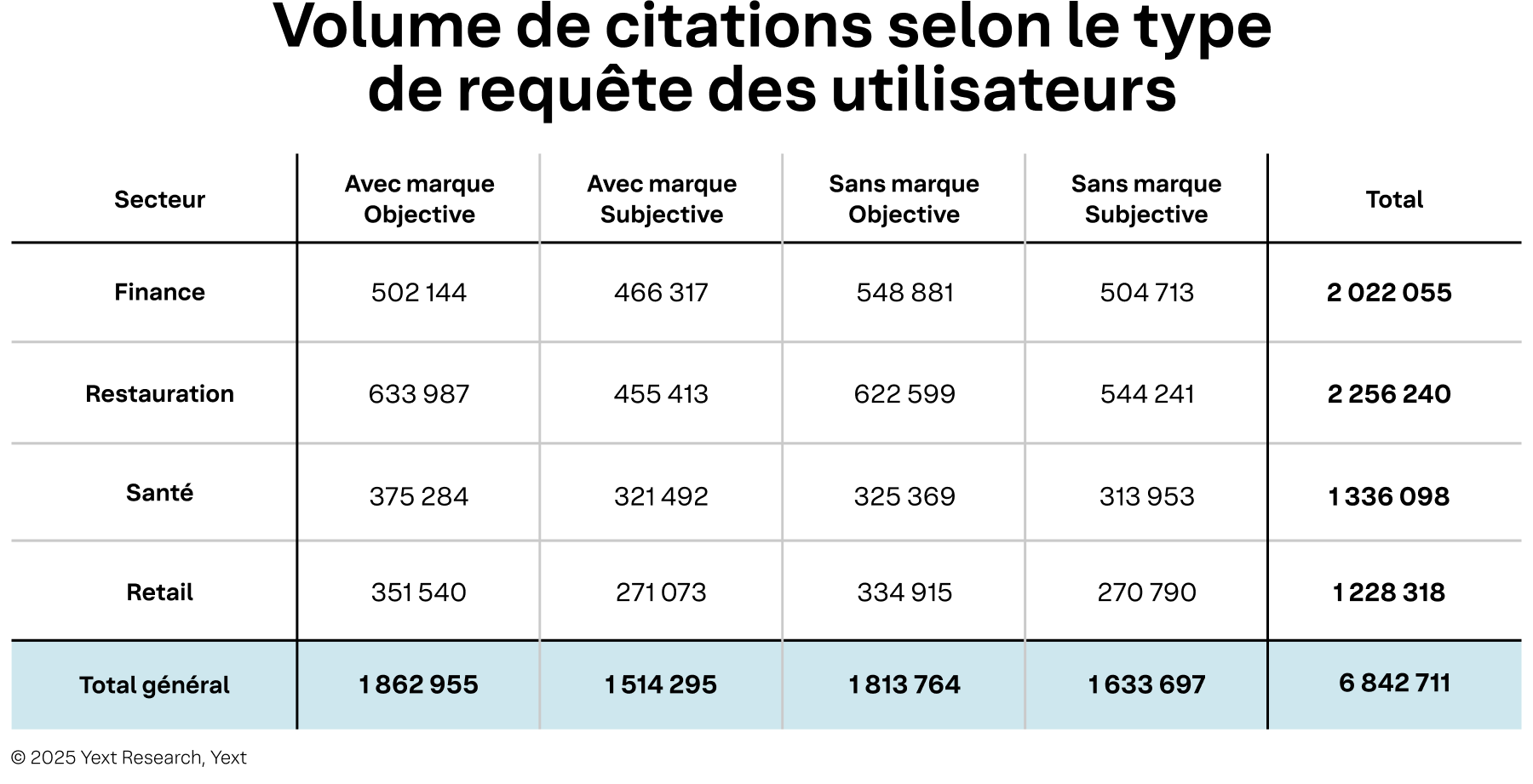 Tableau 3
Tableau 3
Limites et pistes de recherche futures
Cette analyse est basée sur les données des clients et prospects de Yext, et couvre plus de 200 000 emplacements où ils sont actifs ou pourraient l'être. La plateforme Yext Scout importe directement toutes les citations disponibles depuis les API des différents modèles d'IA. En parallèle, il est important de reconnaître les différences entre les citations renvoyées par une API et celles présentées dans une application utilisateur directe. En raison de la nature probabiliste des grands modèles de langage, le contexte conversationnel d'un individu, l'utilisation spécifique d'un modèle et sa mémoire conversationnelle peuvent tous affecter les réponses. Par conséquent, des variations substantielles peuvent être observées d'un utilisateur à l'autre. Cependant, l'analyse de milliers d'invites contextuelles pour les marques et les entreprises montre que les modèles de sources de citation qui en résultent sont probablement révélateurs de modèles d'utilisation généraux dans un lieu particulier.
Pistes de recherche futures
Les conclusions de ce rapport ouvrent plusieurs voies de recherche plus fines. Les prochaines analyses incluront :
- Explorations approfondies par modèle : une décomposition détaillée des schémas de citation pour chaque modèle d'IA, développant les différences de haut niveau identifiées dans ce rapport, à publier dans des sous-rapports ultérieurs.
- Sous-rapports sectoriels : une analyse des domaines et sources de citation les plus fréquents dans les secteurs individuels de la finance, de la restauration, de la santé et du retail.
- Analyse des variations géographiques : une analyse quantitative des différences de schémas de citation selon les types de marchés géographiques (centres urbains denses et zones rurales) viendra approfondir les observations initiales de cette étude.
- Suivi longitudinal : suivi continu des sources de citations afin de comprendre comment les IA évoluent à mesure que leurs modèles sous-jacents sont mis à jour et réentraînés.
Conclusion
Les conclusions de cette recherche établissent une nouvelle perspective sur la visibilité dans la recherche par IA. Une analyse limitée au niveau de la marque ne suffit plus à saisir la complexité des comportements de recherche actuels. Pour comprendre réellement la visibilité dans la recherche par IA, il faut partir du terrain : agréger des données locales fines qui reflètent le contexte et les besoins réels des consommateurs.
Cette approche fondée sur la localisation dessine une feuille de route claire pour l'avenir. Alors que les analyses classiques au niveau de la marque mettent souvent en avant une multitude de sources non contrôlées, cette étude montre que, pour des requêtes précises de consommateurs, les modèles d'IA s’appuient sur un ensemble d'informations plus structuré. Les marques peuvent contrôler ou influencer directement la grande majorité de ces sources. La stratégie la plus efficace repose sur une gestion proactive et structurée des sites web propriétaires, des annuaires tiers et de la réputation en ligne d'une marque.
Cette étude, basée sur deux mois de données provenant de clients et prospects de la plateforme Yext Scout, marque une première étape d'un programme de recherche continu.
Alors que les modèles d'IA évoluent, cette méthode d'analyse par localisation offre une approche durable et centrée sur le client pour évaluer la performance des marques dans la recherche par IA.