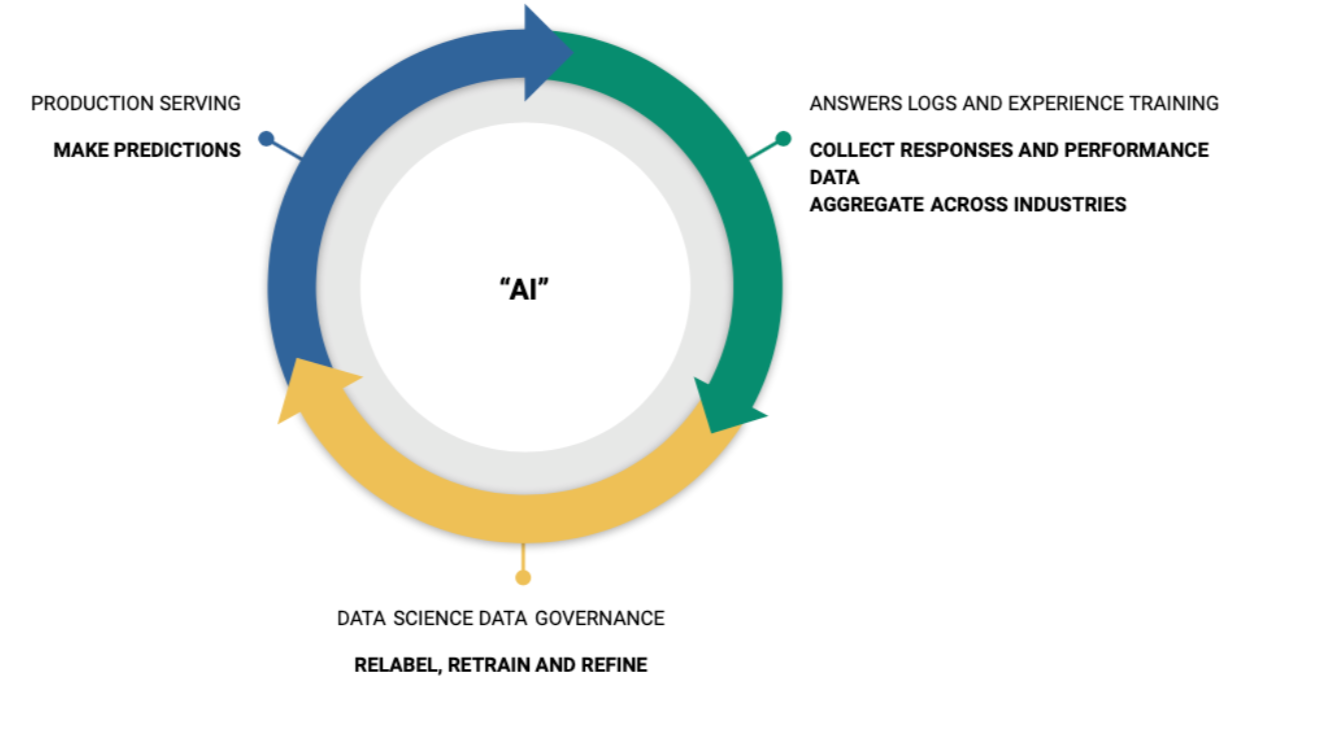
Building a great algorithmically-driven product requires a lot of data. You can (and almost certainly must) get some of this data via human labeling, but a great way to really make huge improvements on your algorithms is to get them out in the wild, and measure where they were wrong, so they can be retrained!
The best algorithmic product companies all do this at a large scale:
Google knows every search engine result page (SERP) served to every user in response to every query, and they know what position link (or widget, or card, or product, or map pin, etc.) is clicked (or not).
Google also knows every time they show you an ad in Gmail (or around the web, due to their DoubleClick ad network), and whether or not you clicked on it.
Continuing with Google, reCAPTCHA is another great example. Originally Google used billions of hours of human attention to train their optical character recognition algorithm, and have you noticed how many of the pictures now involve traffic lights and sidewalks?
Social media companies such as Facebook (both on the big blue app and Instagram) and Twitter can roll out new algorithms for recommending content for your newsfeed, and measure which interactions you have with it.
Product recommending companies like Amazon and StichFix can deploy new recommeandation models, and measure whether you purchase or return the item.
Netflix is well known for enormous investments in recommender systems, they can measure clicks and watch time (are you still watching?).
The more you look, the more you see these cycles in many products all around you, especially the ones that seem to have the most magical or impressive algorithmic features. Further, if you look at many of the algorithms underpinning many popular machine learning models, you'll also see this same pattern repeat everywhere. Random forests, gradient boosted trees, neural network optimizers, and reinforcement learning all use this fundamental concept.